Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師なし学習の2つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・クラスタリングの種類
・k-means法
・DBSCAN法
クラスタリング
階層的クラスタリング
・__階層的クラスタリング__とは、データの中から__最も似ている(近い)データをクラスター化していく手法__である。
・例えば、a=1,b=2,c=10,d=15,e=100のデータがあったとすると
「(a,b),c,d,e」=>「(a,b),(c,d),e」=>「((a,b),(c,d)),e」=>「(((a,b),(c,d)),e)」
のようにクラスター化し、最終的に全データがまとめられたら終了となる。
・この時、まとまりごとに階層を形成するので、階層的クラスタリングという。
非階層的クラスタリング
・非階層的クラスタリングも、階層的クラスタリングと同様、最も似ている(近い)データをクラスター化していく手法であるが、階層構造を作らない。
・非階層的クラスタリングでは、人が幾つクラスターを作るかを決め、それに従ってクラスターが生成される。
・非階層的クラスタリングは、階層的クラスタリングよりも計算量が少なくて済むので、データ量が多い時に有効である。
クラスタリングに使うデータの構造
・__make_blobs()__を使うことで、クラスター数などを指定してデータを生成できる。
・変数のうち、Xには__データの点(x,y)__が、Yには__クラスターのラベル__が入る。
・各引数について
n_samples:データの総数
n_features:特徴量(次元数)
centers:クラスター数
cluster_std:クラスター内の標準偏差
shuffle:データをランダムに並べ替えるかどうか
random_state:seed設定

k-means法
・__k-means法__は非階層的クラスタリングの一つである。クラスタリングの仕方としては、__分散の等しいクラスターに分ける__ことで行われる。
・分け方は、__SSE__と呼ばれる指標を使う。SSEとは、クラスターごとの__重心(セントロイド)__とデータ点との差の二乗和(=分散)のことである。(詳細は後述)
・そして、この分散(SSE)が最小となるような__重心(セントロイド)__を学習、選択する。
・k_means法の具体的な流れは以下のようになる。
①データの中からk個のデータを抽出し、それらを初期のセントロイドとする。
②全てのデータ点を、最も近いセントロイドに割りふる。
③各セントロイドに集まったデータ群の重心を計算し、その重心を新しいセントロイドとしてセットする。
④元のセントロイドと新しいセントロイドの距離を計算し、近づくまで②③を反復する。
⑤距離が十分近づいたら終了。
k-means法の実行
・k-means法を実行するには、__KMeans()__を使う。引数は以下を参照。
n_clusters:クラスターの個数(make_blobの「centers」に合わせる)
init:初期セントロイドの設定方法("random"でランダムにセットされる)
n_init:上記①を何回行うか
max_iter:上記②③の反復の最大回数
tol:「収束」しているとみなす許容度
random_state:初期seed
・コード
・結果
SSEについて
・SSEは「クラスターごとの重心(セントロイド)とデータ点との差の二乗和(=分散)のことである」と説明したが、この指標を__クラスタリングの性能評価に使う__こともできる。
・SSEからわかるのは__「各データと重心がどれだけずれているか」__であるため、値が小さいほどクラスターがまとまっている良いモデルと言える。
・SSEの値を表示させるには、
print("Distortion: %2f"% km.inertia)_
とすれば良い。(kmは前項で作ったKMeansインスタンス)
エルボー法
・k-means法ではクラスター数を自分で定める必要があるが、クラスター数決定の際に参考になる手法がある。これが__エルボー法__と呼ばれるものである。
・エルボー法は、__「クラスター数を大きくして行った時のSSEの値」__を図式化したものである。
・この図ではSSEの値が折れ曲がる点があり、この点を最適なクラスター数とみなして算出する。この折れ曲がり方が肘のようであることから、エルボー法と呼ばれる。
・コード
・結果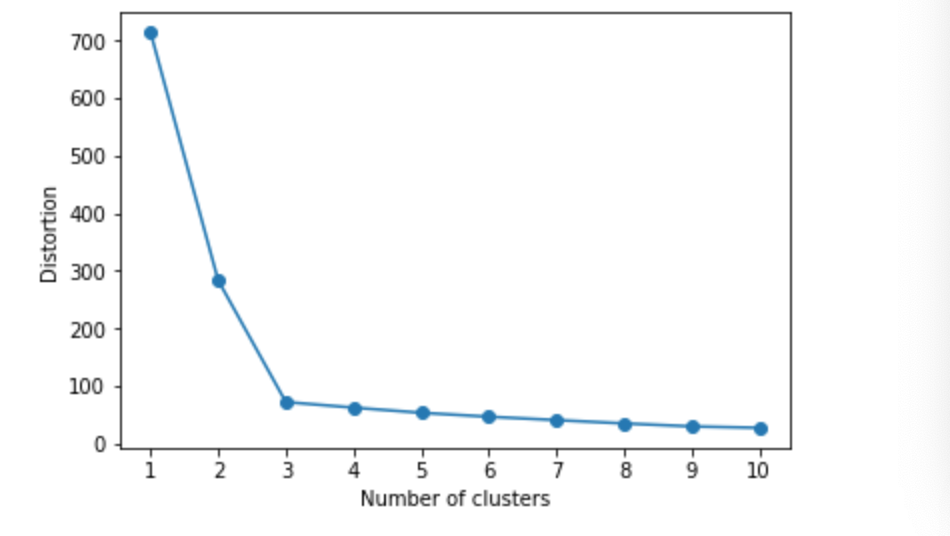
その他の非階層的クラスタリング
DBSCAN
・非階層的クラスタリングの一例としてk-means法を見てきたが、特徴としては、各クラスターの重心の周囲にデータが集まってくるので、クラスターは円形に近い形になる。そのため、__クラスターの大きさや形に偏りがない時にはクラスタリングの精度が上がりやすい__が、そうでないと良いクラスタリングにならない。
・このような時に使えるのが、__DBSCAN__という方法である。
・DBSCANは、データが一定数以上集まっているところを中心とし、その周囲にあるデータとそれ以外のデータで切り分ける手法__である。
・具体的には、「min_sample」と「eps」__という二つの指標を使って行う。手順は以下のとおり。
①データの半径「eps」内にデータが「min_sample」個以上ある場合は、その点を__コア点__とみなす。
②コア点から、半径「eps」内にあるデータを__ボーダー点__とみなす。
③コア点でもボーダー点でもない点は__ノイズ点__とみなす。
④コア点の集まりをクラスターとみなし、ボーター点を最も近いクラスターに組み込んで終了。
・このように、DBSCANではデータを三種類に分けて分類することから、偏ったデータでも良いクラスタリングが行える。
・DBSCANを実行するには__DBSCAN()__を使えば良い。(以下の__metric="euclidean"__はユークリッド距離を使うという宣言)

まとめ
・クラスタリングには、__階層的クラスタリング__と、__非階層的クラスタリング__がある。アルゴリズム上、非階層的クラスタリングは手動でクラスター数を設定する必要がある。
・非階層的クラスタリングの一つには__k-means法__がある。k-means法では重心の設定を反復させることでクラスターを生成する。
・k-means法の性能指標には__SSE__が使える。値が小さいほどクラスタリングがうまく行っていると言える。
・クラスター数とSSEの関係をプロットした__エルボー法__によって、最適なクラスター数を算出できる。
・非階層的クラスタリングのもう一つの手法として、__DBSCAN__がある。DBSCANはある範囲のデータ数を参考にしてクラスターを生成するので、偏ったデータでもクラスタリングがうまく行きやすい。
今回は以上です。最後まで読んでいただき、ありがとうございました。