Aidemy 2020/11/22
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、深層強化学習の3つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・
ブロック崩しによる強化学習実践
環境の作成
・Chapter2と同じ方法__(gym.make())で環境を作成する。ブロック崩しの場合、引数には「BreakoutDeterministic-v4」を指定する。
・行動数は「env.action_space.n」__で確認できる。
・コード
モデルの構築
・ここでは多層ニューラルネットワークを構築する。入力は__「ブロック崩しの画面4フレーム分」__とする。また、計算量を少なくするために、画像は__グレースケールの84×84画素__にリサイズする。
・モデルはSequential()を使用する。Chapter2と同様に__Flatten()で入力を平滑化し、全結合層はDense、活性化関数はActivationで追加する。
・今回は画像(二次元)の入力なので、二次元の畳み込み層である「Convolution2D()」を使用する。第一引数は「filter」で、出力空間の__次元数__を指定し、第二引数は「kernel_size」で、畳み込んだ__ウィンドウの幅と高さ__を指定する。「strides」__は歩幅、つまり__ウィンドウの一度に動く幅と高さ__を指定する。
・コード

履歴と方策の設定
・ここもChapter2と同様に、エージェントの作成に必要な__履歴__と__方策__を設定する。
・履歴は__「SequentialMemory()」を使う。引数には__limit__と__window_length__を指定する。
・方策は、ボルツマン方策をとる場合は「BoltzmannQPolicy()」、ε-greedy手法をとる場合は「EpsGreedyQPolicy()」を使う。
・また、パラメータεを__線形__に変化させるときは、「LinearAnnealedPolicy()」__を使用する。引数は、以下のコードのように指定すると、トレーニングの際にパラメータεを10ステップで最大1.0最小0.1の線形に変形し、テストの時は0.05で固定するという意味を表す。
・コード

エージェントの設定
・エージェントは__「DQNAgent()」の引数にmodel,memory,policy,nb_actions,nb_steps_warmupを渡すことで作成できる。あとは「dqn.compile()」__で学習方法を指定すれば良い。第一引数には__最適化アルゴリズム__を指定し、第二引数には__評価関数__を指定する。
・コード
学習の実施
・前項の設定まで終わったら、次にDQNアルゴリズムを使って学習を行う。__「dqn.fit()」で行い、第一引数には環境、第二引数には「nb_steps」で何ステップ学習するかを指定する。
・また、学習結果は「dqn.save_weights()」__でhdf5の形式で保存できる。第一引数にはファイル名、第二引数には「overwrite」で上書き可能にするかを指定する。
・コード

テストの実施
・学習させたエージェントでテストを行う。__「dqn.test()」__で行う。引数はfitと同じで、ステップ数nb_stepsの代わりにエピソード数「nb_episodes」を指定する。
・ちなみに、今回のブロック崩しでは、ボールを落とすまでが1エピソードである。
Dueling DQN
Dueling DQNとは
・__Dueling DQN(DDQN)はDQNの発展版で、DQNのネットワーク層の最後を変更したものである。
・DQNでは、最初に「convolution層」が3つの後に、全結合層を経てQ値を出力していたが、DDQNはこの__全結合層を2つにわけ、一方では__状態価値V__を出力し、もう一方では__行動A__を出力する。この2つを入力とした最後の全結合層からQ値を求めることで、DQNよりも性能が上がる。
・図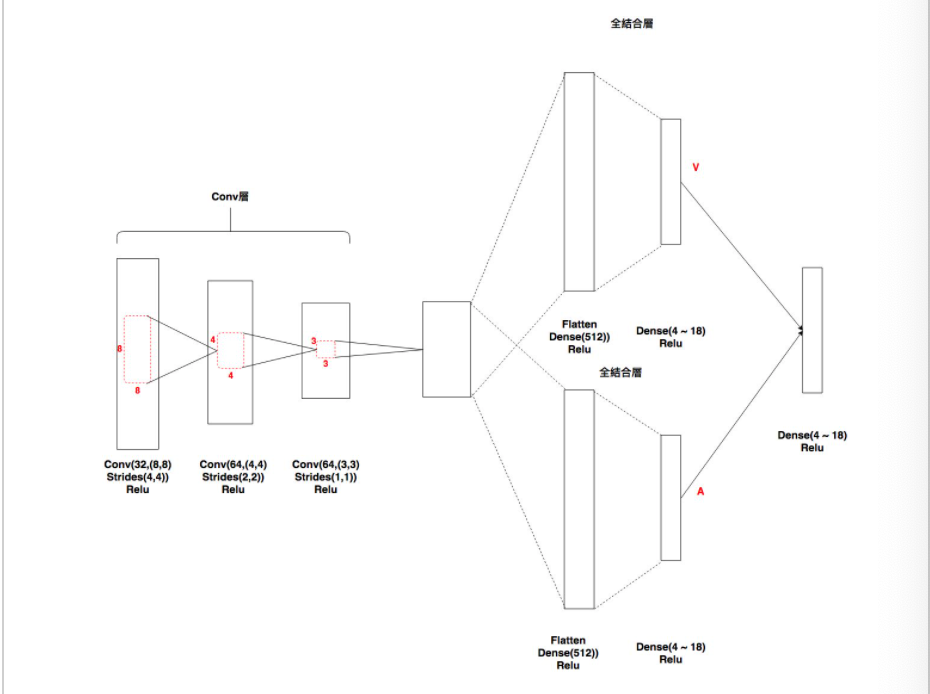
Dueling DQNの実装
・Dueling DQNの実装は、層の追加まではDQNと同じである。エージェントの設定時__(DQNAgent())に、引数で「enable_dueling_network=True」とし、Q値の求め方「dueling_type」を指定することで実装できる。dueling_typeには「'avg','max','naive'」__を指定できる。
・コード
・結果
まとめ
・ブロック崩しでも、Chapter2の時のように環境などを定義できる。
・モデルの構築については、今回は二次元の画像認識であるので、畳み込みを使用する。__「Convolution2D」層を使用する。
・今回の方策ではε-greedy手法を使うのだが、パラメータεは線形に変化させる必要がある。このような時は、「LinearAnnealedPolicy()」を使って__線形に変化__させる。
・学習まで行ったモデルは「dqn.save_weights()」__を使うことでhdf5の形式で保存できる。
・DuelingDQN__は__全結合を2つに分け、それぞれ状態価値Vと行動Aを算出し、最後の層で、その二つからQ値を求めるDQNである。実装は__DQNAgent()に「enable_dueling_network」と「dueling_type」__を指定すれば良い。