はじめに
Amazon CloudWatch Logsのサブスクリプションフィルターは、ログ出力された情報をほぼリアルタイムに他のサービスに連携できる便利な機能だ。AWS Lambdaとの連携も簡単に行えるため、ログ出力を契機とした非同期処理モデルを容易に実装可能にしてくれる。使いこなせればアプリケーション開発の幅が拡がるため、アーキテクチャのデザインパターンの抽斗に追加しておきたい。
今回はこのAmazon CloudWatch LogsのサブスクリプションフィルターをTerraformでお手軽に構築する。
なお、本記事の前提知識は、以下の通り。
- (Must)AWS+Terraformの基本的な知識
- (Want)Amazon Aurora(PostgreSQL互換)の基本的な知識
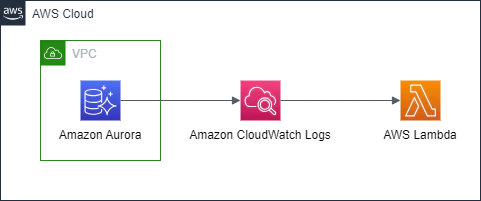
今回は、下図のような構成で、「Amazon Aurora(PostgreSQL互換)のデータベース更新に関するクエリログからAmazon CloudWatchのログストリームに配信したログ」を例題として扱う。このため、後者のAmazon Aurora(PostgreSQL互換)の初歩的な知識があると呑み込みが早くなると考える。
また、DBのテーブルは以下のような定義の「従業員テーブル」を準備している。
CREATE TABLE employee (
id char(5) PRIMARY KEY,
name CHAR(20) NOT NULL,
age integer,
update_dt timestamp
);
Amazon Aurora(PostgreSQL互換)のクエリログの配信
以下のAWS re:Postの記事を参考にクエリログを有効化していく。
AWS re:Postの記事では、DDLと、いわゆるスロークエリを両方出力するようなケースを想定して書いている。記事内容の記載では分かりにくいが、それぞれ独立した設定で、
-
log_statementは実行時間に関係なく出力するクエリの種類を指定する -
log_min_duration_statementはlog_statementで指定していない種類でも、この設定値以上の時間がかかった時にクエリを出力する
というものであるため、それぞれの設定の意味を理解しておこう。
TerraformのAWS Providerのaws_db_parameter_groupに以下の設定を入れる。
resource "aws_db_parameter_group" "example" {
# (中略)
+ parameter {
+ apply_method = "pending-reboot"
+ name = "log_statement"
+ value = "mod"
+ }
}
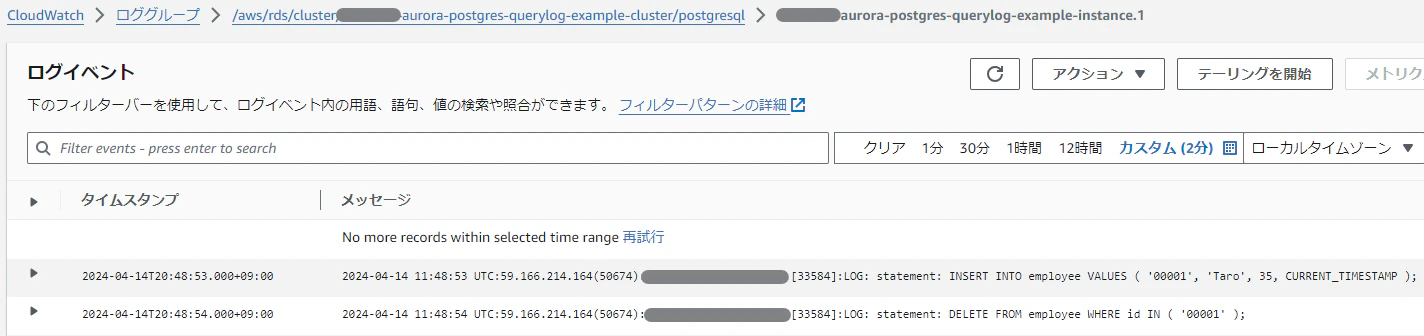
すると、Amazon Aurora(PostgreSQL互換)のログに以下のような情報が出力されるようになる。
2024-04-14 11:45:39 UTC:59.166.214.164(50674):user@db_name:[33584]:LOG: statement: DELETE FROM employee WHERE id IN ( '00001' );
2024-04-14 11:45:43 UTC:59.166.214.164(50674):user@db_name:[33584]:LOG: statement: INSERT INTO employee VALUES ( '00001', 'Taro', 35, CURRENT_TIMESTAMP );
さらに、AWS公式のAmazon Auroraのユーザーガイドを参考にTerraformのAWS Providerのaws_rds_clusterに以下の設定を追加する。ロググループ名は予め決まっているので、名前を合わせよう。
resource "aws_rds_cluster" "example" {
# (中略)
+ enabled_cloudwatch_logs_exports = [
+ "postgresql",
+ ]
}
resource "aws_cloudwatch_log_group" "example_aurora" {
name = "/aws/rds/cluster/${local.aurora_cluster_identifier}/postgresql"
}
これでterraform applyすることで、Amazon CloudWatch LogsにAmazon Aurora(PostgreSQL互換)のログが配信されるようになる。
サブスクリプションフィルターの作成
次に、AWS Lambdaを配信先としたサブスクリプションフィルターを作成していく。
ここでは、一旦すべてのログを配信するようにfilter_patternを設定する。
resource "aws_cloudwatch_log_subscription_filter" "example" {
name = local.subscription_filter_name
log_group_name = aws_cloudwatch_log_group.example_aurora.name
destination_arn = aws_lambda_function.example.arn
filter_pattern = " "
}
AWS Lambdaは以下のように作成しておく。
data "archive_file" "example" {
type = "zip"
source_dir = "../scripts/example"
output_path = "../outputs/example.zip"
}
resource "aws_lambda_function" "example" {
depends_on = [
aws_cloudwatch_log_group.lambda,
]
function_name = local.lambda_function_name
filename = data.archive_file.example.output_path
role = aws_iam_role.lambda.arn
handler = "example.lambda_handler"
source_code_hash = data.archive_file.example.output_base64sha256
runtime = "python3.10"
memory_size = 128
timeout = 30
}
resource "aws_cloudwatch_log_group" "example_lambda" {
name = "/aws/lambda/${local.lambda_function_name}"
}
resource "aws_iam_role" "lambda" {
name = local.iam_lambda_role_name
assume_role_policy = data.aws_iam_policy_document.lambda_assume.json
}
data "aws_iam_policy_document" "lambda_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"lambda.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy" "lambda_custom" {
name = local.iam_lambda_policy_name
role = aws_iam_role.lambda.id
policy = data.aws_iam_policy_document.lambda_custom.json
}
data "aws_iam_policy_document" "lambda_custom" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
]
resources = [
aws_cloudwatch_log_group.lambda.arn,
"${aws_cloudwatch_log_group.example_lambda.arn}:log-stream:*",
]
}
}
さらに、CloudWatch LogsのサブスクリプションフィルターがLambdaを実行できるように、リソースベースポリシーを設定しておこう。
data "aws_region" "current" {}
resource "aws_lambda_permission" "allow_cloudwatchsubscriptionfilter" {
statement_id = "AllowExecutionFromCloudWatchSubscriptionFilter"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.example.function_name
principal = "logs${data.aws_region.current.name}.amazonaws.com"
source_arn = "${aws_cloudwatch_log_group.example_aurora.arn}:*"
}
AWS Lambdaのスクリプト
スクリプトは今回、以下のように作成する。
どんなイベントが発行されるか確認するため、AWS Lambda公式のユーザーガイドを参考にする。
サブスクリプションフィルターは、Kinesis データストリーム、Lambda、または Kinesis Data Firehose で使用できます。サブスクリプションフィルターを介して宛先サービスに送信されるログは、base64 でエンコードされ、gzip 形式で圧縮されます。
ということで、入ってきたデータは素のままでは読めないので、Base64デコードしたうえでgzipの解凍をする。
さらにイベントデータは複数入ってくることがあるため、ループですべて取得しよう。
残念ながら、イベントソースマッピングのように1回の実行あたりの処理件数を指定することはできないようだ。パラメータが存在しない。
今回、SQLの分析を行いたいため、上記クエリログのサンプルの通り、正規表現ライブラリ(re)を使って、LOG: statement: 以降の文字列を抽出する。なお、エラーハンドリングは雑だがご容赦いただきたい。
import base64
import gzip
import json
import re
def lambda_handler(event, context):
event_json = json.loads(gzip.decompress(base64.b64decode(event['awslogs']['data'])))
for idx, log_event in enumerate(event_json['logEvents']):
m = re.match(r'^.*LOG:\s*statement:\s*(.+)$', log_event['message'])
print('--- ' + context.aws_request_id + ': ' + str(idx) + '---')
print(m.group(1))
return {"statusCode": 200}
これで、AWS Lambdaの出力したログを確認すると、ちゃんとSQL部分だけが抽出できている。

フィルターパターンを改善する
さて、これで動かしていると、たまにLambdaが以下のPythonのエラーで失敗していることがある。
[ERROR] AttributeError: 'NoneType' object has no attribute 'group'
Traceback (most recent call last):
File "/var/task/example.py", line 12, in lambda_handler
print(m.group(1))
これは、例えばログインエラーで出力されるような、LOG: statement: を含まない文字のマッチングができていないことが原因だ。reライブラリのエラーハンドリングをして処理対象外にするというのも一つの手段だが、そうすると、AWS Lambdaの無駄な実行を行ってしまいAWS利用の料金にも影響するため、できる限り無駄打ちしないよう、サブスクリプションフィルターのフィルターパターンでそもそもLambdaを起動しないようにしよう。
フィルターパターンの構文の説明は、以下のAWS CloudWatch Logs公式のユーザーガイドを参照する。
今回は、LOGとstatementいずれも含んだ行を抽出するフィルタを設定する。
resource "aws_cloudwatch_log_subscription_filter" "example" {
name = local.subscription_filter_name
log_group_name = aws_cloudwatch_log_group.example_aurora.name
destination_arn = aws_lambda_function.example.arn
- filter_pattern = " "
+ filter_pattern = "LOG statement"
}
これで、ログイン試行失敗のような余計なエラーは引っかからないようになったはずだ。
おまけ) デッドレターキューを設定する
以下のAmazon CloudWatch Logsのユーザーガイドに記載されている通り、サブスクリプションフィルターのターゲットをAWS Lambdaにする場合、非同期実行であるため、再試行の回数を自由に設定することができない(再試行は2回まで)。
Lambda 関数を作成する前に、生成するログデータのボリュームを計算します。このボリュームを処理できる関数を作成するように注意してください。関数に十分なボリュームがないと、ログストリームはスロットリングされます。Lambda の制限の詳細については、「AWS Lambda の制限」を参照してください。
非同期処理に漏れが発生しないよう、AWS Lambdaにデッドレターキューの設定を追加しよう。
resource "aws_sqs_queue" "lambda_dlq" {
name = local.lambda_dlq_name
kms_master_key_id = "alias/aws/sqs"
kms_data_key_reuse_period_seconds = 300
}
resource "aws_lambda_function" "example" {
# (中略)
+ dead_letter_config {
+ target_arn = aws_sqs_queue.lambda_dlq.arn
+ }
}
data "aws_iam_policy_document" "lambda_custom" {
# (中略)
+ statement {
+ effect = "Allow"
+
+ actions = [
+ "sqs:SendMessage",
+ ]
+
+ resources = [
+ aws_sqs_queue.lambda_dlq.arn,
+ ]
+ }
}
これで、耐障害性の高い非同期処理を実行するアーキテクチャが自動で構築可能になった!