Aidemy 2020/12/8
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、ネットワーク分析の3つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・JSONファイルの扱い方
・実際のデータを使ってネットワーク分析
JSONファイル
JSONファイルとは
・Chapter3では__実際のデータを使ってネットワーク分析を行う。pythonで実際のデータを取得する方法の一つとして、「JSONファイルを読み込む」ということがある。
・JSONファイルを読み込むには、「open()」関数を使ってファイルを開き、「load()」__関数を使う必要がある。こうすることで、python上では__辞書型のオブジェクト__として扱うことができるようになる。
・以下では、人間データが入ったjsonファイルについて、年齢をkey、__名前をvalue__とした辞書に再格納するものである。
・コード
実際のデータを使ってネットワーク分析
データの読み込みと整理
・ここでは、A__社の社内SNSの記録__をまとめたデータ__「sample_data.json」を使って、このファイルの読み込み、整理を行なっていく。具体的に、このデータには「A氏の番号:{B氏の番号:値,C氏の番号...}」と格納されている。例えば「"1":{"3":2}」と格納されていた場合、これは「1氏が3氏に送ったメンション数が2回である」ことを示す。
・このデータを、次項以降でグラフにしたいのであるが、この時、人を頂点、人同士の繋がりを辺__とする。このようにする場合、前処理として、「誰とも繋がりのない人」を除外しておく。読み込んだjsonファイルを「data」とすると、その各keyについて、__data[key]の長さが0であれば、誰にもメンションしていないということになるので、これを抽出し、「del」__で削除する。
・コード
データの保存
・前項で修正したデータを保存する。この場合は、__「open()」関数で「'w'」と指定して書き込み専用で呼び出す必要がある。ちなみに、この時存在しないファイル名を呼び出したときは、そのファイルが作成される。次に「json.dump()」__で、辞書型からjson型の文字列に変換する__ことで、書き込むことができる。
・json.dump()の各引数は次のようになる。「ensure_ascii」にはTrueorFalseを指定し、入力された文字列をそのまま出力するかを指定する。「indent」には数値を指定し、インデントの字数を指定する。「sort_keys」もTorFで、辞書の出力にkeyでソートするかを指定する。「separators」は(',',':')と指定することで、「keyとvalueのセットごとに「,」で区切る」「keyとvalueは「:」で区切る」__ことを指定する。
・コード
グラフの描画
・ここでは、重み付きグラフを作成する。辺の重みがメンション数となればよい。
・まずは、頂点がdataのkeyがstr型になっているので、dataを__int型に変える__。その後、この__二重辞書__の、keyの中の__key(sub_key)を指定することで、メンション数を取得できる。これを「G.add_edge()」の引数「weight」__に指定することで、重み__を指定できる。辺を結ぶ頂点については、そのkey(発信者)とsub_key(受信者)とすれば良い。
・あとは、この重みを辺の太さにして、グラフを描画する。辺の太さは「nx.draw_networkx_edges()」の引数「width」__に指定すれば良い。G.edges()で取得できる「頂点1,頂点2,重み」の3つ目の「weight」をwidthとし、それを基準に辺の太さを決定する。
・コード
・結果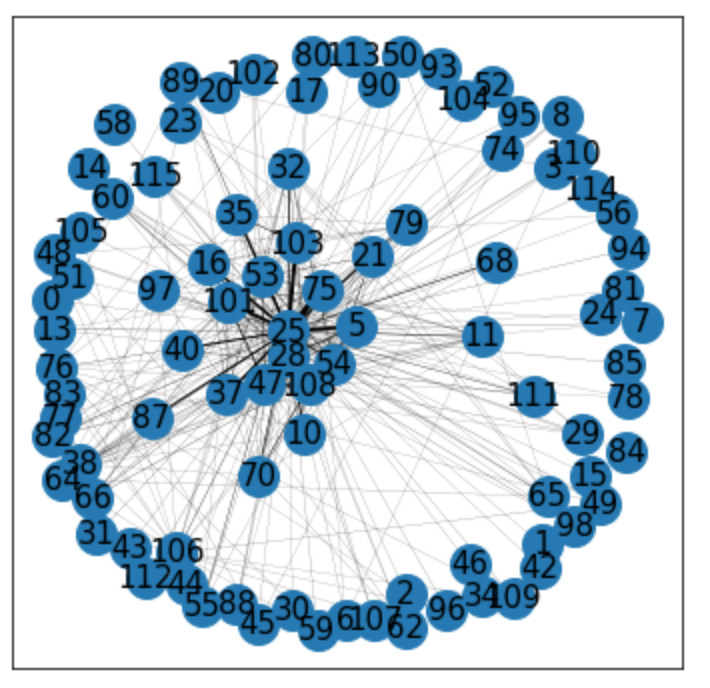
グラフの見た目を整える
・次に、頂点の大きさを、固有ベクトル中心性の大きさに応じて変化させる。固有ベクトル中心性は__「nx.eigenvector_centrality_numpy()」で算出できる。また、今回のようにedgeに「weight」という重みを与えている場合は、引数に「weight="weight"」と指定する。これを与えない場合、edgeは全て等しいものとみなされる。
・ノードの大きさは、今回は、固有ベクトル中心性「eigv_cent」の各値をリストとし、それに10000をかけたものとする。これを「nx.draw_networkx_nodes()」の引数「node_size」__に指定する。
・コード
・結果
クラスタリングを行う
・ここでは__クラスタリング__を行う。前Chapterの復習であるが、クラスタリングは連結されたグラフをいくつかのサブグラフに分けることであり、コードとしては__「community.best_partition(G)」__で行える。これにより、各頂点が__何番目のコミュニティに属しているのか__が辞書型で返される。
・上記コードについては、今までのコードに付け加えるだけで良い。また、ここでもコミュニティごとに色分けを行って描画する。コミュニティはクラスタリングを行った「partition」の、ノードごとの値を参照すれば良い。
・コード(その他の部分は前項までと同じ)
・結果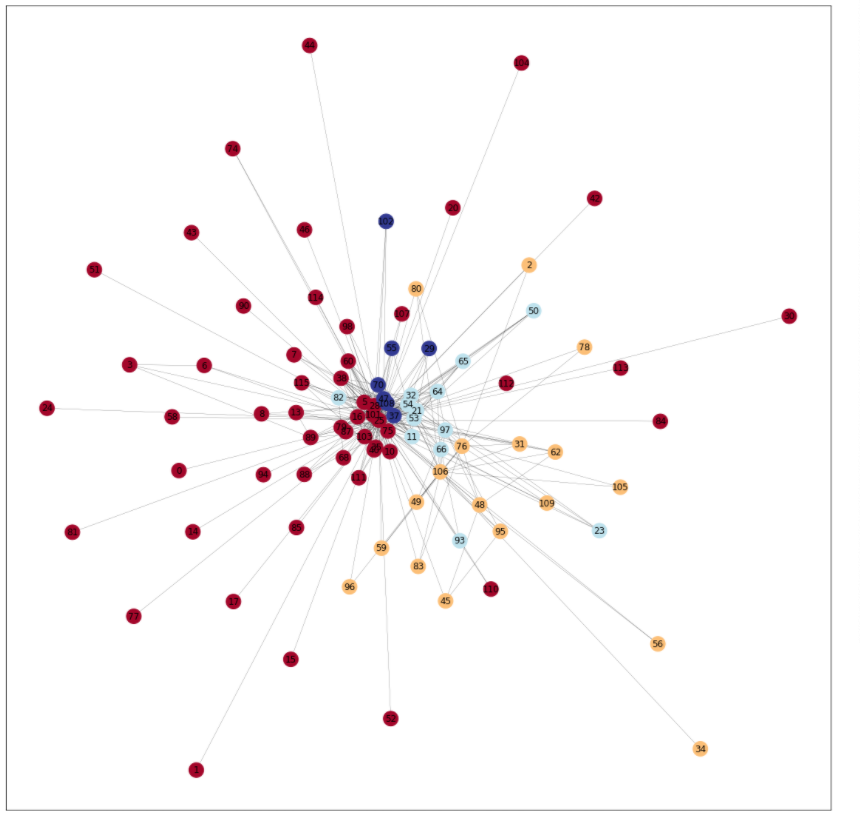
中心性が高い人物の抽出
・ここでは、各コミュニティごとに__最も固有ベクトル中心性が高い人物__を抽出する。前項の方法でpartitionを作成し、このvalue(コミュニティ)について、その番号に位置に空のリストがある、(二重)リスト「part_com」を作成する。わかりにくいがつまり__「[[コミュニティ0のnode],[コミュニティ1のnode],...]」__のようになるリストである。そして、この空のリストの中に、コミュニティごとのnode__を入れていく。nodeはpartitionのkeyに格納されているので、これを入れる。
・そして、それぞれのコミュニティのリストごとに固有ベクトル中心性の最大値の頂点を求める。まずはグラフを初期化し、新たなグラフ「G_part」を作成する。固有ベクトル中心性の算出にはnode同士の繋がりが必要であり、辺を構成する2つのnodeが同じコミュニティにあることが前提条件となるので、edgeの両端(edge[0]とedge[1])が同じコミュニティ(part)内にある場合__に、重みを含んだ辺edgeをグラフに追加する。
・そして、このグラフのnodeについて、固有ベクトル中心性をkeyとして、最大値を取得する。
・コード
コミュニティの指定とモジュラリティ指標
・前項までで扱った__「community.best_partition()」は、引数「partition」に、「キーが頂点番号で、値がコミュニティの番号」である辞書を指定すると、この辞書を参考にしてコミュニティが形成される。
・また、「community.modularity(partition,G)」で、良い分割かを表す指標「モジュラリティ指標」__を算出できる。
・以下では、コミュニティの分け方を指定しないでクラスタリングを行う「partition1」と、頂点番号が1桁のものをコミュニティ「0」、2桁のものを「1」としてコミュニティを分ける「partition2」について、それぞれのモジュラリティ指標を算出している。
・コード
まとめ
・実際のデータでネットワーク分析を行う場合も、扱うファイルが__JSONファイル__であるなどの違いを除けば、基本的にはkarateclubの時と変わらない。
・今回のJSONデータは、pythonで扱えるように読み込むと、__{A:{B:value}}のような二重辞書になっている。そのため、中の辞書のkeyは「sub_key」__として取り出すと、データを楽に扱える。また、グラフの描画についても、中の辞書のvalue(メンション数)を重みとして、辺を作成すれば良い。
・__クラスタリング__を行うことで、各頂点がどの__コミュニティ__に属するかを知ることができる。これを使って色分けしたり、各コミュニティごとの中心性が最大の頂点を抽出したりできる。
今回は以上です。最後まで読んでいただき、ありがとうございました。