Aidemy 2020/11/10
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、RNN_LSTMの二つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・形態素解析など
・深層学習による自然言語処理
RNN/LSTMによる自然言語処理
自然言語処理について復習
・自然言語処理では、単語ごとに文を分ける__必要がある。その手法には「形態素解析」と「N-gramモデル」__があり、主に__MeCab__などの形態素解析機が使われる。こちらについては後述。
・N-gramモデル__は__N次ごとに単語を切り分け__たり、N単語ごとに文を切り分けて__出現頻度を集計する__手法である。こちらは日本語に限らず__どの言語でも使える。
日本語の形態素解析
・日本語の自然言語処理で一番最初に行われることが__「形態素解析」である。今回はMeCabを使って形態素解析を行うこととする。
・使い方は、まず「MeCab.Tagger('')」でインスタンスを作成し、それに「parse()」__を使うことで形態素解析を行うことが可能である。
構文解析
・形態素解析を行った後に行うのが__構文解析__である。構文解析とは、各文を__文節に分解__し、文節同士の__係り受けを決定する__手法のことである。
・構文解析を行うプログラムを構文解析器といい、__「CaboCha」や「KNP」__などがある。
深層学習による自然言語処理
データの前処理
・データの前処理__は自然言語処理で__非常に大切なステップ__である。主な流れは以下の通り。(詳細は「自然言語処理」参照)
①__クレンジング処理:HTMLタグなど、文章に関係ないものを除去
②__形態素解析__
③__単語の正規化__:表記揺れなどの統一
④__ストップワード除去__:頻出の割に意味の薄い単語(助詞など)の除去
⑤__ベクトル化__:単語をベクトル化(数値化)
MeCabによる分かち書き
・MeCabによる__分かち書きのみ__を行うときは__「MeCab.Tagger('-Owakati')」とすれば良い。これを「parse(text)」で実行し、スペース区切りの単語をそれぞれ「split(' ')」で区別する。
・分けたもののうち、同じ単語を「sorted(set(word_list))」で辞書順でリストを作成する。
・このリスト(vocab)に対し、「{c: i for i,c in enumerate(vocab)}」で「{単語:id}」の辞書を作成している。
・これをword_listのそれぞれに適用して__idをリスト化__する。([vocab_to_int[x]for x in word_list]__)
・コード
・結果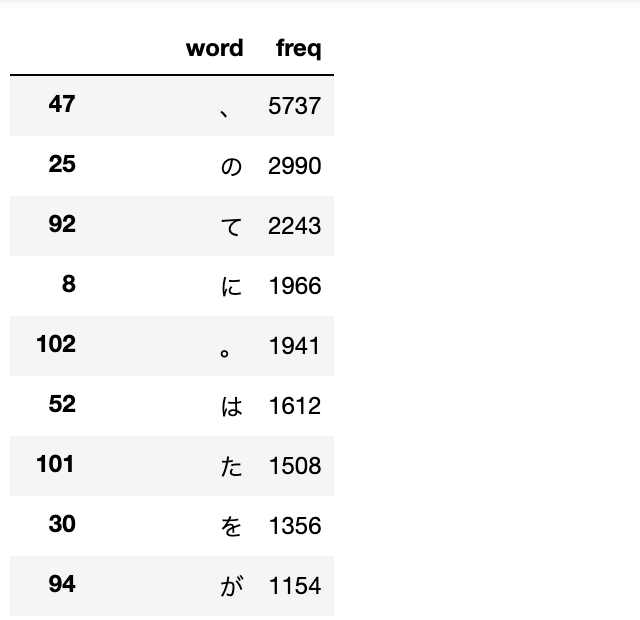
Embedding
・__単語をベクトル化する__には、__Embedding層__を使うと良い。実装は__Sequentialモデル__の中で行う。
・前項の最後で作成したidのリスト「int_list」をmodelに適用できる形(input_data)にして、model.predictで渡すとベクトル化されたリストが返される。
・コード
LSTMによる自然言語処理の実装
・今回扱うデータは自然言語のデータであるが、実装自体は今までやってきたものと大きくは変わらないので、ここではコードの掲載に留める。
・コード
まとめ
・深層学習で自然言語処理を行うときは、データを前処理すること__が大切である。具体的には「単語をベクトル化(数値化)」__しなければならないので、まずは__形態素解析__で文を単語ごとに分け、__必要のない部分を取り除く__といったことを行わなければならない。
・単語をベクトル化する時は、Embedding__を使う。実装はSequentialモデルを使う。
・自然言語処理を行うモデルの実装自体は__他のモデルと同様に行えば良い。
今回は以上です。最後まで読んでいただき、ありがとうございました。