Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、 の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・単語の類似性について
・発話の特徴を知る
単語の類似性
発話データの内容を形態素分析
・今回は、コーパスの発話データに対して、「単語の類似性」から「発話の特徴」を学習する__ということを行っていく。そのために、まずは「単語の類似性」__を取得しなければならない。
・この項では、「単語の類似性」を取得する前処理を行っていく。具体的には、フラグが「O」、すなわち発話データのうち、__自然な発話のみを形態素解析__する。
・手順
①「自然言語処理1 分析データの抽出」で作成した「df_label_text」のうち、フラグが「O」のもののみ抽出する。(df_label_text_O)
②抽出したdf_label_text_O(NumPy配列)を「.tolist()」でPythonのリストに変換し、それを一行ずつ__re.sub()で数字、アルファベットを除去__。(reg_row)
③reg_rowを__Janomeで形態素解析する__。このうち、表層系(単語)だけを「morpO」というリストに追加する。
・コード
単語文書行列
・__単語文書行列__とは、単語データを数値データに変換する手法の一つである。
・これは、__文書に出現する単語の頻度を数値化したもの__である。この単語文書行列を実行するために、形態素解析で文書を単語ごとに分けるということを行っていた。
・実行には、scikit-learnの__CountVectorizer()__を使う。
・デフォルトだと2文字以上でないと単語として認識されないが、日本語の場合1文字でも意味をなす単語は存在するので、このような時は上記引数に「token_pattern='(?u)\b\w+\b'」と入力する。
・CountVectorizer()オブジェクト(CV)に対して、__CV.fit_transform('単語文書行列にする文字列')__というふうにすると単語の出現回数を配列にすることができる。
・以下のコードでは、前項の「morpO」を単語文書行列に変換し、さらにこれをndarray配列に変換し、DataFrameで表している。
※__「get_feature_names()」__で、学習した単語が配列になって格納される。
・コードの出力結果(一部のみ)
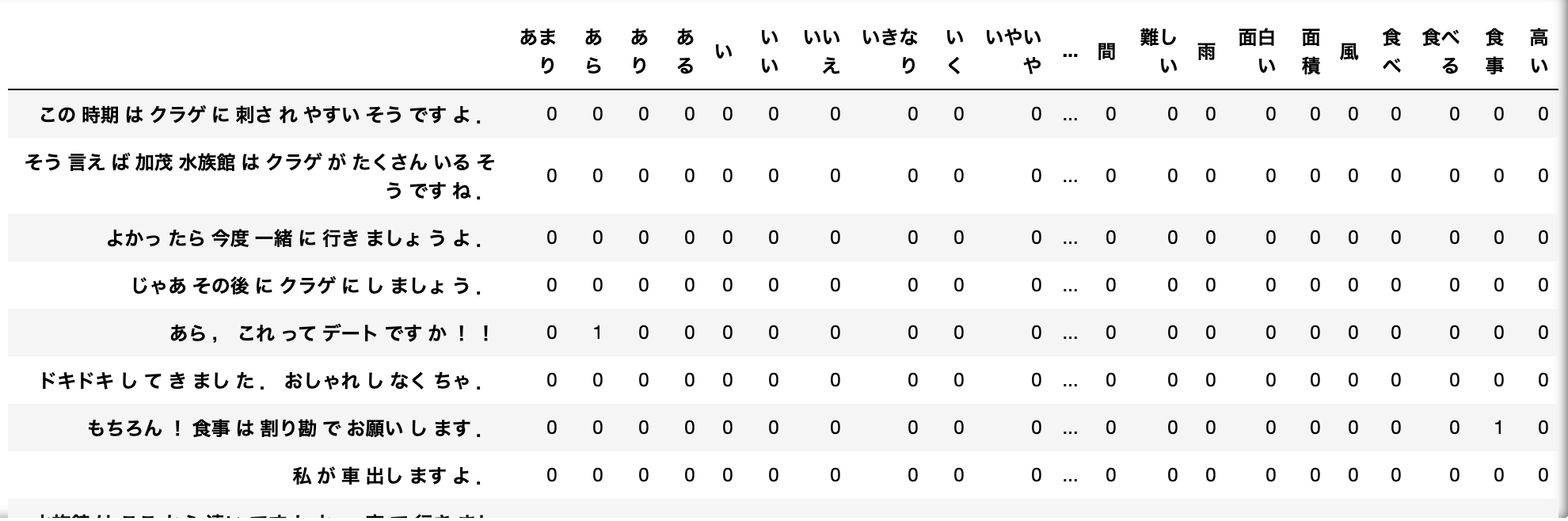
重みあり単語文書行列
・以上の単語文書行列では、__「私」や「です」などの普遍的な単語の出現頻度がどうしても多くなってしまう。このままだと、特定の文書にのみ出現する単語が重要視されず、適切に「発話の特徴」を抽出できない。
・このような場合に、「どの文書でも出てくるような普遍的な単語の重みを小さくし、特定の文書にのみ出てくる単語の重みを大きくする」といった手法を用いて単語文書行列を作ることが多くあり、これを「重みあり単語文書行列」という。
・この時の重みを決定づける値は、単語の出現頻度(TF)にIDFという値をかけた「TF-IDF」__が利用される。
・IDFは総文書数とその単語の出現する文書数の比によって算出され、__出現する文書数が少ないほどIDFの値が大きくなる。__すなわち、重み(TF-IDF)が大きくなる。
・重みあり単語文書行列の実行は以下のように行う。
TfidfVectorizer(use_idf=)
・「use_idf」にはTrueorFalseを指定し__「重み付けにidfを使うかどうか」を指定する。
・また、CountVectorizer()と同様に、1文字でも単語として扱いたい時は「token_pattern」__を指定する。
・あとはCountVectorizer()と同じように__「fit_transform()」__で単語の出現回数を配列にすることができる。
単語の類似度を計算
・今回は__単語の出現の仕方の類似度を特徴量とした教師なしモデル__を作成する。
・単語の類似度を計算する方法はベクトル同士の類似度であるコサイン類似度など様々なものが存在するが、今回は各列間の__相関係数__を計算することで類似度を測る。
・相関係数を計算するには、__DataFrame.corr()__メソッドを使う。このために、先述のコードではDataFrameに変換していた。
発話の特徴を分析する
類似度リストの作成
・前項で算出した__相関係数が特徴量となる__ので、これを使って定量的に分析していく。
・まずは相関係数を行列形式からリスト形式に変換する。これには、__DataFrame.stack()__メソッドを使う。(stack()は列から行、unstack()は行から列に変換)
・以下のコードの手順
①__重み単語文書行列を作成__した上で、その__相関係数を計算した行列を作成__したとして(corr_matrixO)、それを__リスト形式に変換__する。(corr_stackO)
②このうち、__正の相関がある(類似していると言える)組を抽出する__ため、相関係数が「0.5~1.0」であるindex(単語の組)とvalue(相関係数の値)を抽出し、連結して表示。
・実行結果(一部のみ)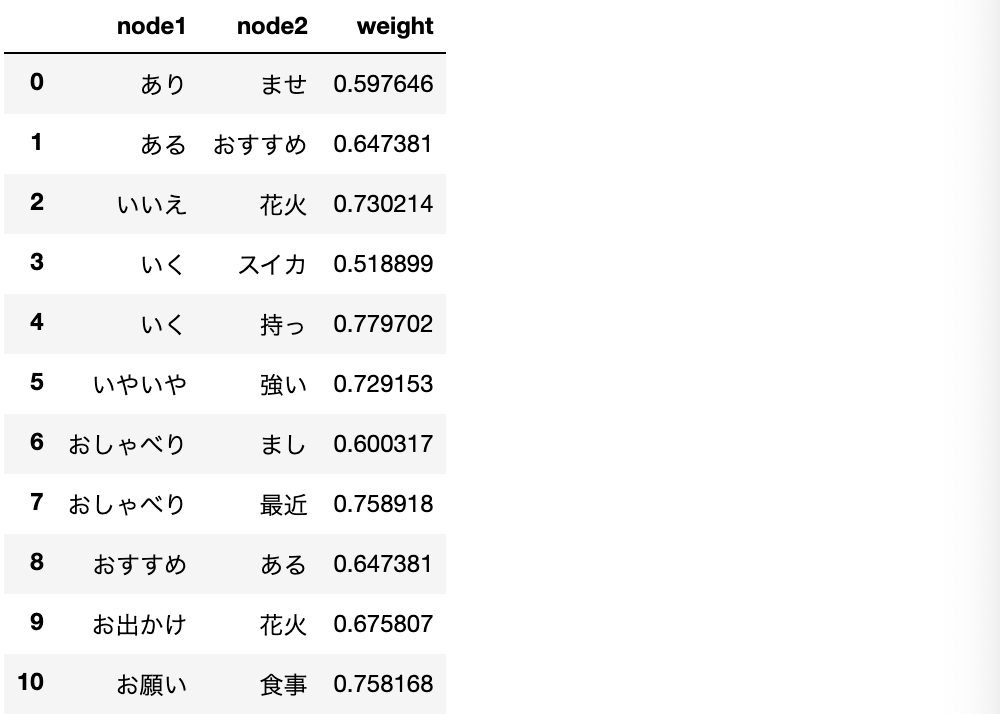
類似度ネットワークの作成
・類似度ネットワーク__とは、平たく言えば類似度の関係をグラフ化して可視化したものである。
・前項で作成した類似度リストを可視化する時は「無向グラフ(無向ネットワーク)」というものを使う。
・無向のグラフの作成は__NetworkX__と呼ばれるライブラリを使う。これを「nx」__でインポートしたとすると、
nx.from_pandas_edgelist(df,source,target,edge_attr,create_using)
で作成することができる。
・各引数について
df:グラフの元となるDataFrame
source:相関の一方(ソースノード)の列名
target:相関のもう一方(対象ノード)の列名
edge_attr:それぞれのデータの重み(エッジ)
create_using:グラフのタイプ(無向ならnx.Graph)
・作成したグラフは、__pos = nx.spling_layout(グラフ)__で最適な表示位置を計算し、__nx.draw_networkx(グラフ,pos)__で描画、あとはplt.show()で表示できる。
・前項で作成した「df_corlistO」をグラフにする。

・グラフ

類似度ネットワークの特徴
・グラフを出力することはできたが、上記のグラフでは__一見して特徴を把握するのは難しい__。
・そのため、新しく指標を設けて__定量的に判断していく。
・このときに使われる指標は様々あるが、ここでは詳しくは説明しない。今回使う指標は「平均クラスタ係数」と「媒介中心性」__と呼ばれるものである。
・クラスタ係数は__単語間の繋がりの密度__を示し、この平均が高ければ、ネットワーク全体も密になっていると言える。媒介中心性は__一つの「ノード(相関の組の一方)」が全てのノード間の最短経路に幾つ含まれるかを示す値__であり、値が大きいほど情報を効率的に伝える際に利用されることが多い、すなわち媒介性と中心性の高いノードであると言える。
・平均クラスタ係数の計算は以下のように行う。
nx.average_clustering(グラフ,weight=None)
・weightには重み(エッジ)を指定する。Noneだと各エッジの重みは1になる。
・媒介中心性の計算は以下のように行う。
nx.betweenness_centrality(グラフ,weight=None)
・コード
類似度ネットワークのトピックを抽出
・類似度ネットワーク全体は、複数の部分ネットワーク(コミュニティ)が集まってできている。
・この時のコミュニティの__各ノードは密になっている__ため、コミュニティを抽出するということは__類似度の高いネットワークを抽出するということになる__。
・部分ネットワークに分割するには、__「モジュラリティ」__と呼ばれる指標を使う。細かい計算式は省略する。
・モジュラリティを用いたコミュニティの抽出は以下のように行う。
greedy_modularity_communities(グラフ,weight=None)

まとめ
・単語文書行列に変換することで、単語データを数値データに変換することができる。多くの場合、重みありで行われる。
・数値データに変換したことで、各データの相関係数を求めることができる。これにより、単語同士の類似度を算出できる。
・この類似度をリスト化し、ネットワークを作ることで可視化が可能になり、これにモジュラリティという指標を使うことでトピック抽出ができ、これによって類似度の高いネットワークが抽出できる。
今回は以上です。最後まで読んでいただき、ありがとうございました。