はじめに
ECS+Fargateでサーバレス&運用省エネにシステムを構築しているのだから、やはりここは負荷量に応じた運用負荷も軽減したい。
TerraformでサクッとAutoScaling設定をしてみよう。
なお、本記事ではキャパシティプロバイダは使用しないケースで対応している。
また、マルチAZ構成を前提としてTerraformを書いている。Fargateの前段に配置するELBは、クロスゾーン負荷分散を有効にしておかないと、AutoScalingで1台増設が走ったときに正しく分散されないので注意(クロスゾーン負荷分散はNLBのみデフォルトでOFF)。
ECS+FargateのTerraform設定
今回はこの部分は本筋ではないので割愛する。
自分の過去記事では、↓このあたりが参考になると思う。
Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
上記の通り、マルチAZ前提であるため、タスクの desired_count は2にしておく。
AutoScaling Policyの設定
以下のように、aws_appautoscaling_target と aws_appautoscaling_policy で構成されている。今回は、平均CPU使用率に応じたスケールアウト、スケールインを設定する。
resource "aws_appautoscaling_target" "ecsfargate" {
service_namespace = "ecs"
resource_id = "service/${aws_ecs_cluster.ecsfargate.name}/${aws_ecs_service.ecsfargate_service.name}"
scalable_dimension = "ecs:service:DesiredCount"
min_capacity = 2
max_capacity = 4
}
resource "aws_appautoscaling_policy" "ecsfargate_scale_out" {
name = "scale_out"
policy_type = "StepScaling"
service_namespace = aws_appautoscaling_target.ecsfargate.service_namespace
resource_id = aws_appautoscaling_target.ecsfargate.resource_id
scalable_dimension = aws_appautoscaling_target.ecsfargate.scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Average"
step_adjustment {
metric_interval_lower_bound = 0
scaling_adjustment = 1
}
}
}
resource "aws_appautoscaling_policy" "ecsfargate_scale_in" {
name = "scale_in"
policy_type = "StepScaling"
service_namespace = aws_appautoscaling_target.ecsfargate.service_namespace
resource_id = aws_appautoscaling_target.ecsfargate.resource_id
scalable_dimension = aws_appautoscaling_target.ecsfargate.scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Average"
step_adjustment {
metric_interval_upper_bound = 0
scaling_adjustment = -1
}
}
}
上記が理解できたら、今度は、AutoScaling を発動するための CloudWatchメトリクスのアラームを設定する。
ecsfargate_cpu_high が、ECSのサービスのCPU使用率が75%以上になったときに発動、ecsfargate_cpu_low が、ECSのサービスのCPU使用率が75%以下になったときに発動する。
resource "aws_cloudwatch_metric_alarm" "ecsfargate_cpu_high" {
alarm_name = "cpu_utilization_high"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = "CPUUtilization"
namespace = "AWS/ECS"
period = "60"
statistic = "Average"
threshold = "75"
dimensions = {
ClusterName = aws_ecs_cluster.ecsfargate.name
ServiceName = aws_ecs_service.ecsfargate_service.name
}
alarm_actions = [
aws_appautoscaling_policy.ecsfargate_scale_out.arn
]
}
resource "aws_cloudwatch_metric_alarm" "ecsfargate_cpu_low" {
alarm_name = "cpu_utilization_low"
comparison_operator = "LessThanOrEqualToThreshold"
evaluation_periods = "2"
metric_name = "CPUUtilization"
namespace = "AWS/ECS"
period = "60"
statistic = "Average"
threshold = "25"
dimensions = {
ClusterName = aws_ecs_cluster.ecsfargate.name
ServiceName = aws_ecs_service.ecsfargate_service.name
}
alarm_actions = [
aws_appautoscaling_policy.ecsfargate_scale_in.arn
]
}
設定後の動作
設定すると、以下のようなCloudWatchアラームの設定が入る。
※キャプチャは、実際に負荷を入れてスケールアウトが発動したもの
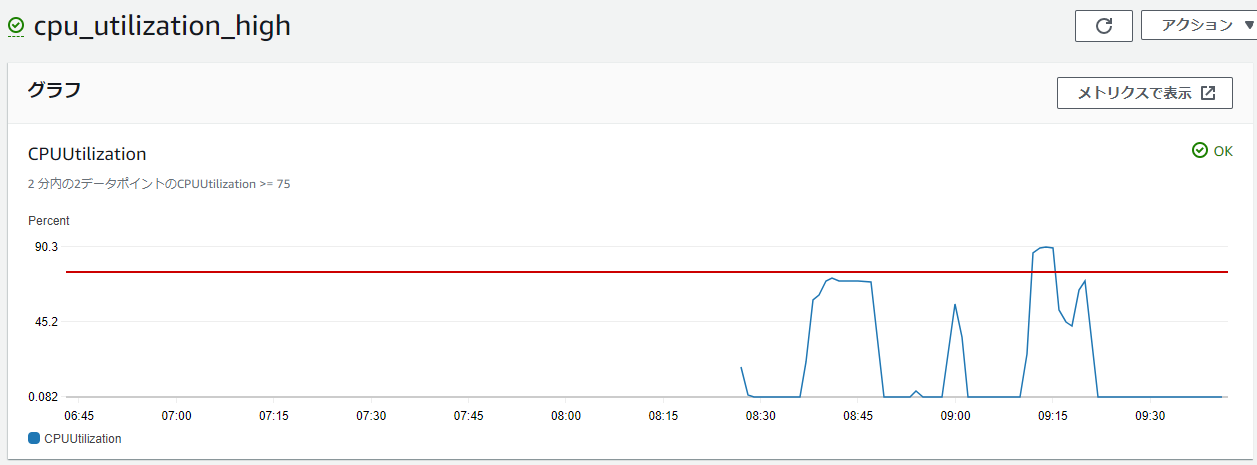
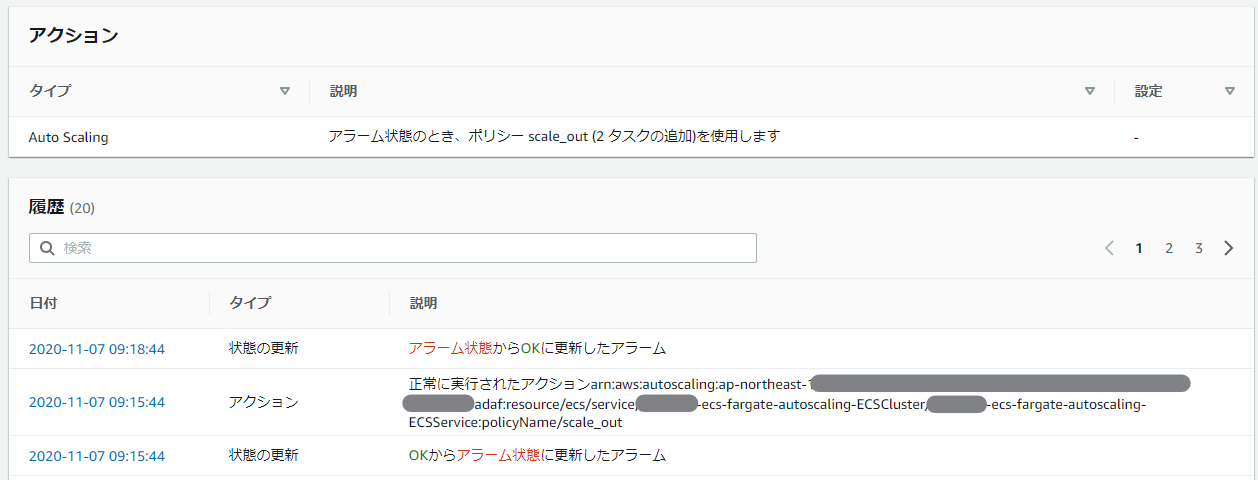
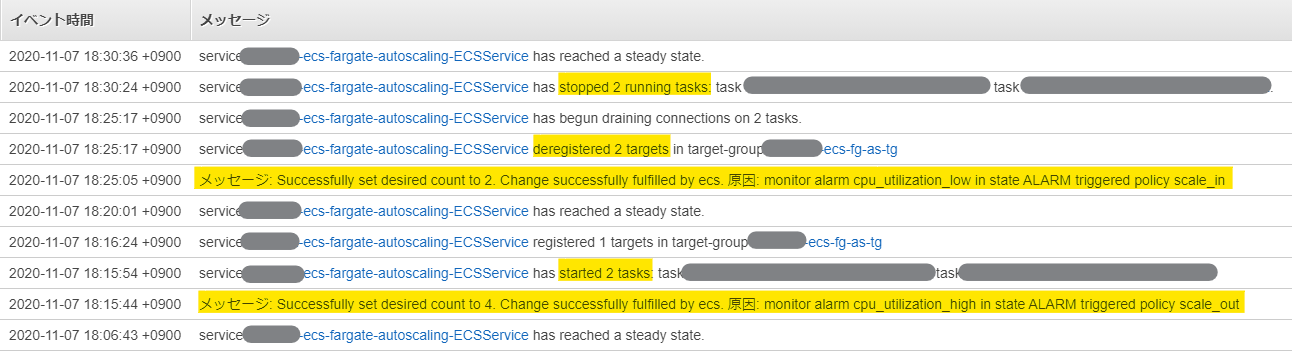
実際にスケールアウトが発動すると、マネージメントコンソールに以下のログが出力される。
一番上の行は、スケールアウトによりECSサービス全体のCPU使用率が下がり、OKの状態になった際のものだ。
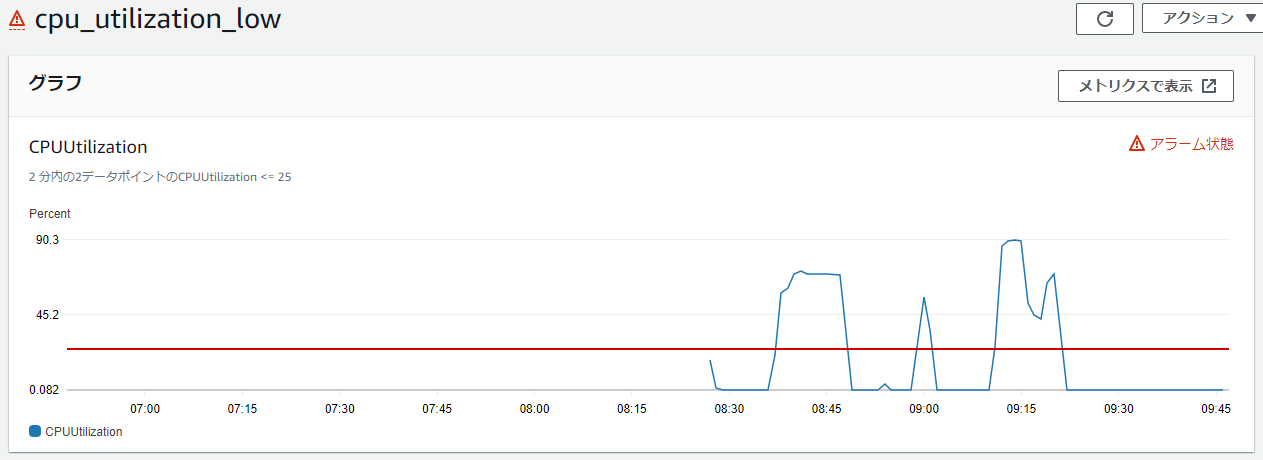
スケールインするときも同様、以下のようになる。
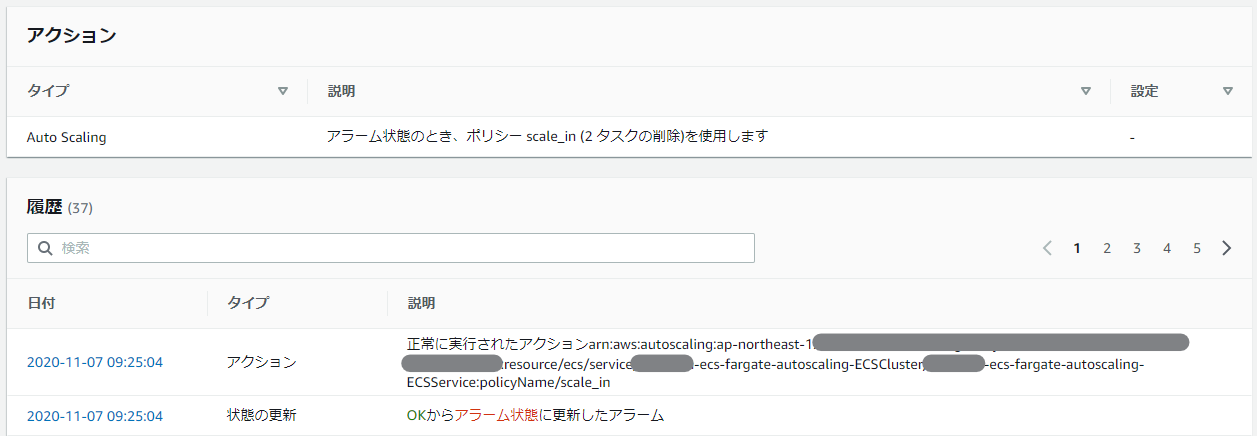
ECSのイベントログも、以下のような感じで、2タスク単位で動いているのが分かる。
これで、トラフィック量に応じて自由にスケールアウト/インできるようになった!