Aidemy 2020/10/
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、データハンドリングの3つめの投稿になります。どうぞよろしくお願いします。
*この章は難解で私自身も十分理解しているわけではないので、予めご了承下さい。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・Protocol Buffersについて
・hdf5について
・TFRecordについて
Protocol Buffersについて(発展)
Protocol Buffersとは
Protocol BuffersはGoogleではデータの保存や構造化されたあらゆる種類の情報の交換で用いられている。
(引用:wikipedia Protocol Buffers "https://ja.wikipedia.org/wiki/Protocol_Buffers")
・データ処理の方法としては、予め__Message Type__というものを定義して行われる。
・Message Typeはクラスのようなもので、proto2という言語で定義される。
Message Typeの定義
・はじめに、家族構成についてまとめられたMessage Typeのソースコードを参考に、書き方を見ていく。
・コード
・「syntax = "proto2";」でproto2の使用を宣言。「;」は行末に必ずつける。
・「message Person{}」は「Person」というクラスを表している。
・コメントは、一行なら「//」、複数行なら__「/* */」で表せる。
・「required string name = 1;」について、「string name」は「name」がstr型であることを表す。このような二単語を合わせて__field__という。「=1」の部分は__タグ__と呼ばれ、データ出力の際にデータを見分ける役割を持つ。「required」__は「必須項目」につける必要がある。
・同様に、「required int32 age = 2;」なら、「age」がint型であり、タグが2であることを表す。
・「enum Relationship{}」は、strやintのような「型」を新しく定義している。ここでは「Relationship型」ということになる。
・enumの中では、各値(MOTHERなど)に対して新しくタグをつける必要がある。enum内のタグは「0」から始める。
・「required Relationship relationship = 4;」は「str name」と同じで、「relationship」がRelationship型であることを示し、タグが4であるという意味である。
・「message Family{}」はPersonと同じでFamilyクラスを表す。
・「repeated Person person = 1;」の__「repeated」__は、「リスト」のようなものであり、この場合Person型のデータがリスト化される。
Message Typeをpythonで扱えるようにする
・以上のコードが書かれたファイルを「family.proto」とする。このファイルをpythonで扱えるようにするには、コマンドで
protoc --python_out = 保存先のファイルパス Message Typeファイル名
と入力する。
Pythonでデータを記述する
・Message Typeファイルをpython内で読み込むことで、その中で定義した型(family.protoで言えばFamily型など)を使うことができる。これを使って、実際にpython内でデータを入力していく。
・コード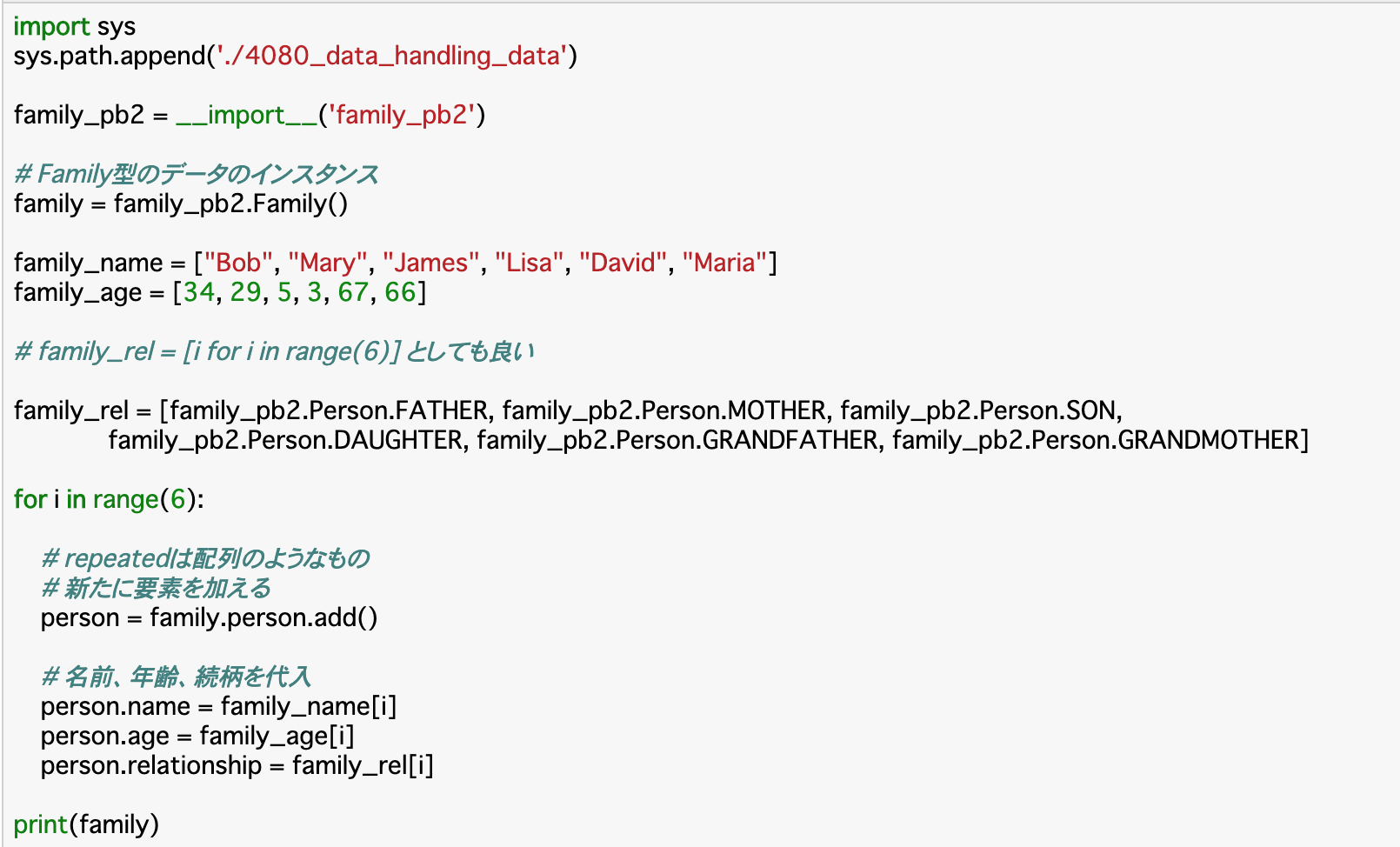
・結果(一部のみ)
hdf5について
hdf5とは
・hdf5とは、kerasで使われるデータ形式のことで、例えばkerasで作成した学習モデルを保存するときに使われる。
・hdf5では、__階層的な構造を1ファイル内で完結させることができる。__つまり、複数のフォルダ(ディレクトリ)が階層的に作られていたとしても、hdf5側ではそれを包括してファイルが作成できる。
hdf5ファイルの作成
・作成には__h5py__というライブラリとPandasを使う。
・以下では、A県の人口を例に、hdf5ファイルを作成する。
・コード
・hdf5ファイルを開く:hdf5.File("ファイル名")
・グループ(ディレクトリ)の作成:ファイル.create_group("グループ名")
・ファイルの書き込みは__flush()__,閉じるのは__close()__で行う。
TFRecordについて
TFRecordとは
TFRecordは、「メモリに収まらないような大きなデータを処理できるようにしたもので、シンプルなレコード指向のバイナリのフォーマット」ということです。
引用:tdl TensorFlow推奨フォーマット「TFRecord」の作成と読み込み方法
[https://www.tdi.co.jp/miso/tensorflow-tfrecord-01#:~:text=TFRecord%E3%81%AF%E3%80%81%E3%80%8C%E3%83%A1%E3%83%A2%E3%83%AA%E3%81%AB%E5%8F%8E%E3%81%BE%E3%82%89,%E3%81%AE%E3%83%95%E3%82%A9%E3%83%BC%E3%83%9E%E3%83%83%E3%83%88%E3%80%8D%E3%81%A8%E3%81%84%E3%81%86%E3%81%93%E3%81%A8%E3%81%A7%E3%81%99%E3%80%82]
・TFRecordはTensorFlowで使われるデータ形式のことで、上記のように、大きなデータを処理できるようにするものである。
画像をTFRecord形式にして別ファイルに書き出す。
・流れとしては「画像を読み込む」「書き出す内容の定義」「書き込む」という感じ。
・以下で実際に行う(ファイルパスは架空のもの)
・コード
・「書き出すデータの定義」の箇所について、「tf.train.Example()」「tf.train.Features()」「tf.train.Feature()」「tf.train.ByteList()」といった多くのインスタンスが階層的に生成されているが、それぞれに役割がある。
・「tf.train.ByteList(value=[データ])」について、これは[]内のデータをもつインスタンスを生成する。このデータはbyte型である必要があるので、__tobytes()__を使用する。
・「'キー':tf.train.Feature()」は、ByteListインスタンスから、キーを持った__Featureインスタンスを生成する。
・「tf.train.Features()」は、複数のFeatureインスタンスを__辞書としてまとめる。
・「tf.train.Example()」は、FeaturesインスタンスからExampleインスタンスを生成する。これにより、ファイルに書き込むことが可能になる。
・「書き込む」の箇所について、__「tf.python_io.TFRecordWriter('ファイル名')」は、TFRecord版の「open('w')」である。
・「fp.write(my_Example.SerializePartialToString())」__で、最終的に書き込めば完了。
可変長と固定長のリスト
・リストには、長さを変えられる一般的な__可変長__と、決められたデータしか入れられない__固定長__がある。
・pythonのリストは普通可変長であるが、前項の「tf.train.Example()」は固定長である。
・可変長のデータを生成する時は__「tf.train.SequenceExample()」__とする。
今回は以上です。最後まで読んでいただきありがとうございます。