Aidemy 2020/12/3
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、レコメンデーション入門の3つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・レコメンドの評価方法
レコメンドの評価方法
評価方法の分類
・レコメンドの__評価__は__「対象者にとって本当に欲しいもの」であるかどうか__の観点から行われる。これを評価する指標は多く存在し、それぞれ異なる軸での長所・短所があるため、レコメンドの目的に応じて決定する必要がある。
・評価方法には大きく分けて__「オフライン評価」と「オンライン評価」__の二つがある。
オフライン評価
・__オフライン評価__とは、利用者の行動履歴のみを使ってレコメンドを評価する方法__である。これは__利用者の利用データのみを使用する__ため、利用者と実際に関わる必要がなく、この点にコストがかからない。しかし、この手法では「レコメンドされて買った商品」については__正確に評価できない。評価する時点で既に購入されており、レコメンドをしたかどうかで購入の有無が変わるかを評価できないためである。
・オフライン評価の流れは次のようになる。
①行動履歴を学習データとテストデータに分ける
②学習データについてレコメンドを行う
③レコメンド内容とテストデータを比較して精度を算出する
オンライン評価
・一方__オンライン評価__とは、実サービスに導入し、利用者の反応を見る__ことでレコメンドの評価を行う方法である。これは、実サービスと同じ環境で評価できるので、意味のあるデータであると見なすことができる。ただし、利用者に直接利用してもらうため、コストやリスクが大きくなる。
・オンライン評価の一例として「A/Bテストアルゴリズム」と言うものがある。流れは以下の通り。
①対象の利用者を__2つのグループに分ける
②それぞれのグループに「既存のレコメンドシステム」と「新しいレコメンドシステム」を採用する
③結果を比較してレコメンドを評価する
予測の評価指標
・商品に対する評価が星1〜星5で表されるように、__「レーティング」されているとき、このレーティングを予測し、実際の値と比較することで__評価を行う__ことができる。
・レーティング予測の指標には「平均絶対誤差」と「標準偏差」__の二つがある。
平均絶対誤差
・__平均絶対誤差(MAE)は、予測値と実数値の__差に絶対値をつけて平均を取ったもの__である。簡単で理解しやすい反面、実際に使用されることは少ない。式で表すと以下のようになる。
$$\frac{1}{n}\sum^n|x{予想値} - x{実測値}| $$
標準偏差
・__標準偏差(RMSE)は予測値と実数値の差を2乗を平均して平方根をとったものである。予測の評価指標としては__最も一般的なもの__である。式は以下のようになる。
$$\sqrt{\frac{1}{n}\sum(x{予測値} - x{実測値})^2}$$
・標準偏差の計算例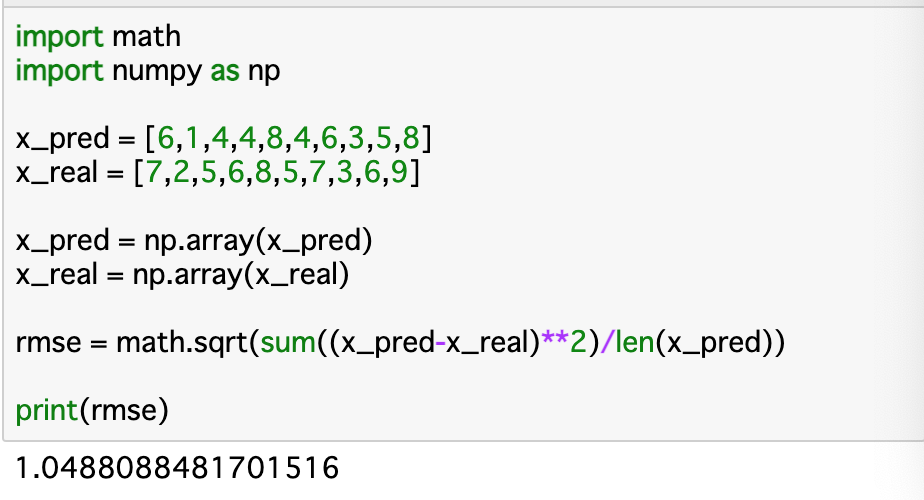
分類の評価指標
・履歴から、__「カートに入れたかどうか」「購入したかどうか」などについて予測する指標について考える。前項では値を予測する回帰問題であったが、この場合は__二値分類__となる。分類問題の時の評価指標は「適合率」「再現率」「F1値」__の3つがある。
(含復習)適合率
・__適合率(precision)は、対象者が「購入する」と予測したもののうち、「実際に購入した割合」__である。0〜1の値を取り、1に近いほど精度が高いと言える。しかし、そもそも「購入すると予測した数」が少ないときは正しく制度を測れない。例えば100個の商品のうち、30個が購入されたとする。この時5個購入したと予測し、参照した5個全てが購入されていたとしたら、適合率は1となり、ものすごく精度がいいと判断されてしまう。よって、適合率を使う場合は他の評価指標も利用する必要がある。
再現率
・__再現率(recall)とは、対象者が「実際に購入したもの」のうち、「購入したと予測できた割合」__である。こちらも1に近いほどいいモデルであると言える。また、適合率と同じで、予測の個数を増やし、たまたま予測できた場合に精度が非常に良いと判断されてしまう欠点がある。
F1値
・トレードオフの関係にある適合率と再現率をバランスよく評価するために、__それぞれの調和平均を取ったもの__が__F値__である。調和平均とは$ \frac{2ab}{a+b} $で表される平均のことである。以下ではF1値を算出している。
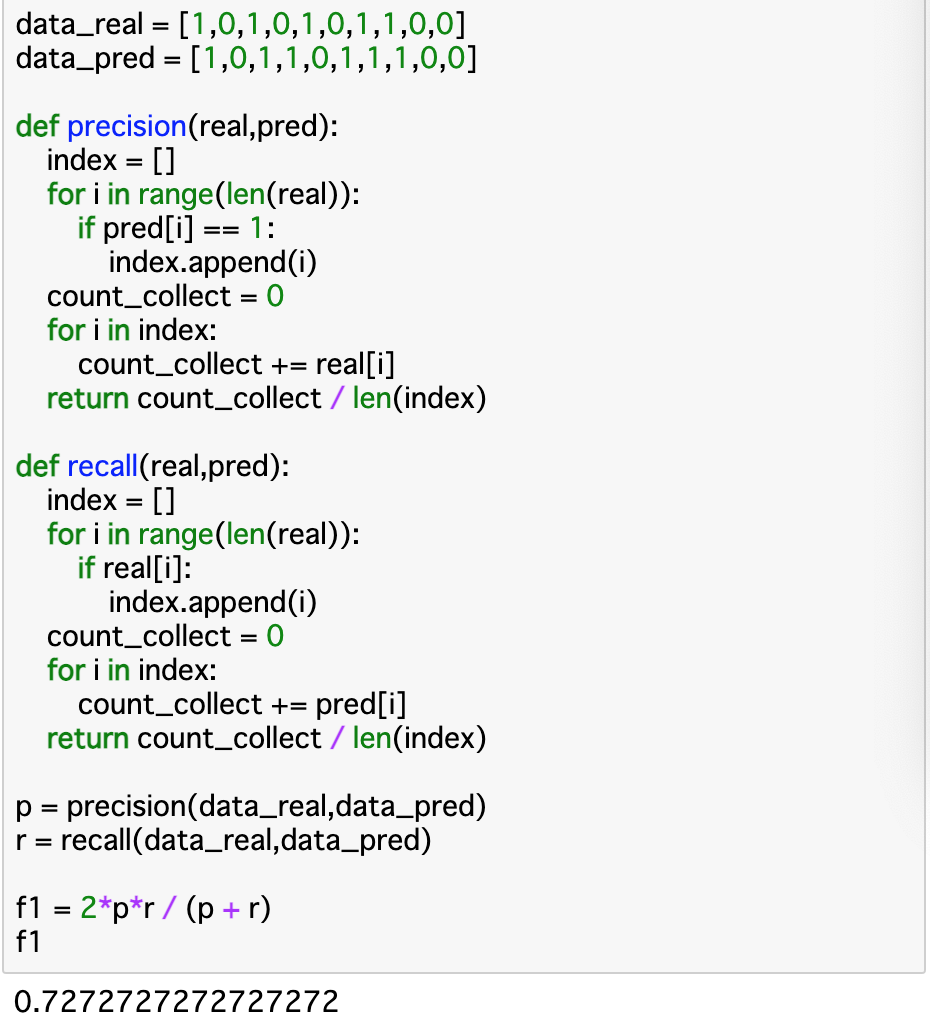
・__precision()について、それぞれの予測データ(pred[i])を参照し、「1」ならindexに格納する。これにより、「購入すると予測した個数(len(index))」と「購入したと予測した番号(i)」が算出される。このindexのiに対応する正解データを参照し、count_collectに加算していく(1なら加算される)。最後に「count_collect / len(index)」__とすれば適合率が算出できる。
・__recall()について、こちらはprecision()と逆のことを行えば良い。すなわち、それぞれの正解データを参照し、「1」ならindexに格納、そのiについて予測データを参照し、1ならcount_collectに加算される事になる。
・F1値はこれらの調和平均であるため、「2*p*r / (p + r)」__のようにして算出する。
ランキングの評価指標
カバレッジ
・前項までは「精度」を指標にしてレコメンドを評価してきたが、実際にレコメンドが行われる際には、精度さえ良ければ良いと言うものでもない。例えば、レコメンドをする商品が生活必需品だったり人気商品などであれば、そもそも購入される頻度が高いことから、レコメンドの精度も上がる傾向にある。しかし、これでは__「レコメンドすべき知名度の低い商品」と比較した際に精度に偏りが生じてしまう。このような要素を考慮した評価指数を「カバレッジ」という。
・カバレッジには、「カタログカバレッジ」と「ユーザーカバレッジ」__がある。
カタログカバレッジ
・一回のレコメンドで__どれだけの商品をレコメンドできたか__を示す指標を__カタログカバレッジ__という。__「レコメンドできた商品/全商品」__で算出でき、1に近づくほど、より幅広い商品をレコメンドできたとみなせる。
ユーザーカバレッジ
・一回のレコメンドで__どれぐらい多くのユーザーにレコメンドできたか__を示す指標が__ユーザーカバレッジ__である。こちらは__「レコメンドできたユーザー/全ユーザー」__で算出でき、1に近づくほど、より多くのユーザーにレコメンドできたとみなせる。
まとめ
・Chapter1,2とこのChapterをまとめると、レコメンドはデータ同士の類似度をcos類似度やピアソン相関などで算出して、それに基づいて行われ、これを評価するときには標準偏差などが使われる。コード上でもこの流れのまま行えば良い。
・__レコメンドの評価__には__オフライン評価__と__オンライン評価__がある。オフライン評価は精度をコンピュータ上で計算するものである。オンライン評価は実際にユーザーに評価してもらうものである。
・予測の評価__指標には「平均絶対誤差」と「標準偏差」__があるが、一般的には標準偏差で算出される。
・__分類の評価__指標としては、適合率と再現率があるが、各々では穴があるので、これらを合わせた__F1値__を使う。
・ランキングの評価__指標としては「カバレッジ」というものがある。これは精度ではなく、「レコメンドされる商品の幅の広さや目新しさ」__を評価するものである。
今回は以上です。最後まで読んでいただき、ありがとうございました。