Webサーバのログで見えるものと見えないもの
Webのログ監視や、その手前にあるWAFの運用をしていると、「このアクセスログ、正常?異常?」という課題にぶつかることが多々あります。
正常なログとは、正常な利用者によるアクセスログ。
じゃぁ試しに自分のブラウザからアクセスしてみて、DevToolsのNetworkの結果とサーバのログを比べてみると、、、一致しないんですね、全然。
ここらに関する話を軽くまとめておこうかなと思います。
Webアクセス時に発生する通信
例としてzennに接続してみましょうか。
ChromeのDeveloper toolsを起動した状態で https://zenn.dev/about にアクセスすると。

はい、ズラズラ出てきますね。
"about"というhtmlファイルが画像やcssやjsを読み込んで、cssやjsがまた別のファイルを読み込んで、、と芋づる式にズルズルと大量のコンテンツが読み込まれる。
逆に言うと、これらのアクセスログ群をサーバで見つけたら、運用者的には「あー、ユーザはaboutにアクセスしたのね、OKOK、正常正常」と判断できるわけです。
ただし、zenn.devのサーバで見えるのは赤枠のところのみ。
外部コンテンツの読み込みなど、自サーバ以外のサーバに取りに行くコンテンツは、当然サーバログ側からは見えません。
また、自サーバのコンテンツのはずなのだけど、サーバ側にアクセスログが出ないものがあります。
これが今回のテーマの、通信経路の途中にコンテンツがキャッシュされているケースの話。
(ちなみに最初はqiita.comを題材にしようとしてたのですけれど、あちらはコンテンツの多くをqiita.comではなくcdn.qiita.comに配置する形式なので、題材としてちょっと使いにくいので 、やめときました。)
キャッシュとは
https://developer.mozilla.org/ja/docs/Web/HTTP/Caching
仕組みとしては以上のとおりですが、端的に言うと、Webサーバの代わりに通信経路上の機器が代理でコンテンツを返してくれる仕組み。
キャッシュをしてくれる機器・サービスが通信経路上の箇所がどこにあるかというと、最近の構成だとざっくり以下でしょうか。
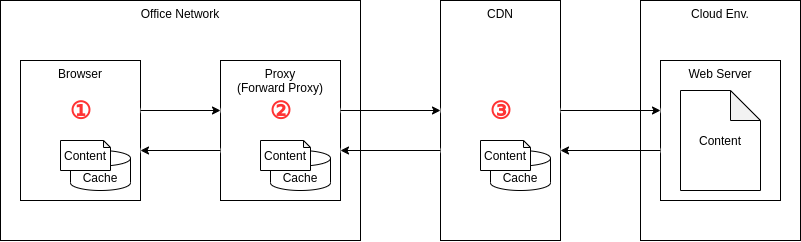
いずれにしても重要なのは、一部のコンテンツのリクエストは途中経路のどっかしらから返されるので、Webサーバに届かない、ということですね。
ちなみにCDNの説明では、Webサーバのことを「オリジン」と呼ぶことが多いと思います。必ずしも「Webサーバ」であるわけでもないので「オリジン」のが使いやすい表現なのですが、今回は「Webサーバ」で一貫して記載するようにします。
キャッシュしたコンテンツの賞味期限/鮮度
細かくは上記のMozillaのページを読んでいただくとして。
ざっくり書くと、上記の3つのキャッシュは、以下のどれかの動きをします。
- コンテンツを持ってなければ、Webサーバからコンテンツを取得し、それを返す。
- キャッシュしているコンテンツを返す。
- キャッシュが古い/古いかもなので、Webサーバにコンテンツが更新されていないか確認する。更新があったら更新後コンテンツを取得して自分のキャッシュを更新し、それを返す。
- 更新なしと回答を受けたら、自分の持っているキャッシュを返す、
- 返事がないなら、独自の対応をする。
重要なのは、”期限切れ=コンテンツの破棄+取り直し”ではなく、更新があるかを確認するという手順が1回入ること。
コンテンツの破棄は、キャッシュしている環境の容量都合などで都合で実施されるのでしょうけれど、これはオリジンが管理するものではない、という点は意識しておく必要があるかと思います。
また、オリジンがキャッシュNGと設定しているコンテンツは、毎回Webサーバにコンテンツを取得しに行きます。
キャッシュしてくれる機器・サービスの種類
RFPとかで正しい名称決まってるようなら誰か突っ込んでいただけると嬉しい、、
1. ブラウザ
ブラウザ自体が、PC上にコンテンツをキャッシュします。
Webサーバが明瞭にcontrol-cacheヘッダにno-storeとしていないコンテンツは、全部キャッシュする。
1に該当する場合は、Networkでみると以下のようにstatusが灰色になり、Sizeが"(disk cache)"になります。

2. Proxy
事務所内のプロキシ。
商用だとBlueCoat(Symantecというか、Bloadcomというか、、)、オープンソースだとSquidなどでしょうか。
セキュリティサービスと連携等、へんてこな設定をしていることが少なからずあり。
サーバ側から見て不明な振る舞いがあると、「ユーザ宅のプロキシがなんか変なことしてるんじゃないかな、、」と思考停止してしまいそうになるので要注意。。ちゃんと勉強しないとなぁ。。
3. CDN
世界中にキャッシュサーバをばらまいておき、エンドユーザの最寄りからコンテンツを返すサービス。
Akamai, Fastly, AWS Cloud Frontなどなど。
今回の記事で題材にするのは通信経路上に配置して、ユーザからのアクセスに応じて都度Webサーバにコンテンツを取りに行って、それをキャッシュするタイプのものです。
CDNというとコレとは別に、コンテンツを予め専用の配信の環境に預けておいて、そこから配布するというタイプのものもあります。すごく雑に言うとAWSのS3のような。今回はそちらのタイプには触れません。
キャッシュするものしないもの
基本、すべてWebサーバで決めます。
コンテンツを返す際に、ヘッダ情報としてcache-control, etag, last-modified, surrogate-control, などの情報をつける、つけない、で制御します。
通信経路上にあるCDN、Proxy、ブラウザは、このヘッダ情報を見て、コンテンツをキャッシュしてよいか、キャッシュせず都度Webサーバに問い合わせるべきかを判断します。
ただし、CDNもProxyも、Webサーバのヘッダ情報を無視してキャッシュする・しないを決められるようになっている(と思います)。
自分が実際に使ったことがあるのはAkamaiだけですが、ざっと主要どころを調べると一通りWebサーバのヘッダ無視してキャッシュ有無を決める設定があるようです。
参考
Akamai(CDN)
Fastly(CDN)
https://docs.fastly.com/ja/guides/configuring-caching
https://qiita.com/AtsushiFukuda/items/e6a57094cfb19e7875a5
AWS(CDN)
Squid(Proxy)
改めて眺めるアクセスログ(ブラウザ編)
以上を踏まえて、あらためてブラウザのNetworkを見てみましょうか。
キャッシュを機能させるために、https://zenn.dev/aboutに1回アクセスした後、URL欄でリターンを空打ちしてみます。

上の赤枠が1回目。下の青枠が2回め。
aboutコンテンツは、Webサーバに1回更新が無いか聞きに行き、無いよ(304)という応答を受け取ってます。
それ以降のcssやjsは、全てブラウザにキャッシュされたデータをそのまま使ってます。
試しにaboutと、その真下のcssのヘッダ情報を見てみると。

aboutは、max-age=0(鮮度は0秒)かつmust-revalidate(毎回鮮度確認しなさい)とWebサーバから指示が出ているので、それに従って更新がないか聞きに行ったわけですね。
一方cssの方は、max-age=3153600(365日)かつimmutable(鮮度切れるまで再問い合わせしてくんな)と指示が出ているので、賞味期限も切れてないからブラウザのキャッシュをそのまま使う、と。
改めて考えるサーバで見えるはずのログ
さて一方サーバ側からみると。
実際のログはそりゃ見えないのですが、https://zenn.dev/about の例だと、1回目のアクセスは(同一の経路を通る他のブラウザが先にアクセスして、キャッシュができていなければ)すべてのアクセスがWebサーバに届き、ログが残る。2回目は、"about"だけ見える(あるいは、CDNが完全に代理応答するので、全く見えないか)となる。
aboutの例だとcssの鮮度は365日と非常に長いけれど、数日〜数時間だったり、コンテンツによって時間がずれていたりすると、アクセスするタイミングによってabout+キャッシュが切れた分のコンテンツへのアクセスが混ざった状態でWebサーバに届くようになる。
正常な通信と異常な通信
以上を踏まえて、サーバログから正常異常を判断する方法を考えると。
キャッシュによるアクセス有無を考慮した上で、それらの元になったであろうアクセス先(上記の事例だとabout)を推定できるなら正常なアクセス。
推定できない(まとまりのないimgへのアクセスとか、毎回一緒に読み込まれるはずのcssを読み込まない特定コンテンツ/機能のみへの連続接続とか)は、異常、と判断できます。
これをある程度ロジカルにやる仕組みは、おいおい作ってみようかなと思います。
まぁサイトを使う正常な利用者は人間だけってわけでもなく、API叩きに来る連携システムなんかがいるので、上記の基準ですべてが語れるわけでもないのですけれど。
ざっくりですが、本日はこんなところで。
TIPS
この記事を書くに当たってブラウザのDebugtool(Network)を多用してたのですが、その際にハマった点を少々、、
ブラウザキャッシュの動作確認
"Disable Cache"のチェックを外す!
いや、そりゃそうなんですけどね。。
通常デバッグツール使うときは、キャッシュの影響を考慮するのめんどくさいので、こいつのチェックを入れることが少なからずあると思います。
このチェックが残ってると、当然キャッシュのふるまいのチェックはできないわけです。。
ハードリロードは使わない!
これも、いつもの癖でctl+shift+rでリロードするのですが、コレやっちゃうとキャッシュ使わずにアクセスするので、今回のようなケースでブラウザキャッシュ使ってるかどうかの確認には使えません。。。
リロード自体も使わない!
リロードの場合、まだ賞味期限が切れてないブラウザキャッシュがあっても、賞味期限確認は実施する、という動きをします。
URL欄でリターンの空打ちをする。
今回の用途で適切だったのは、この操作でした。
これならブラウザキャッシュしているコンテンツは鮮度確認しない、鮮度切れてるコンテンツは賞味期限確認に行く、という想定しているキャッシュの動作をちゃんとしてくれます。