はじめに
※こちらの記事は活動記録になります。
弊社のスキルアップ活動の一環で、表題の活動を行いました。
やりたいこと
最近フリーアドレスになったので、Teamsの社内のカメラで本社の映像から人を検出し、「リアルタイム空席状況」を表示してみたい。
既にある技術
表題にもある通り、人間を検知する仕組みはもう存在する。yoloというPythonライブラリを利用すると、どうやら簡単に動画内の人間を検知できるらしい。
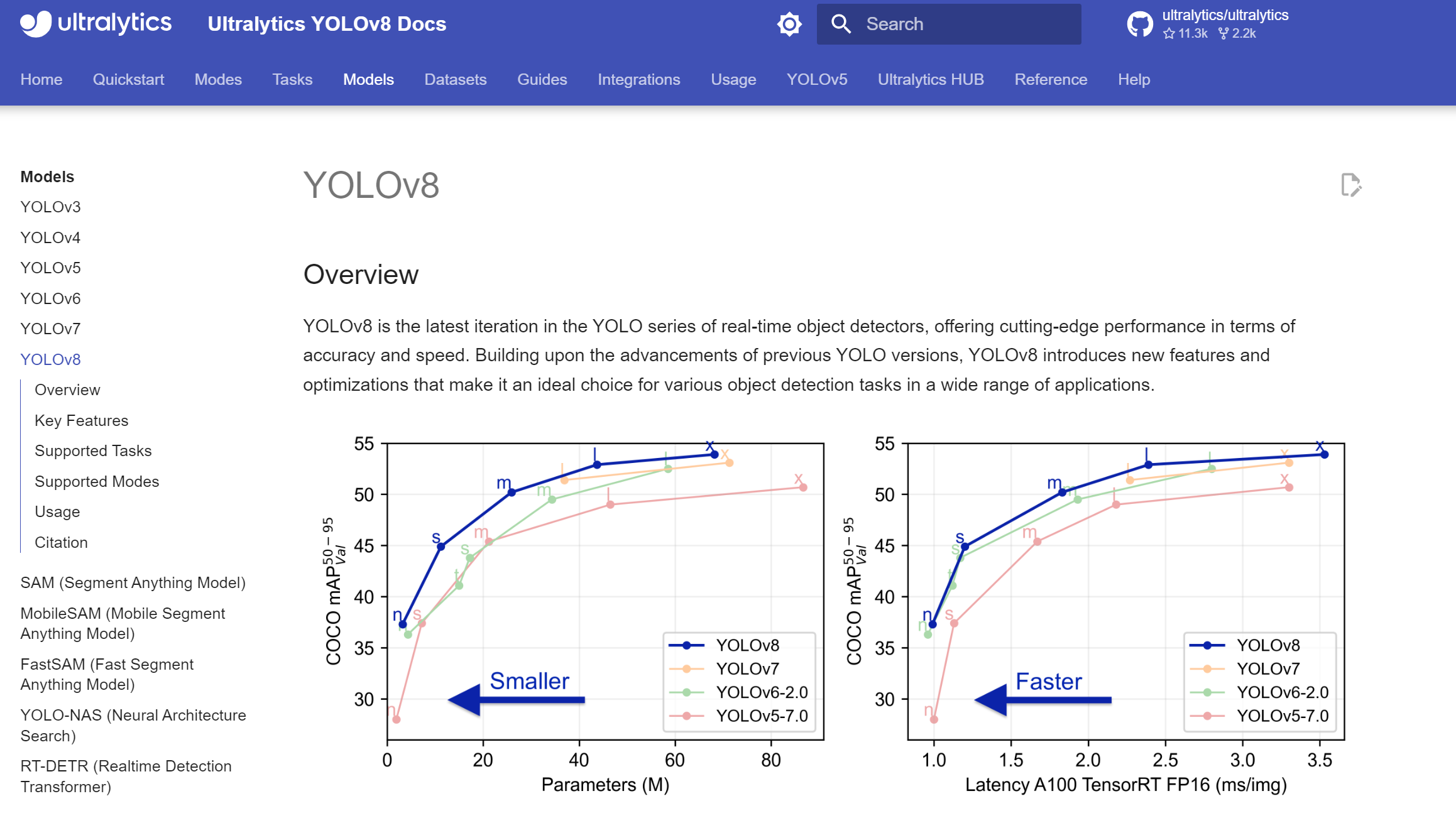
また、人間に限らず、「とにかく動いているもの」を検知するのであれば、高精度のものがネットにたくさん転がっている。
自作する人間検知技術
今回作成したのは、「前景セグメンテーション」という仕組みを用いた「リアルタイム空席状況」プログラム。(Python - openCV)
以下の手順で実施。
➀動画をフレーム単位に分割。
ret, frame = cap.read()
➁フレームを取得して一時保存
➂次のフレームを取得する。
➃前フレームと現フレームの差分を検出
cv2.accumulateWeighted(gray, avg, 0.7)
frameDelta = cv2.absdiff(gray, cv2.convertScaleAbs(avg))
⑤差分の輪郭を抽出し、面積の大きいものを「人間」とみなす
⑥輪郭を抽出して得られる、線に囲まれた「領域」内の重心を算出。
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
contournow = contours[i]
# 輪郭[i]の面積
area = cv2.contourArea(contournow)
if area > 10:
# 輪郭[i]の重心
m = cv2.moments(contournow)
mx,my= int(m["m10"]/m["m00"]) , int(m["m01"]/m["m00"])
# 配列に詰めてマップした座席に渡す
coordinates.append([mx, my+30])
⑦あらかじめ動画内の座席の座標をマッピングしておく。
⑧上記⑥で得られた重心から最も近い座席を紐づける。
⑨座席と紐づいた部分をハイライトさせた座席表を出力する。
⑩上記➁~⑨をループ
のちにノイズ低減のため、③、➃の間でグレースケール変換処理を追加
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
結果
※セキュリティの観点で社内の様子や座席配置はお見せ出来ません。
ある程度は検出できました。が、まだ実用的なラインではないようです。
検証として差分を検出する前に、2つのフレームにフィルタをかけてみました。
フィルタの歪みを重くすると、微量な変化は検知しなくなるので、モニタの軽度なちらつきや影などは検知しなくなりました。
しかし、オフィス内の人間も、毎フレーム大きな動作をしているわけではないので、検知しない人も出ました。
歪みを小さくすると、少しの動きでも人間を検知しますが、人間以外のものも過剰に検知するので、人間以外で検知した領域の面積が大きくなり、誤認識が発生しました。
また今回の動画の場合、座席同士の距離が近く、斜めから撮影しているため、一人の人間で二つの座席が認識してしまうこともしばしば起きる。
まとめ
システムとして良いものが出来たわけではないですが、活動の目的である技術習得は大いに達成できたと思います。最初は天井のシーリングが毎フレーム反応してめちゃくちゃな座標が返ってきていましたが、検出したものがマップした座席と遠すぎると領域が大きくてもスキップする、などの工夫を加えていって、課題解決するたびに力がついたのが実感出来ました。
やってみて思うのですが、前景セグメンテーションは「人間」だけを抽出できるわけではないので、今回のシステムには向いてないかもですね。。。
莫大な時間と予算があれば、ディープラーニングで「人間」の写真を大量に学習させて、openCVで動画内でピンポイントで「人間」だけを検知できると、精度が高く、拡張性もあるシステムが出来そうです。
今回は技術習得が目的だったので、ここら辺にとどめておきます。
今後も社内で行った活動を発信していきます。