はじめに
この記事は、本番環境などでやらかしちゃった人 Advent Calendar 2024 の14日目です。
ここで書くできごとは、私が12年前に招いたネットワーク障害の話です。 書くにあたって当時の資料やメモを見たのですが、「あああああああああ! 何を考えているんだこのお馬鹿さんは」という気持ちにしかなりませんでした。
こういうことに気を付けねばならない、こういうことをしてはいけないと自戒の碑として、書いておく次第です(ご迷惑をおかけした関係者の皆様、本当にすみませんでした)。皆様の参考になれば幸いです。
背景
担当していたサービスの機能追加にあたり物理のロードバランサー機器を導入することを求められました。当時、クラウドも今ほどは使用されていません。データセンターでラックを借りて、そこから上の機器選定・設置からプログラムのデプロイまで全部自前でサービスを提供していました(ここは今もあんまり変わらない)。
そのサービス群を構成する機器は4種類のみとシンプルなものでした。
- VMWareを動かす物理サーバー
- iSCSIストレージ
- FireWall(UTM、L3はここで制御)
- L2スイッチ(スタッカブル)
シンプルなものを(寄せ)集めて構成した、という言い方が正確かもしれません。
当時、専任のインフラ担当がほとんどおらず、各担当が片手間でインフラというかネットワークを構築していたため、何とか手の届く/分かる範囲の機材で運用していたのです(もうこの時点で怖い。今はそうではありません。← 断言)。
例えば、ストレージは iSCSI のものを選定していました。「ファイバーチャネルなんて知らない。でもLANケーブルは分かるよ。このiSCSIストレージとやらはLANケーブルさすんだよね。どうにかなるかも。」とこれは各担当で意見が一致したからです。
物理のロードバランサーは、こんな外見をしています(このメーカーのものではないが、風評被害を防ぐためロゴは隠した💦)。

発注して納品されたのを見たときは、「おぉ、サーバーでもストレージでもスイッチでもFireWallでもない、なんか新しい機材だ」と胸をときめかせていました。この後で起きる惨事も知らずに……
なにをしてしまったか
ロードバランサーの追加にあたっての要件はこうです。
- インターネットからDMZに設置してある新規サービスCへのWWWサーバーへのトラフィックをロードバランサー機器を使用し負荷分散する
- すでに構成済みのDMZネットワークに追加する。WWWサーバーは構築&設置済み
- そのDMZネットワークでは、既存のサービスA・サービスBを構成するWWWサーバーがすでに稼働している
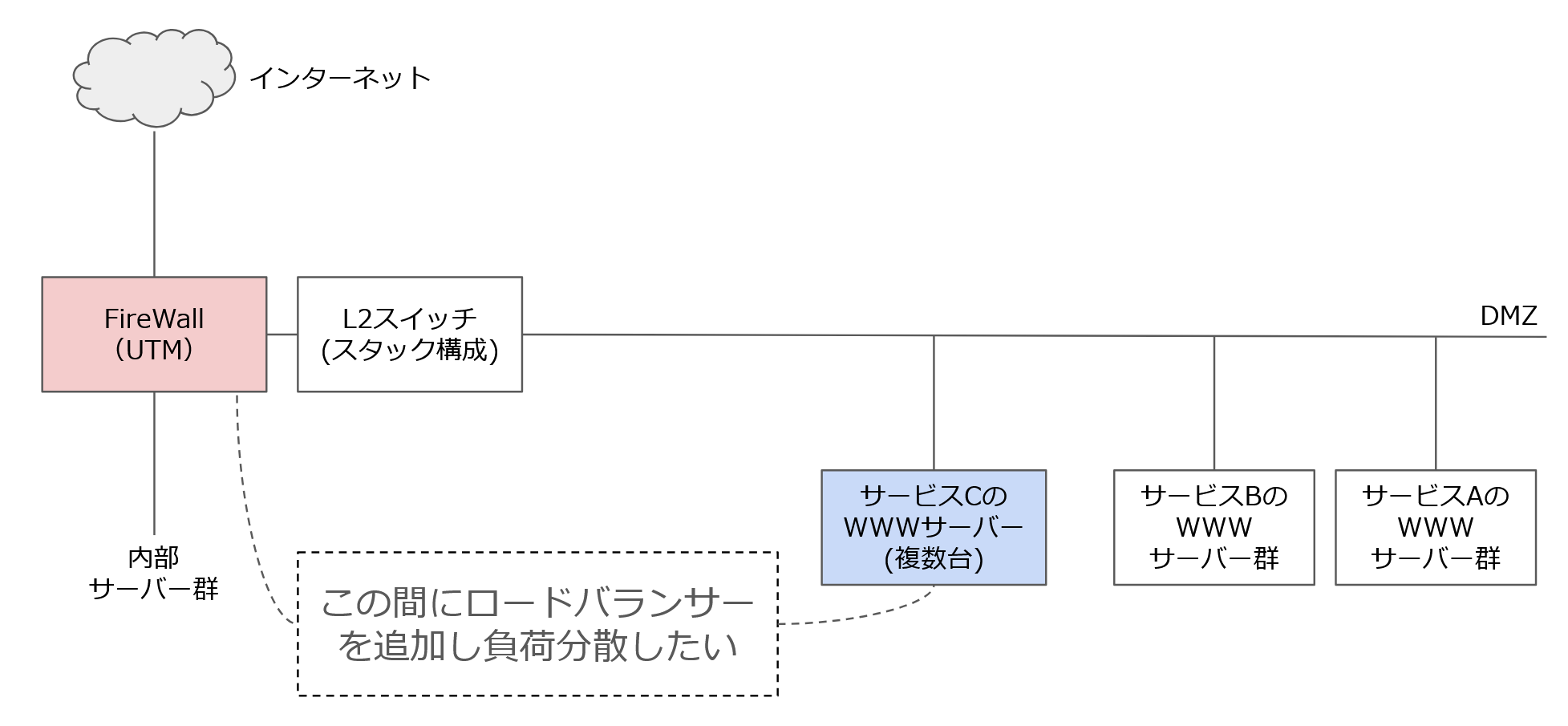
このFireWallとWWWサーバーの間にロードバランサーを挟んでWWWサーバーへのトラフィックを分散したい。さてどう構成すればよいだろうと発注前に、ロードバランサー製造元の入門ガイドを読んで考えていました。その入門ガイドにはこんな構成例が2つ挙げられていました。
ロードバランサー構成例 > L3構成

ロードバランサー構成例 > L2構成

※実際にはロードバランサー2台での冗長構成が書かれているが省略
L3構成のしていることは、FireWallのNATのようにパケット書き換えて外から中へ転送するものと分かりました。L2構成は上と下のネットワークが一緒とはなんだろう、と初見では分かりませんでした。
「あれ?これ、うちのサービスにどう突っこんだらいいんだ?形が合わないぞ」と迷い、「閃いた!」とL2構成を変形して採用すればいいと誤判断しました。 そのとき私はこういう顔をしていたんだと思います。(ここから先、ネットワーク少しでも分かる人は「こいつはアホか」とお思いでしょう。適宜飛ばしてください)

ドカ食いダイスキ! もちづきさん まるよのかもめ 第5話より
「L2構成の上と下は同じセグメントだよね。ならつなげばいいんじゃないかな?そうしたらいまのネットワークにも適用できる」そうだよ……じゃじゃーん
- 既存サービスA、サービスBへは水色の既存の経路へ流す
- 追加するサービスCへは橙色のロードバランサーを挟んだ経路を流す
そう考えたのです。その後
- 発注
- 社内で設定&検証(上の形をした完全の独立したネットワークを構築し疎通確認)
まで終えました。社内へは想定されるリスクとして、構築中のサービスにアクセスできないだけだから気にしなくていい、と間違った判断をもとに営業日日中帯に作業をスケジュールし、いよいよデータセンターに納入し、ラッキング(ラックに搭載すること)&結線する日を迎えました。
こうなった
ラッキングを終えて、ロードバランサー1号機とL2スイッチを結線しました。ネットワークをモニタリングしようと思ったところ、サービスAやサービスBへのネットワーク監視のアラートメールが手元の携帯へ大量にやってきました。確認するとインターネットからサービスAやサービスBにアクセスできません。
想定外で頭が真っ白になり、何が起きたのか分かりませんでした。まずは、この結線が引き金だと判断してロードバランサー1号機を抜線しました。抜線すると2~3分でサービスAやサービスBともに復旧しました。
ロードバランサーは関係ないはずなのに……と考えながらL2スイッチの管理ポートでログを見ると、大量のARPパケットにL2スイッチが耐えられなくなったログがそこにはありました。「あれ、社内では大丈夫だったのにな」と社内にいた別の担当に電話し、検証用のL2スイッチのログを見てもらったところ、電話口の向こうから「パケットがなんかループしてるような記録あるよ。なんか遮断したってある」という声が聞こえます。
なんでループするのか?ロードバランサー製造元の入門ガイドのL2構成を見返すと 「同一ブロードキャストドメイン」 と赤字で書いてあります。

「ロードバランサーのL2構成って、負荷分散対象以外のパケットは素通しするし、ブロードキャストが来たら上から下・下から上に通すのか。L2スイッチのように機能するんだ😨」 とようやく理解しました。ブロードキャストをループさせる構成を作っていたわけです。
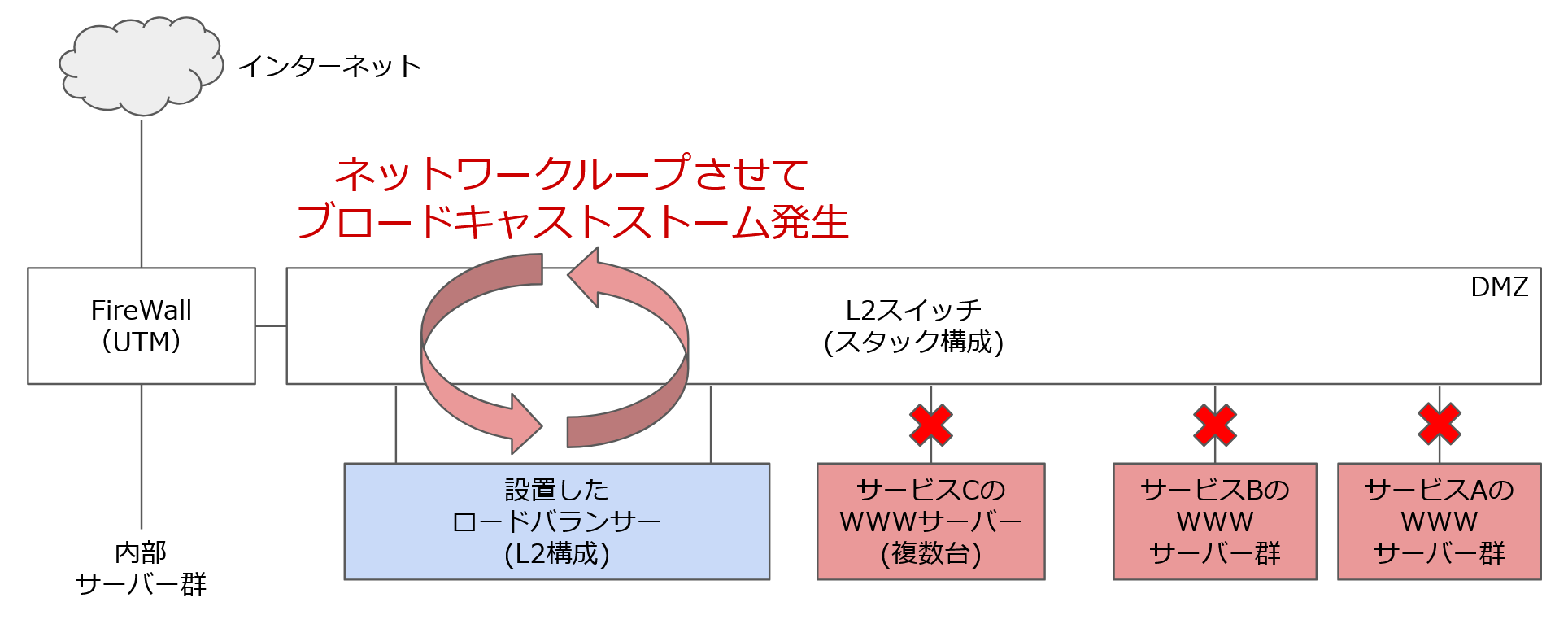
※実際にはロードバランサー2台での冗長構成だが省略
「社内で設定&検証」したときに問題ないように誤判断したのは、独立したネットワークで疎通試験だけのトラフィックであればL2スイッチも耐えられたと、たまたまの結果でした。サービス環境ではトラフィックやIPの数も多く、すぐさまL2スイッチが耐えられない状況に陥り、サービスダウンしたわけです(※スタッカブルスイッチとSTPの相性が悪くてSTPを切っていた。)
その後は、社内へ報告し、障害でご迷惑をおかけしたお客様へも謝罪報告しました。
さらに危ない橋渡ってた
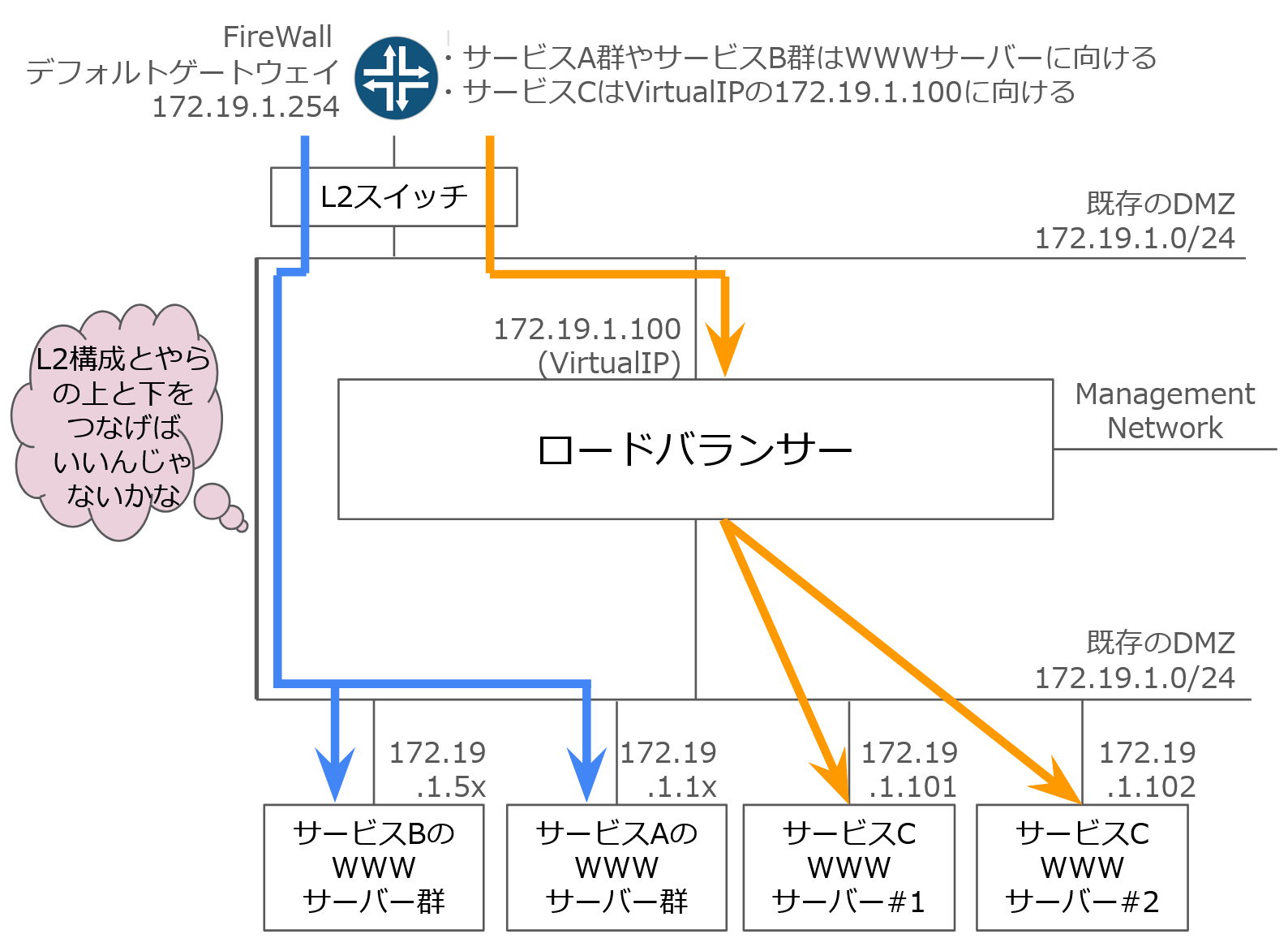
報告と謝罪を終えても、サービスCのスケジュールがずらすことができませんでした。そのためロードバランサーの構成を変更し、再納入することにしました。そのときの構成はこうです。
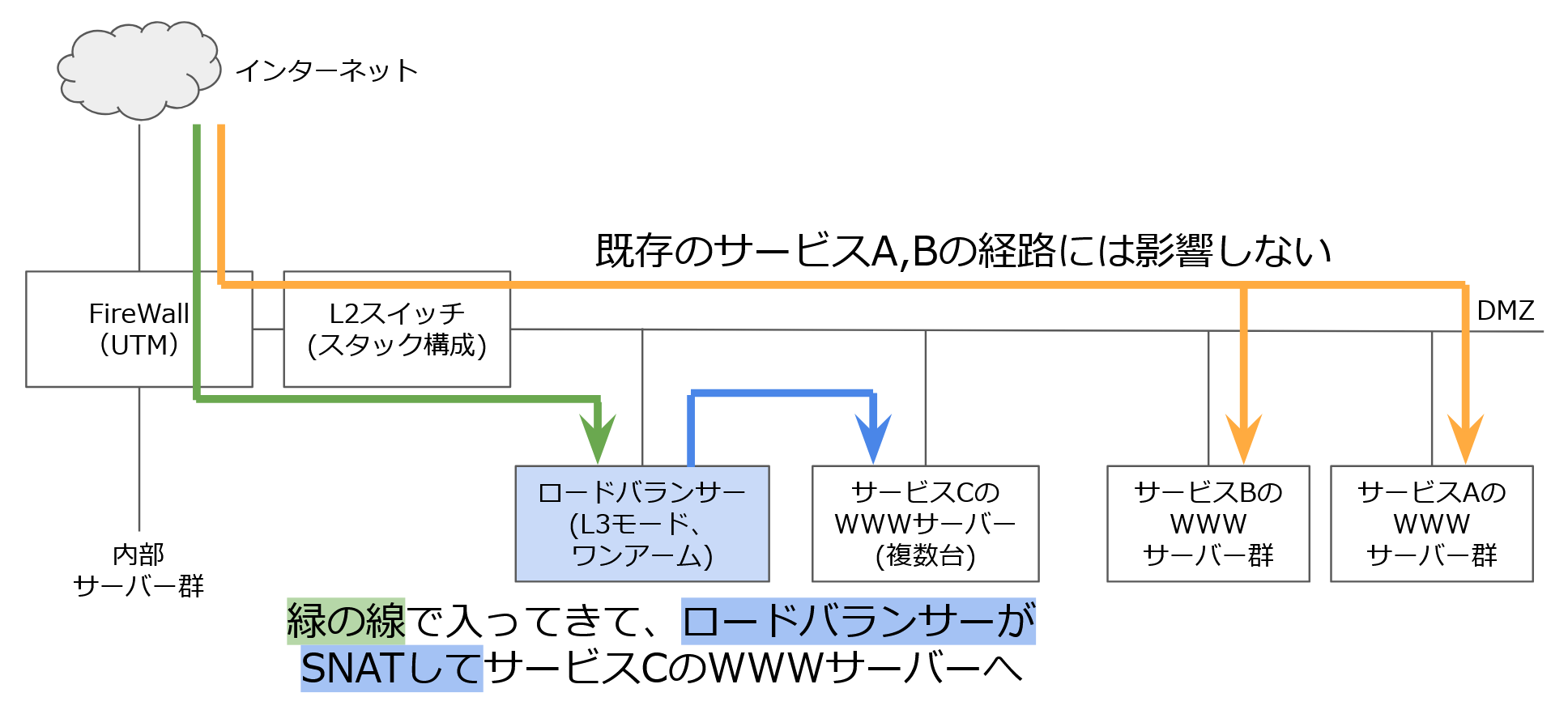
いわゆる「ワンアーム構成」です。ロードバランサーでSNAT(ソースNAT)がかかります。こうすると、WWWサーバーに来るパケットはソースがロードバランサーになりますが、そこは X-Forwarded-For ヘッダをHTTPから取得し、ソースIPと見なせばことが済みます。
問題は、この設定の検証に際して時間がなく、データセンターの休憩室にノートパソコン💻とL2スイッチを持ち込んで行っていたことです。
- 本来は社内できっちり試験した上で再導入なのに、限られた試験項目だけこなして再導入した
- 狭いデータセンターの休憩室を占有する
としていて、「ワンアーム構成」で問題発生しなかったからいいものの、また問題発生させたら私はどうしようとしていたのか、良くないです。
反省点
※超絶あたり前事項はいったん置いておく
上の内容を見た方は、プレッシャー・慢心・リスク軽視、そのような障害防止の一般的な事項がまず対応として浮かぶのではないかと思います。私もそうだと思います。期間についてのプレッシャーを流すだけの交渉力(例えば、ロードバランサーを後から入れる、など)だけでもあれば、この障害防げたかもしれません。
しかし、プレッシャー・慢心・リスク軽視は人や組織に付きものなので、プレッシャーがかかりリスク軽視し慢心していても、この障害を起こさないようにするにはどうしたらいいか、何か特徴はないか、反省点をあげて見ました。
①ネットワーク専任でないのにレイヤ3以前の事項が出てきたら止まれ⛔
ネットワーク専任でない人(プログラマ、カスタマーエンジニア、QA担当、DB担当など)がネットワークをさわったとき、レイヤ3(L3)までは分かる傾向があると感じます、私もそうです。ふだん触るので想像しやすいですよね。「IPアドレスαからIPアドレスβへxxxx番あてのTCP,UDP通信があって~~」「IPアドレスとポートを書き換えるNATがうんたらかんたら~~」という説明は、だいたいどの方面のITエンジニアも通じます。
しかし、L3を支えるL2,L1層や代表IPを決めるVRRP,動的ルーティングのBGPはふだん意識しないし触る機会がない分、抜け落ちやすい。入門ガイドの「L2構成」理解できないまま、その変形版(?)をあてはめようとしました。どこかからどこかへのパケットが来たら素通し、ブロードキャストも素通し、EthernetのARP解決はどうなるの?と自問すれば❌とすぐ分かるのに、気付かなかったのです。
それ以来、L3の通信(IPアドレスとポート)までに、その下のL2層(特にARP)や代表IPがらみ(VRRPなど)、ルーティングプロトコル(BGP, OSPF)、VLAN(ポートVLAN,タグVLAN)の話題が来たら、心の中に「やばい箇所だから止まれ⛔」と自分に警告するようにしています。
また、パブリッククラウドはこの視点から定義すると、「L2以下意識不要でL3まで分かればネットワークを運用できるサービス」と表現できると思います。この点もパブリッククラウドの流行りに拍車をかけているのかもしれません。
②検証用の機器を買おう💲
予算というかお金との兼ね合いですが、検証用の機器は買っておこう、が2番目の反省点です。「さらに危ない橋渡ってた」の項に書いた。急遽ワンアーム構成にして乗り切った箇所、本来は社内に検証用の機器があり(スペックはサービス環境より下でよい。機器のOSは同じにする)そこで性能試験を行ってから再導入するものだと思います。
その後も、このサービスで何かの対応のためロードバランサーの設定変更での対応を思いついても、検証がしづらいので避けてしまうのです(結果、ロードバランサーコマンド1発の事項を、WWWサーバーから先でコストかけて対応する)。リスク回避からは正しいけれど、高価な機材がもったいない。何か新しい機器を購入するときは検証用の機器も買いましょう。そうしないと導入フェーズも運用フェーズ両方困る。当たり前の事項ではあります……
③雇おうインフラエンジニア(ネットワークエンジニア)🧑
反省点①で「ネットワーク専任でない人がネットワークをさわったとき、レイヤ3までは案外分かる」と書きました。ネットワーク専任でない人はネットワークを触らなければいいのではないか、という考えもありますが、私はそう思いません。ネットワーク専任でない人がネットワークをさわったり分かっていた方がいい、分かること・できることは広い方が選択肢が多くなり対応のコストが少なくなります。
しかし、L3の通信以前のレイヤ・箇所を触るとき、インフラエンジニア(ネットワークエンジニア)の方と、そうでない方ではアプローチや力量が違うな、と感じるケースがその後も多々ありました。「テスト担当・カスタマーエンジニア・プログラマ」をキャリアとする私から見ると、その視点の違いは頼もしい。そういうわけで、「専任のインフラ担当がいない」なんてホラーは避けて「雇おうインフラエンジニア(ネットワークエンジニア)」という反省点に至ります。
(パブリッククラウドも根の深いところになると、結局インフラエンジニア(ネットワークエンジニア)の知見なしに早期の解決が難しい事象も目にします。)
おわりに
ここまで、ご高覧ありがとうございました。要は物理のロードバランサーをうん百万かけて導入し、有名なこれを実施した話でございました。

パブリッククラウド全盛期の昨今、このようなやらかしは確実に減った事項と思いますが、「🎵思いよ 逝きなさい~」との気持ち?で書きました。
本番環境などでやらかしちゃった人 Advent Calendar 2024 の 14日目ですが、今年はカレンダーを急遽作ったため、まだ枠がたくさんございます。ご参加お待ちしております。
今年は別のアドベントカレンダーでこんなのも書いてます。良かったらお立ち寄りください。