only 64bit!!!!!!!!!!!!!!
onlyなわけじゃないがunityでEditorで出て(外でも)AIと遊ぶためはビルドしてwindowsはx86をx86_64にしてビルドしないと動かない
理論略
使い
2018年4~5月にml-agent0.3使う理由:0.2より効率よい
ともかく最新おすすめ、じゃないと多分学習から永遠に死を味会う
理論

カオス理論、カオス力学
少しでも、計算、変数がすこし変わったことで予想、計算むずくなる計算、現象。
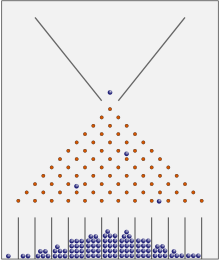 (bean machine,Gauss曲線)
(bean machine,Gauss曲線)
確率論、確率力学
確率的に見ると、確率が予想できる。信じられないがよく考えたら当たり前な結果
情報理論、ゲーム理論
情報理論は結果解析にいい。ゲーム理論は戦略ゲーム作りに参考になる。でも人工知能が脳みたいなもので理解にちょー邪魔。ぶっちゃけカオス確率理論もそう。けど確率とカオスをこんな簡単に知っていてるのはプラス
人工知能の式の概念、意味
POMDP(部分観測マルコフ決定過程、条件付き確率マルコフ決定過程)
Q学習、deep Qネットワーク
Q学習とはQ関数、QシステムでPOMDPから報酬を与え報酬によって行動する機会学習のことです。それをQ()ではなくdeeplearningで起動できるよにしたのがdeep Q networkです。
PPOは普通のdeep Qネットワークです、ただpolicyのparametersを結果として出します
使う理由はA2CなどのAIより早い。

説明
$t$はほぼ全部timestepsを意味します。マルコフ決定過程の概念です。学習が進みパソコンが式の計算を行った場合増える数値。tが1万ならエーゼントが一万判断(計算)を行った。$t()$とあんま書きません。
$\theta、π$などが持ったり$A$と$S$と$R$と書かれるものは
$s$はstates(環境,ml-agentではoutput)
$a$は、Action(エーゼントの行動,ml-agentではinput)
$r$はReward(点数ml-agentでReward)
この3個はマルコフ決定過程の概念です
$\theta$は全パラメタを意味します。policyの全パラメータを意味したい場合$π_\theta$と書きます。数学的最適化の概念です(deeplearningの元になる概念です)https://en.wikipedia.org/wiki/Parametric_model
マルコフ決定過程とはA、S、Rを使って判断するAIです。そのロボットをエーゼント(agent)と言います。
強化学習、Q学習の元です
$P=(’’ |’)$これは確率論の概念です
これは【’】が起こるとその後【’’】が起こる、確率である。という意味です
「パンを2個食うと水を1回飲むのを100%やると
$P=(水を1回飲む率|パンを2個食う)=100%$」
$π()$円周率$π$と素数の個数$π()$じゃありません!!!!!!
$π()$は人工知能の判断です。policyと呼びます。
「$π(殴られた)→殴る$、確率の場合、$π(A|S)→P(A_t|S_t)$、tはtimestep(時間)と言って
左に行動を、右にそのステータスを書きます。
$π(殴る|殴られた)→P(殴る|殴られた)$(P(殴る|殴られた)は殴られ殴る確率です)」
$T()$というものがあって確率論の$P=(’’ |’)$式を意味します。マルコフ決定過程の概念です。あんま使えないから無視していいです。$T(s, a, s')=P(s'_{t+1}|s, a)$のまんま意味です
Transition(状態変化) functionの略。
まとめ

これらは良いpolicyを求めるためいるものです
記号が違うのは研究者達が頭可笑しいだけだからなれてください。(actionとadvantage functionの区別とか)
このまとめを分かると下から書かれているの全部、めちゃめちゃ理解し易くなります。
γは未来の報酬に対する視野そのものです、0.1は今を大事にし1は未来的になります。
ゴール関数はreturnと呼んだりします。
$J$というものもありますが最適(目的)関数です。objective functionと言って数理最適化、ディープラニングの概念です。$G$じゃないです。
https://ja.wikipedia.org/wiki/%E6%95%B0%E7%90%86%E6%9C%80%E9%81%A9%E5%8C%96
数学的最適化
GradientとPPO(Proximal Policy Optimization)(ディープラニングの基本)
ここからはマルコフ決定過程ではなくディープラニングについで話します
Gradient descent(最急降下法)
人工知能でよく出ます
比例式の計算の結果を早く出せます
$ \nabla f=\left( \dfrac {\partial f}{\partial x_{1}}\ldots \dfrac {\partial f}{\partial x_{n}}\right)$
編微分(ニューロンの計算とか)早くします。
編微分が勾配(gradient)つまり関数の傾きですから、
式が分かりやすく正解を出すのですが、それを、正解に早く近つけるよにします。
よく落下するよに見えると言われます。
DEEPLEARNIGは全部これ使います。
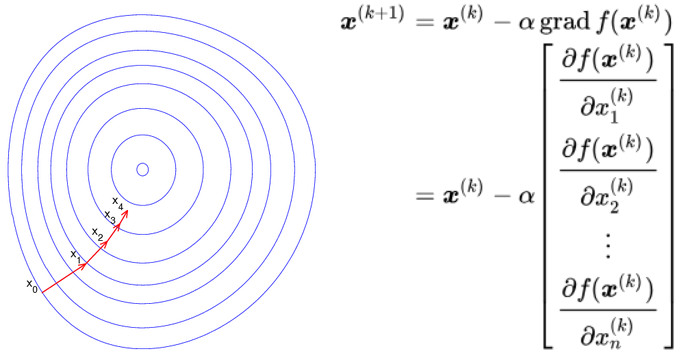
もしくは

iとkは上のnと同じやつじゃありません。下のnと上のnが同じやつです。
バックなんちゃらもgradient descentを簡単に(最適化)しただけです
**Policy Gradient(方策勾配法)(PPOとTRPO)**
ここからはGradientを理解したのでGradientをどう作るかの話をします
$\theta$は全パラメタを意味します。policyの全パラメータを意味したい場合$\pi_\theta$と書きます。数学的最適化概念です(deeplearningの元になる概念です)https://en.wikipedia.org/wiki/Parametric_model
Bellman Equation(ベルマン方程式)
https://ja.wikipedia.org/wiki/%E3%83%99%E3%83%AB%E3%83%9E%E3%83%B3%E6%96%B9%E7%A8%8B%E5%BC%8F
マルコフ決定過程のvalue function達を一つの式に整理したもの。$J$と関係があります。
score function
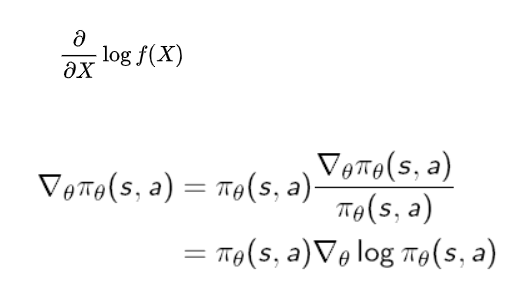
$\nabla_\theta log \pi_\theta$このlogつけただけのやつは
$\nabla_\theta \pi_\theta$をlog化して平均を求められるよにするやつ、logにすることで平均をもとめるよにできます(無意味な計算をしないことでめちゃ早い)
これをscore functionと言います
mathematical model
数学的モデルとは、
普通、関係と変数で表わせることを言います。関係は演算子で。変数は、システムのパラメータを定量化したものです。定量化とは、数えられる量にすることで見易く理解易くすることを意味します。
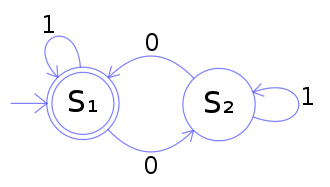
Monte-Carlo learning
ーー
Monte-Carlo Policy Gradeint(Reinforce Algorithm)
Reinforce Algorithmとも言う
Reinforcement learning(強化学習)と関係ない。
Reinforcement learningでよく使う
Actor-CriticとBaseline
policy gradientのPPOとTRPOの学習方がある前にあった学習方達です
全ての学習方には学習できて出力する結果が違います(PPOの場合policyそのもの出力)
PPOとTRPOがより効率がいいとされてますが、たまに場合によっては違います。
objective functionとpenalty(PPOとTRPO)
Shannon entropyとCross entropy(CLIP)(情報理論概念)
PPOとTRPOの要点です。
よくCLIP関数と言ったりします。
ーー
一体、何を学習するのですか?(多分一番重要)
人工知能は式がどっても簡単です(1個のパセプトロンをめちゃ増やして値のgradientの低い値を求め加速化を求めるアルゴリズム)。
が、他の理論とは少し違う学問となります。
生物学がもとでもあって
私達はひとつの生物をなでなでする感覚を味あえるし、ほかの研究では人工知能が新しい方法で
例えば数を数えるのを発見したなど思考に近い何かをしたりします。
それが人工知能の必要なところであります
哲学と学習環境
ーー
これで全人工知能の説明部分は完了です
ml-agent
ハイパーパラメータ
※eは指数表記です。0の数ですe5の場合x00000
※e-1は0.1のかけです0.1×0.1は0.01ですe-5の場合0.0000x
Gamma
gamma将来の報酬の割引率に相当します。これは、エージェントが可能な報酬に、どのくらいの注意を払うべきかの値です。遠い将来に報酬を準備するために代理人が現在行動している状況では、この値は大きくなければならない。報酬がより即時である場合は、報酬がより小さくなることがあります。
代表的な範囲:0.8-0.995
Lambda
lambdGAElambda(Generalized Advantage Estimation )を計算する際に使用されるパラメータに相当します。これは、更新された値の価値を推定するときにエージェントが現在の値の推定にどれほど依存しているかととのことと考えるのができます。低い値は、現在の値の推定値(バイアスが高い場合が多い)に依存することに対応し、高い値は、環境で受け取った実際の報酬(分散が高い可能性がある)に多く依存することに対応します。このパラメータは両者の間のトレードオフを提供し、
正しい値はより安定したトレーニングプロセスにつながります。
代表的な範囲:0.9-0.95
Buffer Size
buffer_sizeは、モデルの学習や更新を行う前にどれだけのデータ(エージェント観察、行動、得られた報酬)を収集するか、に相当します。これはbatch_sizeの倍数にする必要があります。
典型的に、buffer_sizeが大きいほど、より安定したトレーニングになります。
代表的な範囲:2048-409600
Batch Size
batch_sizeは、gradient decent update(最急降下法)の1回の反復に使用された経験の数です。これはいつもbuffer_sizeより、ずっと小さくする必要があります。continuousのaction spaceでこの値は大きくなければなりません(1000秒程度)。Discreteのaction spaceを使用している場合は、この値を小さくする必要があります(10秒単位)。
代表的な範囲(Continuous(連続)):512-5120
代表的な範囲(Discrete(離散)):32-512
Number of Epochs
num_epochは、gradientに経験バッファを通過する回数です。これを大きくするほど、batch_sizeを大きくすることができます。これを減らすと、より安定した更新が保証されますが、学習は遅くなります。
代表的な範囲:3-10
Learning Rate(学習率、 学習速度とも言う)
learning_rateは、gradient更新ステップの強度に対応する。トレーニングが不安定で報酬が一貫して増加しない場合、これは一様、減少するはずです。
代表的な範囲:1e-5-1e-3
※eは指数表記です。0の数ですe+5の場合x00000
※e-1は0.1のかけです0.1×0.1は0.01ですe-5の場合0.0000x
Time Horizon
time_horizonエクスペリエンスバッファに追加する前に、エージェントごとに収集する経験のステップ数に対応します。エピソードの終了前に、この制限に達すると、エージェントのcurrent stateから、全体報酬を予測し、そのため、値の価値推定が使用される。で、このパラメータの値は、より偏ってはいないが、分散変動推定値が高く、より偏っていて、変動の少ない推定値(短い時間の地平線)との間で乖離されます。
エピソード内で、報酬が頻繁に発生する場合、またはエピソードが非常に大きい場合、より少ない数がより理想的な場合があります。この値は、エージェントのアクションのシーケンス内のすべての重要な動作をキャプチャするのに十分な大きさでなければなりません。
代表的な範囲:32-2048
Max Steps
max_steps訓練プロセス中に実行されるシミュレーションのいくつのステップ(フレームスキップによって乗算されるか)に対応する。より複雑な問題の場合は、この値を大きくする必要があります。
代表的な範囲:5e5-1e7
Beta
betaエントロピーの正則化の強さに対応し、政策を「よりランダム」にする。これにより、エージェントはトレーニング中に行動空間を適切に探索することができます。これを増やすと、よりランダムなアクションが取られます。これは、エントロピー(TensorBoardから測定可能)が報酬の増加とともに徐々に減少するように調整する必要があります。エントロピーがあまりにも急速に低下する場合は、増加しbetaます。エントロピーがあまりにもゆっくりと低下する場合、減少しbetaます。
代表的な範囲:1e-4-1e-2
Epsilon
epsilon勾配降下更新中の古いポリシーと新しいポリシーとの間の発散の許容閾値に対応する。この値を小さく設定すると、更新がより安定しますが、トレーニングプロセスも遅くなります。
代表的な範囲:0.1-0.3
Normalize
normalize正規化がベクトル観測入力に適用されるかどうかに対応する。この正規化は、ベクトル観測の実行平均と分散に基づいています。正規化は、複雑な連続制御問題の場合に役立ちますが、より単純な離散制御問題には有害である可能性があります。
Number of Layers
num_layers観察入力の後、または視覚的観察のCNN符号化後にいくつの隠れ層が存在するかに対応する。単純な問題の場合、より少ないレイヤーでより迅速かつ効率的に訓練する可能性が高くなります。より複雑な制御問題には、より多くのレイヤーが必要になる場合があります。
典型的な範囲:1-3
Hidden Units
hidden_unitsニューラルネットワークの完全に接続された各層内にいくつのユニットがあるかに対応する。正しい行動が観察入力の直接的な組み合わせである単純な問題については、これは小さくすべきである。アクションが観測変数間の非常に複雑な相互作用である問題については、これはもっと大きくなるはずです。
代表的な範囲:32-512
(オプション)*反復的*ニューラルネットワークのハイパーパラメータ、RNN
Recurrent Neural Network Hyperparameters
以下のハイパーパラメータはuse_recurrentをtrueに設定されている場合にのみ使用されます。
Sequence Length
sequence_lengthトレーニング中にネットワークを通過した一連の経験の長さに対応する。これは、エージェントが時間の経過とともに覚えておく必要がある情報をキャプチャするのに十分な時間である必要があります。たとえば、エージェントがオブジェクトの速度を記憶する必要がある場合、これは小さな値になります。エピソードの開始時に一度だけ与えられた情報をエージェントが覚えておく必要がある場合、これはより大きな値にする必要があります。
代表的な範囲:4-128
Memory Size
memory_sizeリカレントニューラルネットワークの隠れ状態を格納するために使用される浮動小数点数の配列のサイズに対応する。この値は4の倍数でなければなりません。また、タスクを正常に完了するためにエージェントが覚えておく必要がある情報の量に応じて増減する必要があります。
代表的な範囲:64-512
学習統計
tensorboardを使うため用意されたもの(ml-agentの開発者さんがtensorboardに用意してくれたもの)
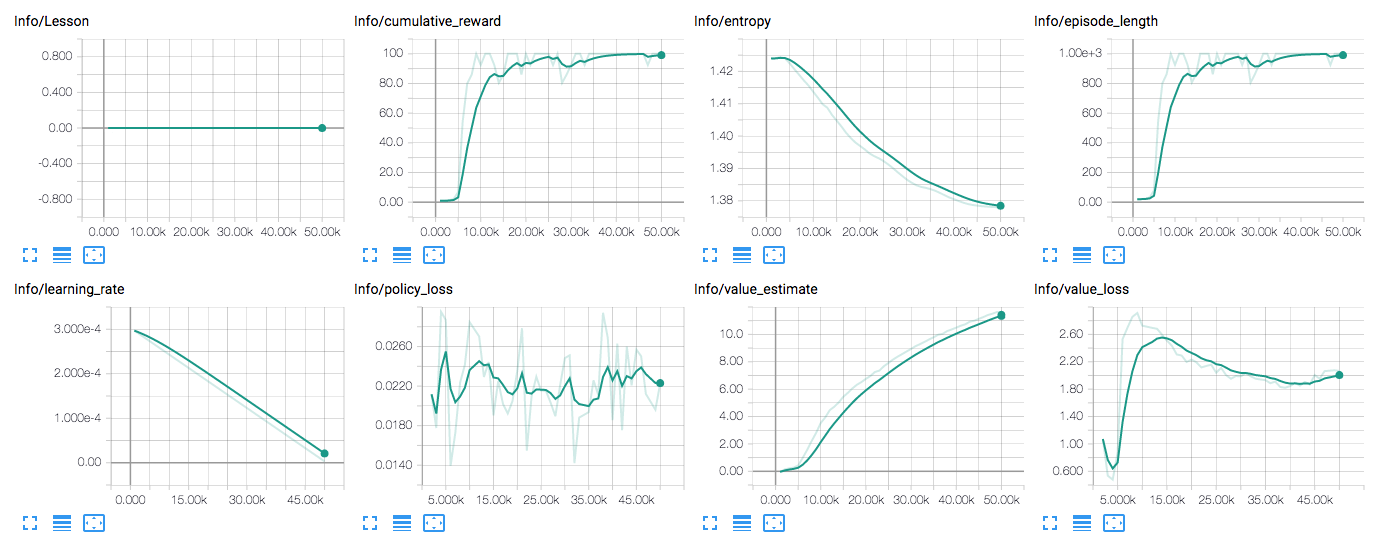
Cumulative Reward
報酬の一般的な傾向は、時間とともに一貫して増加するはずです。小さな浮き沈みが予想される。タスクの複雑さによっては、トレーニングプロセスの何百万分の一ステップまで報酬が大幅に増加することはありません。
Entropy
これは、brainの決定がどれほどランダムであるかに対応します。これはトレーニング中に一貫して減少するはずです。それがあまりにも早く減少するか、まったく変化しない場合betaは、調整する必要があります(個別のアクションスペースを使用する場合)。
Learning Rate
これは、線形スケジュールで時間とともに減少します。
Policy Loss
これらの値は、トレーニングとともに振動します。oscillateです。
モニターとかで、Policy Lossで間違っているか、AIがなんかよくない方向で行動しているか、を見れる値
Value Estimate
これらの値は報酬とともに増加するはずです。これらは、ある時点でエージェントが予測する将来の報酬の量に相当します。
Value Loss
これらの値は、報酬が増えるにつれて増加し、報酬が安定すると減少するはずです。
そこまで頭に置いとくことでもないんだが、ゲームもキーしらないとクソゲーだし読む方がよい
学習とコマンドとpython
コマンドとはwindows,mac(os x)などに基本用意られているものでコマンドプロンプトをコントロールします
Anacondaの場合Anaconda promptなどを使います。
コマンドの中からcdというものがあって移動する位置を操作できる。
c:>のようコマンドには必ず位置とかがいる。そのコマンドには位置を設定できるようcdは用意られてる。cdコマンドとは位置を変えるコマンドである。
c:>cd c:\unko c:のうんこフォルダに移動します
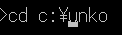
結果
c:\unko>
こういうのがコマンド。このよな命令が出来るどころ(ウィンドウとか)をコマンドプロンプトって言います(コンソールとも言う)
(pythonをサーチすると)pythonの全pyファイルはコマンドプロンプトで起動できます。
それを(cdコマンドなどを使って)ml-agentの学習起動用pyファイルがいる位置に変えよ
ml agent pythonファイルで使えるコマンド一覧
--curriculum=<file> - カリキュラムのトレーニングのレッスンを定義するためのカリキュラムJSONファイルを指定します。詳細については、カリキュラムのトレーニングを参照してください。
--keep-checkpoints=<n> - 保持するモデルチェックポイントの最大数を指定します。
チェックポイントは、save-freqオプションで指定されたステップ数の後に保存されます。
チェックポイントの最大数に達すると、新しいチェックポイントを保存する時、最も古いチェックポイントは、削除されて行きます。デフォルトは5です。
--lesson=<n> - カリキュラムを練習する時、どのレッスンを始めるかを指定する。デフォルトは0です。
--load - 設定されている場合、学習コードは、設定された(あるいは前、訓練された)モデルをロードしてニューラルネットワークを初期化します。つまり、学習データのロードのことです。
学習コードはモデルを検索しますpython/models/< run-id >/(トレーニング終了時にモデルを保存する場所)。設定されていない場合(デフォルト)、ニューラルネットワークは、ランダムに初期化され、既存のモデルはロードしません。
--run-id=<path> - トレーニング実行ごとに識別子(識別するやつのを)を指定します。この識別子は、訓練されたモデルおよび要約の統計情報が保存されているサブディレクトリと、保存されたモデル自体の名前を付けるために使用されます。デフォルトのIDは "ppo"です。TensorBoardを使用してトレーニングの統計を表示する場合、トレーニングの実行ごとに一意の実行IDを常に設定します。(同じIDを持つすべての実行の統計は、同じセッションによって生成されたものと同じように結合されます)。
--save-freq=<n> トレーニング中にモデルを保存する頻度(ステップ単位)です。デフォルトは50000です。
--seed=<n> - トレーニングコードで使用される乱数ジェネレータのシードとして使用する数値を指定します。
--slow - 通常のゲーム速度でUnity環境を実行するには、このオプションに指定します。
この--slowモードでは、アカデミーの推論設定で指定されたタイムスケールとターゲットフレームレートが使用されます。
デフォルトでは、トレーニングはアカデミーのトレーニング設定で指定された速度で実行されます。アカデミーのプロパティを参照してください。
--train - モデルをトレーニングするか、inference modeでのみ実行するかを指定します。トレーニングの際は、常に--trainオプションを使用してください。
--worker-id=<n> - 複数のトレーニング環境を同時に実行している場合は、それぞれに一意のワーカーID番号を割り当てます。worker-idは、learn.pyの現在のインスタンスとUnity環境のExternalCommunicatorオブジェクトの間に開かれた通信ポートに追加されます。デフォルトは0です。
--docker-target-name=<dt> - カリキュラム、実行ファイル、モデルファイルを格納するDockerボリューム。Dockerを使用したい時使いましょ。
Dockerの使用を参照してください。https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Using-Docker.md Using Docker For ML-Agents
Learn.pyは
上のコマンド達と
trainer_config.yamlファイル
この二つのパラメータで
学習を行うよになっています
学習はコマンドプロンプトでlearn.pyもしくはmlagentの学習pyファイルがいる位置に移動して
これらを書きます
新しく学習する
python learn.py <Unityのexeをビルドしたフォルダ> --run-id=<学習データをセーブするフォルダ(フォルダないと自動で作成される)> --train

ロード、上書き(--loadつけただけです)
python learn.py <Unityのexeをビルドしたフォルダ> --run-id=<学習データをセーブするフォルダ(フォルダないと自動で作成される)> --train --load
<>は消して書きます、unkoフォルダが作成され学習データが保存されます。
ロードの時注意:PPOの時の学習セーブデータでImitation学習(模倣学習)を学習するとエラーが出ます。模倣学習→PPOもそうです。
2人ブレインに戦わせたりは関係ありません、ブレインだけ学習変えたりしないといいです。これ以外、
他のはちゃんと出来ます。学習するステータス、アクションを変えたりもできます。
でもスペースの個数を変えると当たり前にエラーになります。
trainer_config.yaml
| ** Setting ** | Description | Applies To Trainer |
|---|---|---|
| batch_size | gradient descentの各反復における経験の数。 | PPO, BC |
| batches_per_epoch | 模倣学習では、モデルをトレーニングする前に収集するトレーニングサンプルのバッチ数。 | BC |
| beta | エントロピーの正則化の強さ。 | PPO, BC |
| brain_to_imitate | 模倣学習のために、模倣するBrainコンポーネントを含むGameObjectの名前。 | BC |
| buffer_size | ポリシーモデルを更新する前に収集するエクスペリエンスの数。 | PPO, BC |
| epsilon | トレーニング中にポリシーがどの程度速く進化するかに影響します。 | PPO, BC |
| gamma | Generalized Advantage Estimator(GAE)の報酬割引率。 | PPO |
| hidden_units | ニューラルネットワークの隠れ層の単位数。 | PPO, BC |
| lambd | 正則化パラメータ。 | PPO |
| learning_rate | 勾配降下の初期学習率。 | PPO, BC |
| max_steps | トレーニングセッション中に実行するシミュレーションステップの最大数。 | PPO, BC |
| memory_size | エージェントが保持しなければならないメモリのサイズ。リカレントニューラルネットワークによるトレーニングに使用されます。リカレントニューラルネットワークの使用を参照してください。 | PPO, BC |
| normalize | 観測値を自動的に正規化するかどうか。 | PPO, BC |
| num_epoch | gradient descent 最適化(optimization)を実行するときに経験バッファを通過させるパスの数。 | PPO, BC |
| num_layers | ニューラルネットワークの隠れ層の数。 | PPO, BC |
| sequence_length | トレーニング中に一連の経験が必要である期間を定義します。リカレントニューラルネットワークによるトレーニングにのみ使用されます。リカレントニューラルネットワークの使用を参照してください。 | PPO, BC |
| summary_freq | トレーニング統計を保存する頻度。これは、TensorBoardによって示されるデータポイントの数を決定します。 | PPO, BC |
| time_horizon | エクスペリエンスバッファに追加する前にエージェントごとに収集する経験のステップ数。 | PPO, BC |
| trainer | 実行するトレーニングのタイプ: "ppo"または "imitation"。 | PPO, BC |
| use_recurrent | Recurrentニューラルネットワークを使用してトレーニングします。リカレントニューラルネットワークの使用を参照してください。 | PPO, BC |
| ** PPO = Proximal Policy Optimization, BC = Behavioral Cloning (Imitation)) ** | ||
| ** PPO = Proximal Policy Optimization, BC = Behavioral Cloning (Imitation)) ** |
おつカレー