Aidemy 2020/10/30
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、日本語テキストのトピック抽出の2つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・回答文選択システムの実装
回答文選択システム
・__回答文選択システム__とは、質問文に対して複数の回答文の候補が与えられ、その中から__正しい回答を自動で選択するシステム__である。
・データセットについては__Textbook Question Answering__というものを使い、訓練データを「train.json」、評価データを「val.json」として使う。
データの前処理
・自然言語処理で深層学習を使う場合、データはそのままの文章では扱えない。「自然言語処理」で学んだように、文はまず単語に分ける作業「分かち書き」を行わなければならない。今回はさらに__単語ごとにIDを付与__するということも行う。
・また、入力する文は長さが異なると行列計算ができないので、「入力する文の長さを統一」する必要もある。このことを__Padding__ともいう。詳しくは後述するが、短い文には0を追加し、長い文は削るといった手法で行う。
正規化・分かち書き
・データの前処理として、最初は__正規化と分かち書き__を行う。今回はデータが英語なので、正規化、分かち書きも英語の方法で行う。
・英語の正規化は、大文字小文字に統一する__という方法が取られる。今回は「全て小文字で統一する」処理を行う。英文に対し「lower()」メソッドを使うことで小文字にできる。
・英語の分かち書きにはnltkというツールを使う。nltkの「word_tokenize()」に正規化した文を渡すと__単語ごとに分割したリストを返してくれる。
・コード(結果は['earth','science','is','the','study','of'])

単語のID化
・単語のままではニューラルネットに入力として扱われないため、IDを付与する必要がある。
・全ての単語にIDを付与するとデータ数が大きくなりすぎるため、IDに変換するのは頻度が一定以上のものだけにする。
・実際のコードは以下のようになる。詳しい解説は下記参照。

・上記コードについて
__「def preprocess(s)」__は前項の__正規化と分かち書きを行う関数__である。その下では、preprocess()を使ってtrainデータの['question']の質問文と['answerChoices']の各回答文について正規化と分かち書きを行い、その結果(リスト)を空のリスト「sentences」に格納する。
このsentencesの中にある「分かち書きされた各リスト(s)」の各単語(w)について、'w'自身をキーとして「vocab.get()」で取得した頻度を値として持つ組を辞書「vocab」に格納する。
さらに空の辞書「word2id」を用意し、vocabのそれぞれのキー(w)と値(v)について、word2idに同じキー(w)がまだなく、値(v)、すなわち頻度が2以上のものについては「len(word2id)」でIDを付与する。ちなみに、頻度が1で''とみなされた場合には全て値が0となるようにあらかじめ設定しておく。
一番下の「target」の部分は、実際に'question'を正規化・分かち書きを行い、各単語について「word2id」にあるidを取得している。
Padding
・データの前処理として、最後に__文の長さを統一するpadding__を行う。具体的には、__短い文に対しては末尾にダミーIDである0を必要な分だけ追加__し、長い文については文末から必要な分だけ単語を削除する__という方法で行われる。
・paddingの実行にはkerasの「pad_sequences(引数)」__を使えば良い。第一引数にはデータを渡す。それ以下の引数は以下の通り。
・maxlen:最大の長さ
・dtype:データの型(今回のような場合は「np.int32」)
・padding:'pre'か'post'を指定。paddingを文の前から行うか後ろから行うかを指定する。
・truncating:paddingと同様。こちらは単語の削除を行う。
・value:どの値でpaddingするかを指定。(今回は0)
・コード
モデルの構築
全体像
・モデルには__「Attention-based QA-LSTM」というものを使用する。手順は以下の通り。
①QuestionとAnswerのそれぞれについて__BiLSTMを実装する。
②QuestionからAnswerに対して__Attention__し、Questionを考慮したAnswerの情報を取得する。
③QuestionとAttention後のAnswerから、各時刻における隠れ状態ベクトルの平均(mean_pooling)を算出する。
④③の二つのベクトルを__結合して出力__。
・図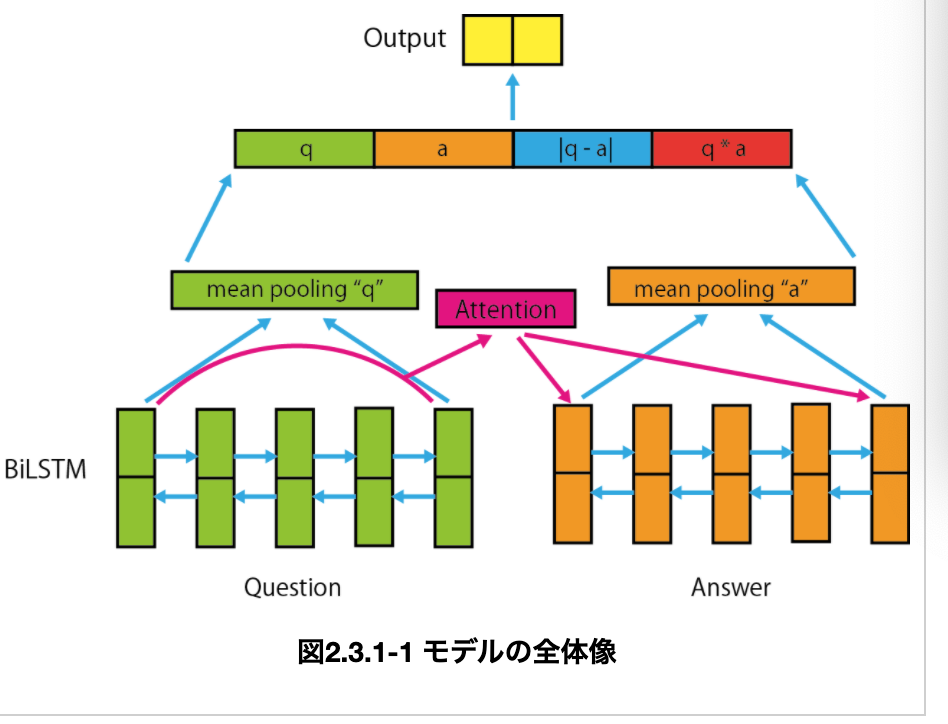
①QuestionとAnswerのBiLSTMを実装
・BiLSTM__はChapter1で見た通り、双方向から値を入力していく「双方向再帰ニューラルネット」である。実装は「Bidirectional(引数)」__で行う。
・Questionの入力層を「input1」として、__Embedding__を行ったものを__Bidirectional()__でBiLSTMとする。同様にAnswerについても入力層を「input2」としてBiLSTMを実装する。
・コード
②QuestionからAnswerへのAttention
・__Attention__を使って、機械に「AnswerがQuestionに対する回答文として妥当かを判断させる」、すなわち、ある時刻におけるQuestionの隠れ状態ベクトルを考慮してAnswerの特徴を計算することで、Questionの情報を考慮したAnswerの情報を取得できる。
・二つの文のBiLSTM「bilstm1」「bilstm2」をDropoutした「h1」と「h2」について「dot()」で行列積を算出し、それに対し__Softmax関数__を適用させ、更に__これとh1との行列積を算出__し、これとh2を「concatenate()」で連結させたものをDense層として形成することで作成できる。
・コード
各時刻における隠れ状態ベクトルの平均(mean_pooling)を算出する
・QuestionとAttention後のAnswerから、各時刻における隠れ状態ベクトルの平均を算出する。この時の平均を__「mean_pooling」という。
・mean_poolingは、kerasの「AveragePooling1D(引数)(x)」__で実行する。各引数について
・pool_size:渡すデータxの長さを指定
・strides:整数かNoneを指定
・padding:'value'か'same'を指定
・コード(後述)では、まず前項で作成した「h1(Questionの出力)」「h(Answerの出力)」に__AveragePooling1D__を使用する。④で結合するために、これらを__Reshape__しておく。
③の二つのベクトルを結合して出力
・最後に、③で作った「mean_pooled_1」と「mean_pooled_2」を__concatenate()で結合する。
・concatenate()には、今回のコードで言うと「sub」や「mult」も渡す必要がある__ので、それぞれ作成しておく。これを__Reshape__し、outputとして出力層を作成したら、__Model()__でモデルを作成する。入力層は①で作成した「input1」と「input2」を渡す。
・コード
モデルの学習
学習
・モデルが作成できたので、次は__このモデルに学習をさせる__。モデルの学習自体は「model.fit()」で良いが、その前に__訓練データと正解ラベルを作成する__必要がある。
・訓練データについては、質問と回答をリスト化して渡す。手順としては、まず空のリスト「questions」「answers」を作成し、前者にはtrainデータの__'question'を、後者には'answerChoices'の値の部分を格納してmodelに渡す。
・正解ラベルについては、「回答と同じ選択肢を[1,0],それ以外を[0,1]」として空のリスト「outputs」に入れ、これを__np.array()でNumPy形式にしてからmodelに渡す。「回答と同じ選択肢」かどうか__は、'answerChoices'のキー(番号)が'correctAnswer'と一致しているかどうか__を見れば良い。
・コード
テスト
・最後に__評価データを使ってモデルの精度をテストする__。今回は__2値分類__なので、精度の指標には__「正解率(Accuracy)」「適合率(Precision)」「再現率(Recall)」を計算する。
・(復習)予測の実際のクラス分類について__真陽性、偽陽性、偽陰性、真陰性__の四つがあり、「全体の中でどのぐらい予測が正解したか」が__正解率、「正と予測したもののうち、実際に正だった割合」が__適合率__、「正解が正のもののうち、予測も正だった割合」が__再現率__である。
・今回これらの指標を計算するにあたっては、まず__真陽性などの個数を調べなければならない__。調べるには、クラス分類の「予測」と「正解」がなければいけないので、これを取得する。「予測」は__「model.predict()」__で取得し、「正解」は前々項で作成したoutputsからそのまま取得できる。このどちらも正解(正)なら[1,0],不正解(負)なら[0,1]で格納されているので、axis=-1で2列目のみを抽出すれば、正負がわかる。あとはこの正負に基づいて真陽性などの四つを分類し、正解率などを算出する。
・コード
・結果
Attentionの可視化
・文章sからtへのAttentionの時、__$a_{ij}$_は、sのj番目の単語がtのi番目の単語をどれぐらい注目しているか__を表す。この$a{ij}$を(i,j)成分にもつような行列Aを__Attention Matrix__という。これを見ると__sとtの単語間の関係を可視化することができる。
・縦軸が__回答単語__であり、横軸は__質問単語__である。__白い部分__がより関係が深いものということになる。
・図(コードは以下)
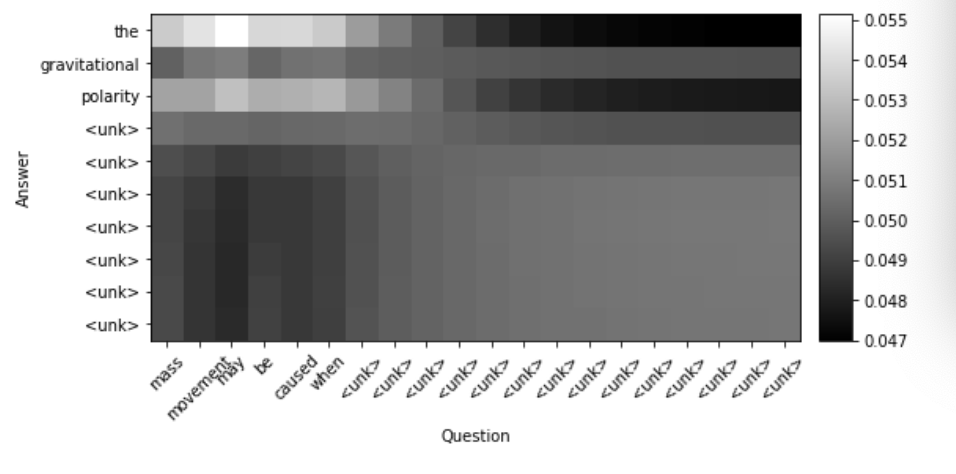
・コード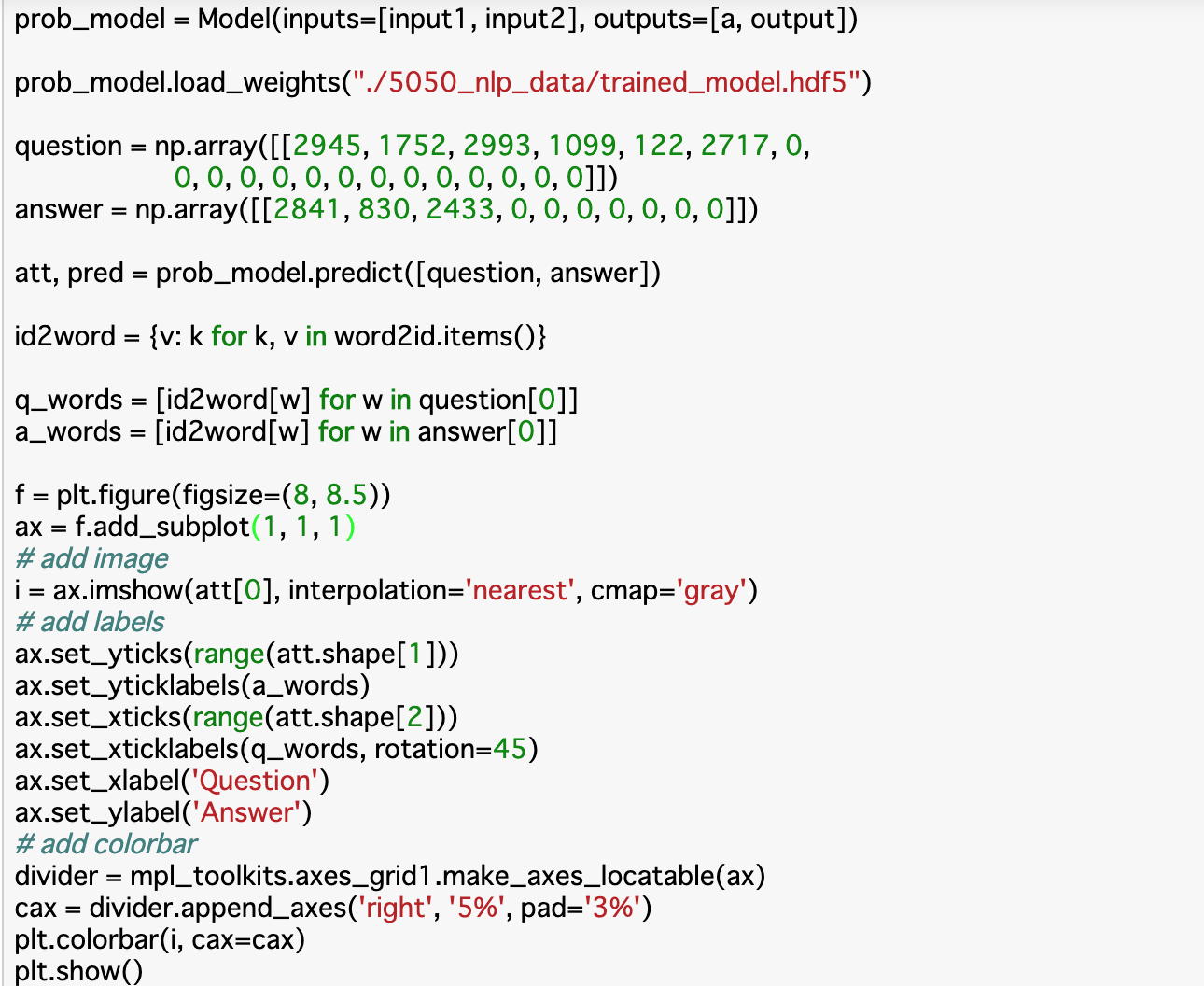
まとめ
・深層学習のモデルにデータを渡すときは、そのデータを前処理する必要がある。前処理としては、分かち書き、正規化、ID化、Paddingの四種類である。
・今回使うモデルである「Attention-based QA-LSTM」は、BiLSTMを実装し、QuestionとAttention後のAnswerの平均を算出し、それを結合することで構築する。
・モデルの学習の際は学習データ(質問ID)と教師ラベル(回答番号)を渡す。評価の際は正解率、適合率再現率を計算する。
・Attentionを可視化することで2つのデータの関係性をみることができる。
今回は以上です。最後まで読んでいただき、ありがとうございました。