紹介
オープンデータは、
政府データを、全ての人が自由に加工し、自由に再配布し、自由に商用利用できるようにしていこうとする政治活動です。
現在、政治の透明性や経済の活性化の観点から注目されており、
日本政府も実際にデータを出し始めています。
-> 参考サイト:Open DATA METI | 経済産業省のオープンデータカタログサイト
ただし、日本のオープンデータの問題として、
☆1のオープンデータが出てくるケースが多い事が挙げられます。
オープンデータは、そのオープン性により5つ星で評価されます。
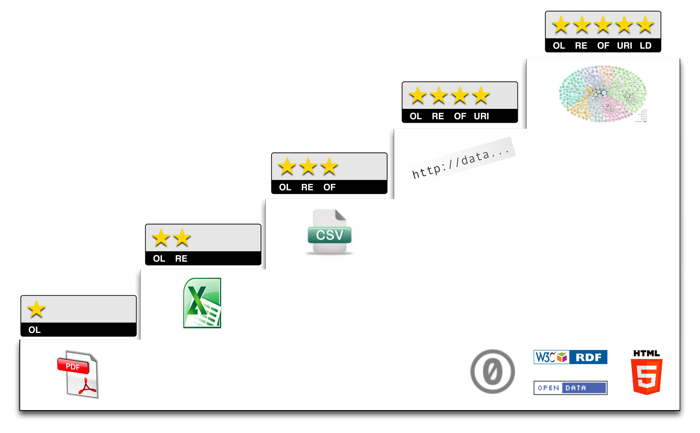
☆1のオープンデータ、つまりPDFは、
構造化データではない為に最もクローズドとされています。
しかし、技術に疎い公務員の方に機械可読性の重要性を説くことは難しく、
それを理解して貰えたとしても機械可読性の為の予算を割り振って貰えるかは微妙です。
現実問題として、PDFに対峙する必要があるのです。
その為のツールとして、PDFMinerが面白いです。
PDFMinerとは、PDFから主に文章情報を取得・解析する為のPythonライブラリです。
Googleトレンドを見ますと、2011年頃から注目されているようです。
PDFからTXT・HTMLへコンバートするアプリは既に存在しますが、
PDFMinerはPDFページの構成要素をツリー構造で管理する機構
(ex.LTPage->LTTextBox->LTTextLine->LTChar,LTText)
を持っており、より細かな調整ができます。
より細かな調整ができるので、例えば、
各省庁の定型的なPDFをTXTにコンバートする為のプログラムを用意するなどができると思います。
インストール手順
PDFMinerのインストールは、下記の手順で行います。
1.Python(2.4 <= version < 3.0)をインストールする。
2.ソースをダウンロード・解凍する。
3.setup.pyをコンソール(端末)で実行する。
python setup.py install
4.インストール後の動作確認をする。
pdf2txt.py samples/simple1.pdf
# コマンド実行後、Hello Worldが連続表示されたらOK。
# -> サンプルPDFからテキストを抽出する事に成功している。
5.CJK統合漢字を扱うための追加インストールをする。
make cmap
python setup.py install
※Win環境はmakeを持たないので、こちらを代わりに実行する。
mkdir pdfminer\cmap
python tools\conv_cmap.py -c B5=cp950 -c UniCNS-UTF8=utf-8 pdfminer\cmap Adobe-CNS1 cmaprsrc\cid2code_Adobe_CNS1.txt
python tools\conv_cmap.py -c GBK-EUC=cp936 -c UniGB-UTF8=utf-8 pdfminer\cmap Adobe-GB1 cmaprsrc\cid2code_Adobe_GB1.txt
python tools\conv_cmap.py -c RKSJ=cp932 -c EUC=euc-jp -c UniJIS-UTF8=utf-8 pdfminer\cmap Adobe-Japan1 cmaprsrc\cid2code_Adobe_Japan1.txt
python tools\conv_cmap.py -c KSC-EUC=euc-kr -c KSC-Johab=johab -c KSCms-UHC=cp949 -c UniKS-UTF8=utf-8 pdfminer\cmap Adobe-Korea1 cmaprsrc\cid2code_Adobe_Korea1.txt
python setup.py install
コマンドラインツール
PDFMinerには2つのコマンドラインツールが付いているようです。
一つは pdf2txt.py 。
指定したPDFをTXT/HTMLにコンバートします。
pdf2txt.py -o output.txt input.pdf
もう一つは dumppdf.py 。
デバッグ用のツールで、擬似XML形式で指定PDFの指定コンテンツを出力します。
又、イメージ等の特定要素だけを抽出するのにも使えます。
dumppdf.py -a foo.pdf
詳しい仕様は元記事をどうぞ。
API
APIの説明資料(英語)のツリー図を読んだ上で、サンプルコードを読むと理解が深まります。
又、より詳しい例示として紹介されているページ(英語)もあるようです。
加えて、既に日本語のブログ記事もあったようです。
つづく
それでは、さっそく使って行ってみましょう。
Enjoy it! Enjoy mining life!