Aidemy 2020/11/10
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、時系列解析の実践の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・LSTMを使った時系列解析(売上予測)
LSTMを使った時系列解析
LSTMについて
(LSTMについては「日本語テキストのトピック抽出1」「ネガポジ分析3」でも学習している)
・__LSTM__はRNNの一種で、__最初の方に入力したデータを記憶しておく__ことができる。すなわち、__長期記憶__が可能なRNNモデルである。
売上予測の手順
・今回は、LSTMを使って__売上データを予測__していく。手順は他のデータ予測と同じである。
①データ収集
②データ加工
③モデル作成
④予測・評価
①データ収集
データ読み込み
・今回は、シャンパンの売り上げ予測の__csvデータを読み込む__ことで、データ収集を行う。
・LSTMのデータ予測では、時系列データの値のみを使用する__ので、これのみを取得する。具体的には、「pd.read_csv()」を行えば良いが、引数には「usecols=[列]」で__取り出す列を指定__し、「skipfooter=行数」で、末尾から読み込まない行数__を指定する。また、skipfooterを使用するときは「engine='python'」と指定する必要がある。
・ファイルを読み込んだら、それに「.values」を使ってindexやcolumnを除いた__データのみを取り出す。
・最後に「.astype('float32')」__で__float型に変換__することでLSTMの分析に適合させる。
・コード
・結果(一部のみ)
②データ加工
データセットの作成
・ここでは__データを分析に使用できる形に整形していく__。
・まずはデータを__トレーニングデータとテストデータに分けていく__が、時系列データには周期性や連続性といった情報も存在する__ため、ランダムにデータを分割してしまうとこれらの情報が失われてしまい、データとして破綻してしまうので、ランダムに分けてはいけない。
・今回は元のデータを__3分割__にして、前半2/3をトレーニング用、残り1/3をテスト用に分ける。
・コードとしては、まず__分ける長さを設定する__必要がある。今回は全体の2/3、小数で表すと__0.67__で分割するので、これを「int(len(dataset)*0.67)」というように表す。
・この長さをもとに、データを「train」と「test」に分ける。分割する長さを「train_size」とすると、trainは[0:train_size, :]で取得でき、testは[train_size:len(dataset), :]__で取得できる。
・コード
データのスケーリング
・(復習)スケーリング__とは、単位や範囲の異なるデータを__ある基準で均一化する__ことにより、値の影響の度合いを揃える__処理である。
・スケーリングには「正規化」と「標準化」がある。正規化は「最低値0最高値1」、標準化は__「平均0標準偏差1」にする変換である。
・テストデータも含めてスケーリングを行うと、モデルがデータに適合し過ぎてしまい予測精度が低くなってしまうので、トレーニングデータのみを基準にしてスケーリングを行う。
・正規化でスケーリングをするときは「MinMaxScaler(feature_range=(0,1))」を使用する。これを「fit(train)」でトレーニングデータ基準でスケーリングのパラメータを定義し、あとはこれを「transform(train)」「transform(test)」__でそれぞれスケーリングを行う。
・コード
・結果(一部のみ)
入力データ・正解ラベルの作成
・今回の予測は__「基準となる点から前の複数のデータ」を使って「次のデータの予測」を行うので、入力データは「基準となる点とそこからn時点前までのデータ」であり、正解ラベルは「基準点の次の時点のデータ」__である。
・データの作成には、「基準となる点とそこからn時点前までのデータ」を取得する処理が__繰り返し行われる__ため、あらかじめこの繰り返し処理を定義した__関数を作成__して、それに前項で作成したトレーニングデータとテストデータを渡して__入力データ__と__正解ラベル__を作成する。
・コードは以下の通り。意味については後述する。

・今回の__「create_dataset」関数について、データ__dataset、基準点からどのぐらい前までのデータを取るか(n)を指定する__「look_back」が引数として渡される。まずは入力データを格納する「data_X」正解ラベルを格納する「data_Y」を準備する。
・「for i in range(look_back,len(dataset))」について、これは「基準点の翌日の点」の位置を表している。つまり、基準点は「i-1」ということになる。data_Xには、「dataset[i-look_back:i,0]」で「i-look_back以上i未満(基準点まで)のデータ」を格納し、data_Yには「dataset[i,0]」で「基準点の翌日のデータ」__を格納している。あとはこれらを__np.array配列__で返せば良い。
・今回は__3つ前のデータを1セット__とする、すなわち__「look_back=3」とする。上記コードのように関数create_datasetにトレーニングデータとlook_backを渡すことで「train_X」「train_Y」を作成でき、同じようにテストデータを渡すことで「test_X」と「test_Y」__が作成できる。
入力データの整形
・前項で入力データと正解ラベルを作成したが、入力データの方はまだLSTMで分析できる形式ではないので、整形を行っていく。
・具体的には、入力データを__「行数×変数数×カラム数」の__3次元__に変換する。行数は__データの総数、変数数は__1セットに含まれる要素数__、カラム数は__扱うデータの種別数__を表す。
・次元の変換は__「reshape()」で行う。引数に渡すと(numpy.shape[0],numpy.shape[1],1)__というようになる。
・コード
・結果(train_Xの一部)
③モデル作成
LSTMモデルの作成と学習
・今回は__Sequentialモデル__で作成していく。よってLSTM層の追加は__「model.add(LSTM())」__で行える。 __LSTMブロックの個数__を指定し、__input_shape=(look_back, 1)として長さlook_back、次元1の入力層を作成する。
・出力層は翌日のデータ、つまり1クラスで良いので「Dense(1)」__とする。
・次に__コンパイル__を行う。__損失関数loss__と__最適化アルゴリズムoptimizer__を設定する。今回は__回帰モデル__なので、損失関数(正解ラベルと出力の誤差を測る関数)には__平均二乗誤差「mean_squared_error」__を使用する。最適化アルゴリズム(損失関数の勾配が減少するように重みを変化させる手法)はいろいろあるが、実際試してみないとわからない。
・学習は__「model.fit()」で行う。引数には__epochs(学習回数)、batch_size(データの分ける数)を渡す。
・あとは層の数やepoch数などを変化させて__チューニング__する。仮にLSTM層の次にLSTM層を追加する場合は、追加元の引数に__「return_sequences=True」__を記述する。
・コード

・結果(一部のみ)
④予測・評価
・最後にモデルの予測と評価を行う。
・予測には__「model.predict()」を使う。これにtrain_Xとtest_Xを渡せば良い。
・次に予測結果を評価していくが、正しく評価するには__スケーリングしたデータをもとに戻す必要がある。__「transform()」でスケーリングを行ったが、今回はその逆を行う「inverse_transform()」__を使う。
・スケーリングのときに、__「fit(train)」__でトレーニングデータ基準でスケーリングのパラメータを定義したが、今回のinverse_transformでも同じ定義を使う。この定義を「scaler_train」とすると、トレーニングデータの予測値を格納した「train_predict」、正解ラベルを格納した「train_Y」は次のようにしてもとに戻す。

・これをテストデータにも同様に行う。ここまで行ったら、次は__データを評価__していく。
・時系列データの精度指標では、先ほども出てきた__「平均二乗誤差」__を使っていく。改めてであるが、この指標は予測値が正解からどれぐらい離れているかを示すものであり、__0に近いほど精度は高い__ということになる。
・コードとしては__「math_sqrt(mean_squared_error(正解ラベル,予測値))」と記述する。
・今回の場合、正解ラベルは__train_Yの0列目__に格納されており、予測値は__train_predictの0列目(の各行)に格納されているため、それぞれ以下のコードのように指定すれば良い。
・コード
・結果
予測結果の可視化
・今回は可視化されることを見たいので、具体的なコードな掲載に留める。
・コード
・結果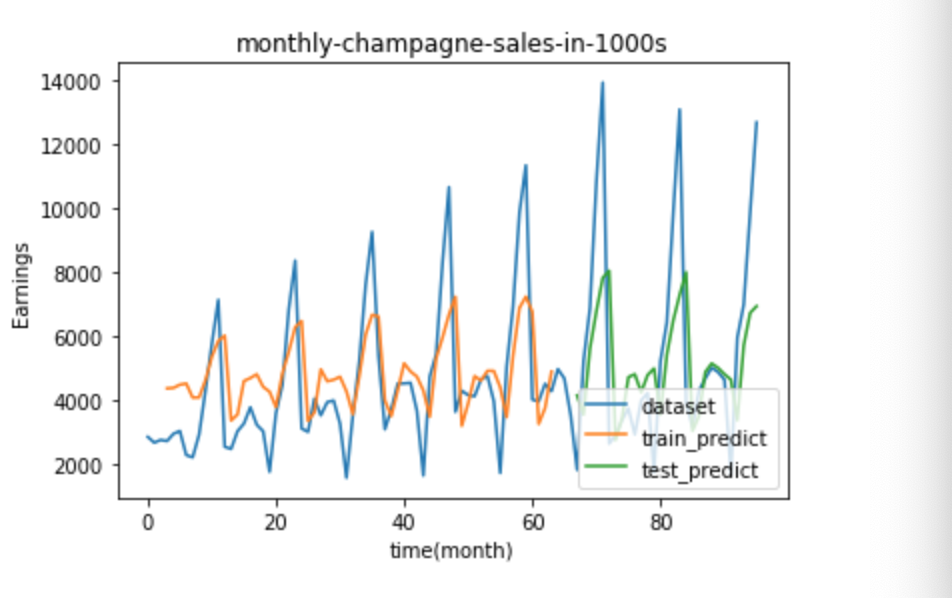
まとめ
・時系列解析では、長期記憶が可能である「LSTM」を使ってモデルを作成するとよい。
・データを取得しても、そのままでは分析には使えないことが多いので、整形を行う。スケーリングを行ったら、それを入力データと正解ラベルに分けることでモデルに渡せるようになる。入力データの方は、さらに次元を3次元にしておく。
・モデルはSequentialで行う。層の追加、コンパイル、学習まで行ったらモデルは完成である。あとはモデルを評価する。評価の際にはスケーリングしたデータを元に戻す必要がある。
今回は以上です。最後まで読んでいただき、ありがとうございました。