はじめに
Amazon DynamoDB Global Tablesは、Amazon DynamoDBを複数リージョンに分散して保持するようにし、可用性をさらに高めるフルマネージドサービスだ(シングルリージョンで99.99%の可用性のものが、複数リージョンをアクティブ運用することで99.999%まで高められる)。
可用性だけではなく、物理的なロケーションをサービス提供地域に寄せることで、より低レイテンシなサービス提供を可能にできる。
今回は、TerraformでAWS DynamoDB Global Tablesの構築を行い、実際の動作の仕様を確認してみる。
2024年12月時点ではパブリックプレビュー中で東京リージョンでの使用はできないが、さらに、Strong Consistency(強固な整合性)を有効化することで、RPOゼロを求められるDR要件にも対応が可能になる。
今回の検証ではスコープ外としているが、ご了承いただきたい
AWS DynamoDB Global TablesのTerraformコード
今回は、プライマリサイトを東京リージョン、DRサイトを大阪リージョンとしたシステム構築を想定したコードを記載する。Amazon DynamoDBはidをキーとしたシンプルなテーブルと考えていただきたい。
resource "aws_dynamodb_table" "example" {
name = local.dynamodb_table_name
billing_mode = "PAY_PER_REQUEST"
hash_key = "id"
attribute {
name = "id"
type = "S"
}
stream_enabled = true
point_in_time_recovery {
enabled = true
}
replica {
region_name = "ap-northeast-3"
}
}
ポイントは、replicaブロックだ。ここでregion_nameで指定したリージョンにコピーを行う。
stream_enabledは記載しなくても自動でenabledになる。
これは、Amazon DynamoDB Global Tablesが、DynamoDB Streamsの仕組みで動作しているためである(参考リンクは以下)。
server_side_encryptionを設定すると、Terraformではデフォルトでaws/dynamodbのAWSマネージドキーを使用しようとするが、リージョンを跨ぐとキーが変わってしまうため、デフォルトのままでは設定時にエラーになってしまう。
該当の項目を設定しなくても、Amazon DynamoDBはAWS所有キーでの暗号化を行う(逆に言うと「暗号化しない」という設定はできない)ため、これで暗号化要件を満たせるなら問題ないが、他アカウントと共通のキー利用がNGという要件の場合は工夫が必要になるため、注意しよう。
さて、Amazon DynamoDB Global Tablesを設定するだけであればこれで完了だ。
レプリケーションの動作検証
さて、検証するために以下のようなスクリプトを作ってみる。
import boto3
import datetime
import hashlib
import pprint
import sys
argv = {
'aws_region': sys.argv[1],
'ddb_table_name': sys.argv[2],
'ctrl': sys.argv[3],
'id': sys.argv[4],
}
if argv['ctrl'] == 'PUT':
argv['test_data'] = sys.argv[5]
request_id = hashlib.md5(str(datetime.datetime.now()).encode()).hexdigest()
write_date = str(datetime.datetime.now())
dynamodb = boto3.client('dynamodb', region_name = argv['aws_region'])
try:
if argv['ctrl'] == 'PUT':
response = dynamodb.put_item(
TableName = argv['ddb_table_name'],
Item = {
'id': {'S': format(argv['id'], '08s')},
'request_id': {'S': request_id},
'write_aws_region': {'S': argv['aws_region']},
'write_date': {'S': write_date},
'test_data': {'S': argv['test_data']}
},
)
pprint.pprint(response)
elif argv['ctrl'] == 'GET':
response = dynamodb.get_item(
TableName = argv['ddb_table_name'],
Key = {'id': {'S': format(argv['id'], '08s')}}
)
pprint.pprint(response['Item'])
except Exception as error:
print(error)
これを
$ python3 ddbput.py ap-northeast-1 [テーブル名] PUT 00000001 hoge
で呼び出した後にGETしてみると、
$ python3 ddbput.py ap-northeast-1 [テーブル名] GET 00000001
{'id': {'S': '00000001'},
'request_id': {'S': '0c5a9dac4ff6d4c5c4266e184e4aa664'},
'test_data': {'S': 'hoge'},
'write_aws_region': {'S': 'ap-northeast-1'},
'write_date': {'S': '2024-12-22 17:44:02.639810'}}
という出力が得られる。書き込んだリージョンで読み出せるのは当たり前なので、今度は大阪リージョンでも参照してみよう。第二引数をap-northeast-3にすると、boto3のクライアント作成時に該当リージョンにアクセスするようになる。
$ python3 ddbput.py ap-northeast-3 [テーブル名] GET 00000001
{'id': {'S': '00000001'},
'request_id': {'S': '0c5a9dac4ff6d4c5c4266e184e4aa664'},
'test_data': {'S': 'hoge'},
'write_aws_region': {'S': 'ap-northeast-1'},
'write_date': {'S': '2024-12-22 17:44:02.639810'}}
しっかりレプリケーションされていることが確認できた。
次に、大阪リージョンへの書き込みはどうだろうか?
$ python3 ddbput.py ap-northeast-3 [テーブル名] PUT 00000002 hige
レプリカと言いながらもしっかりと大阪リージョンへの書き込みも200応答で正常終了する。
さらに、これを東京/大阪それぞれのリージョンで参照した場合も、以下のように同じ情報が取得できる。
$ python3 ddbput.py ap-northeast-3 [テーブル名] GET 00000002
{'id': {'S': '00000002'},
'request_id': {'S': 'a1f06972113d11b15299077e6d9e175c'},
'test_data': {'S': 'hige'},
'write_aws_region': {'S': 'ap-northeast-3'},
'write_date': {'S': '2024-12-22 17:48:00.155845'}}
$ python3 ddbput.py ap-northeast-1 [テーブル名] GET 00000002
{'id': {'S': '00000002'},
'request_id': {'S': 'a1f06972113d11b15299077e6d9e175c'},
'test_data': {'S': 'hige'},
'write_aws_region': {'S': 'ap-northeast-3'},
'write_date': {'S': '2024-12-22 17:48:00.155845'}}
リージョン障害が発生した際はRoute53でフロントのアプリケーションへのルーティングをDRサイトに向けてあげれば、それ以上は特に操作する必要なく、DRサイトでのサービス提供ができるということだ。
DynamoDB Streamsの動作検証
ここで、Amazon DynamoDB Global TablesはDynamoDB Streamsを使うということで、トリガしたAWS Lambdaがストリームデータをキャプチャできるか確認してみよう。
設定上特に難しい部分はないが、Terraformのdynamodb_tableリソースのreplicaプロパティは複数設定ができ、tfstate上は配列になっているため、tolist(aws_dynamodb_table.example.replica).0.stream_arnと、リスト形式にして参照する必要があるため注意が必要だ。
################################################################################
# Common #
################################################################################
data "archive_file" "example" {
type = "zip"
source_dir = "../scripts/lambda"
output_path = "../outputs/lambda_function.zip"
}
resource "aws_iam_role" "lambda" {
name = local.iam_lambda_role_name
assume_role_policy = data.aws_iam_policy_document.lambda_assume.json
}
data "aws_iam_policy_document" "lambda_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"lambda.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy" "lambda" {
name = local.iam_lambda_policy_name
role = aws_iam_role.lambda.name
policy = data.aws_iam_policy_document.lambda_custom.json
}
data "aws_iam_policy_document" "lambda_custom" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
]
resources = [
aws_cloudwatch_log_group.lambda.arn,
"${aws_cloudwatch_log_group.lambda.arn}:log-stream:*",
aws_cloudwatch_log_group.lambda_osaka.arn,
"${aws_cloudwatch_log_group.lambda_osaka.arn}:log-stream:*",
]
}
statement {
effect = "Allow"
actions = [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams",
]
resources = [
aws_dynamodb_table.example.stream_arn,
tolist(aws_dynamodb_table.example.replica).0.stream_arn,
]
}
}
################################################################################
# Tokyo Region #
################################################################################
resource "aws_lambda_function" "example" {
depends_on = [
aws_cloudwatch_log_group.lambda,
]
function_name = local.lambda_function_name
filename = data.archive_file.example.output_path
role = aws_iam_role.lambda.arn
handler = "lambda_function.lambda_handler"
source_code_hash = data.archive_file.example.output_base64sha256
runtime = "python3.9"
memory_size = 128
timeout = 30
}
resource "aws_cloudwatch_log_group" "lambda" {
name = "/aws/lambda/${local.lambda_function_name}"
retention_in_days = 3
}
resource "aws_lambda_event_source_mapping" "dynamodb" {
event_source_arn = aws_dynamodb_table.example.stream_arn
function_name = aws_lambda_function.example.arn
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
parallelization_factor = 10
}
################################################################################
# Osaka Region #
################################################################################
resource "aws_lambda_function" "example_osaka" {
provider = aws.osaka
depends_on = [
aws_cloudwatch_log_group.lambda_osaka,
]
function_name = local.lambda_function_name
filename = data.archive_file.example.output_path
role = aws_iam_role.lambda.arn
handler = "lambda_function.lambda_handler"
source_code_hash = data.archive_file.example.output_base64sha256
runtime = "python3.9"
memory_size = 128
timeout = 30
}
resource "aws_cloudwatch_log_group" "lambda_osaka" {
provider = aws.osaka
name = "/aws/lambda/${local.lambda_function_name}"
retention_in_days = 3
}
resource "aws_lambda_event_source_mapping" "dynamodb_osaka" {
provider = aws.osaka
event_source_arn = tolist(aws_dynamodb_table.example.replica).0.stream_arn
function_name = aws_lambda_function.example_osaka.arn
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
parallelization_factor = 10
}
スクリプトはこんな感じで、シンプルにイベントをAmazon CloudWatch Logsに出力する。
import pprint
def lambda_handler(event, context):
pprint.pprint(event)
return {
'statusCode': 200,
'isBase64Encoded': 'false'
}
これをterraform applyしてデータを東京リージョンのAmazon DynamoDBにPUTしてみよう。
見やすくするために加工しているが、Amazon CloudWatch Logsには以下の情報が出力される。
{
"Records": [{
"awsRegion": "ap-northeast-1",
"dynamodb": {
"ApproximateCreationDateTime": 1734862316.0,
"Keys": {"id": {"S": "00000001"}},
"NewImage": {
"id": {"S": "00000001"},
"request_id": {"S": "443443144cfc0c5858a0f1b9fdf1aa54"},
"test_data": {"S": "hoge"},
"write_aws_region": {"S": "ap-northeast-1"},
"write_date": {"S": "2024-12-22 19:11:56.273427"}
},
"SequenceNumber": "5274600000000081775862680",
"SizeBytes": 141,
"StreamViewType": "NEW_AND_OLD_IMAGES"
},
"eventID": "7cd1956eaf702f870e5df154eeeb1cdb",
"eventName": "INSERT",
"eventSource": "aws:dynamodb",
"eventSourceARN": "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/dynamodb-globaltable-example-table/stream/2024-12-21T08:56:16.538",
"eventVersion": "1.1"
}]
}
ということで、ちゃんとAWS Lambdaが起動してストリームデータがキャプチャできていることが分かる。
一方で、大阪リージョンのAWS CloudWatch Logsを見てみると、こちらでもストリームが起動している。
{
"Records": [{
"awsRegion": "ap-northeast-3",
"dynamodb": {
"ApproximateCreationDateTime": 1734861604.0,
"Keys": {"id": {"S": "00000001"}},
"NewImage": {
"id": {"S": "00000001"},
"request_id": {"S": "a6a222f71213ffb71b6181d391e5b172"},
"test_data": {"S": "hige"},
"write_aws_region": {"S": "ap-northeast-1"},
"write_date": {"S": "2024-12-22 19:00:03.127508"}
},
"SequenceNumber": "5258400000000016796289931",
"SizeBytes": 141,
"StreamViewType": "NEW_AND_OLD_IMAGES"
},
"eventID": "bcc1b8f90714a4e8add94393f46cefe4",
"eventName": "INSERT",
"eventSource": "aws:dynamodb",
"eventSourceARN": "arn:aws:dynamodb:ap-northeast-3:xxxxxxxxxxxx:table/dynamodb-globaltable-example-table/stream/2024-12-21T08:56:23.858",
"eventVersion": "1.1"
}]
}
DynamoDB Streamsの処理は、非同期で動作させたい処理をトリガするのに二層コミットを不要にするためのサービスであり、非同期処理がDRサイトでも動いてしまうのはいただけない。
しかも、awsRegionの項目があるので、これでどちらのリージョンで初回に発生したトランザクションなのかを見分けられるかと思ったが、レプリカされた大阪リージョンではap-northeast-3が出力されてしまっている。
大阪リージョンはトリガを外してしまえば起動はしなくなるが、それではせっかくDRサイトへの切り替えがシームレスにできる意味がなくなってしまう。
初回に更新したサービス提供サイト(DRサイトではない側)の処理を正しく見分けるためには、アプリケーション側でどちらのリージョンで書き込まないと判別できなそうで、それが今回のデータに付与しているwrite_aws_regionのプロパティである。
では、このプロパティを使用して、以下の通りaws_lambda_event_source_mappingを更新してみよう。
resource "aws_lambda_event_source_mapping" "dynamodb" {
event_source_arn = aws_dynamodb_table.example.stream_arn
function_name = aws_lambda_function.example.arn
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
parallelization_factor = 10
+
+ filter_criteria {
+ filter {
+ pattern = jsonencode({
+ eventName = ["INSERT", "MODIFY"]
+ dynamodb = {
+ NewImage: {
+ write_aws_region: {
+ S: [ data.aws_region.current.name ]
+ }
+ }
+ }
+ })
+ }
+ }
}
resource "aws_lambda_event_source_mapping" "dynamodb_osaka" {
provider = aws.osaka
event_source_arn = tolist(aws_dynamodb_table.example.replica).0.stream_arn
function_name = aws_lambda_function.example_osaka.arn
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
parallelization_factor = 10
+
+ filter_criteria {
+ filter {
+ pattern = jsonencode({
+ eventName = ["INSERT", "MODIFY"]
+ dynamodb = {
+ NewImage: {
+ write_aws_region: {
+ S: [ "ap-northeast-3" ]
+ }
+ }
+ }
+ })
+ }
+ }
}
こうすることで、書き込みリージョンが自分のリージョンと一致しない場合(つまりはレプリケーションのトランザクションである場合)はAWS Lambda関数がトリガされないようになった。
リージョン間障害時の動作検証
続いて、リージョン間の障害が発生してレプリケーションが途切れた時の動作を確認する。
Amazon DynamoDB Global Tablesのリージョン間障害は、AWS Resilience HubのFault Injection Serviceを使うことで動作を疑似ることができる。
Fault Injection Serviceも、以下のようにしてTerraformで動作定義が可能だ。
このシナリオは5分間(PT5M)の障害を発生させる。
Fault Injection Service自体に権限を与えないと動作しないという点は留意しておこう。
resource "aws_fis_experiment_template" "example" {
description = "東京リージョンから大阪リージョンへのアプリケーションネットワークトラフィックをブロックし、クロスリージョンレプリケーションを一時停止する。"
role_arn = aws_iam_role.fis.arn
stop_condition {
source = "none"
}
target {
name = "DynamoDB-Global-Table"
resource_type = "aws:dynamodb:global-table"
resource_arns = [ aws_dynamodb_table.example.arn ]
selection_mode = "ALL"
}
action {
name = "Pause-DynamoDB-Replication"
action_id = "aws:dynamodb:global-table-pause-replication"
target {
key = "Tables"
value = "DynamoDB-Global-Table"
}
parameter {
key = "duration"
value = "PT5M"
}
}
}
resource "aws_iam_role" "fis" {
name = local.iam_fis_role_name
assume_role_policy = data.aws_iam_policy_document.fis_assume.json
}
data "aws_iam_policy_document" "fis_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"fis.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy" "fis" {
name = local.iam_fis_policy_name
role = aws_iam_role.fis.name
policy = data.aws_iam_policy_document.fis_custom.json
}
data "aws_iam_policy_document" "fis_custom" {
statement {
effect = "Allow"
actions = [
"dynamodb:PutResourcePolicy",
"dynamodb:DeleteResourcePolicy",
"dynamodb:GetResourcePolicy",
"dynamodb:DescribeTable",
"tag:GetResources",
]
resources = [
aws_dynamodb_table.example.arn,
aws_dynamodb_table.example.stream_arn,
]
}
}
これをterraform applyして動作させても、東京/大阪それぞれのリージョンに対する書き込みは問題なく行える。レプリケーションができない状況でもそれぞれ独立して動作可能であることが分かる。
あとは、復旧後には再度同期が行われたという点も考慮点になる。
自動で復旧する分には嬉しいが、どれくらいの期間停止に耐えられるかというのは未検証なので、復旧後の動機が必須要件である場合は、動作検証を推奨するので、意識しておいていただきたい。
レプリケーション性能の検証
マルチリージョン間のレプリケーション性能を確認してみる。
スループット
トラフィックは、Amazon DynamoDB Global Tablesの東京リージョン側のフロントにAWS Lambda Function URLsで立てたWebサーバに負荷投入をしている。70スレッドでスレッドあたり10rpsを投入するモデルにしている。
今回、オンデマンドキャパシティで構築を行っているため、急激なトラフィック増に対してはスロットリングのリスクがあったが、Locustの結果ではFailsは0になっていたため、700rps程度であれば難なく処理できるようだ。
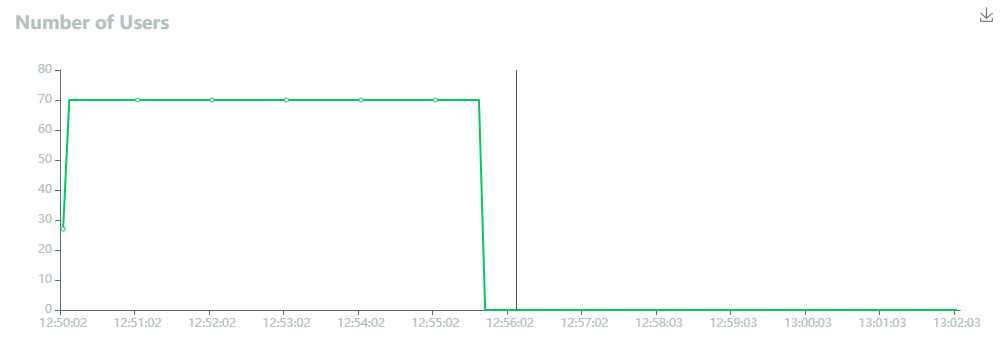
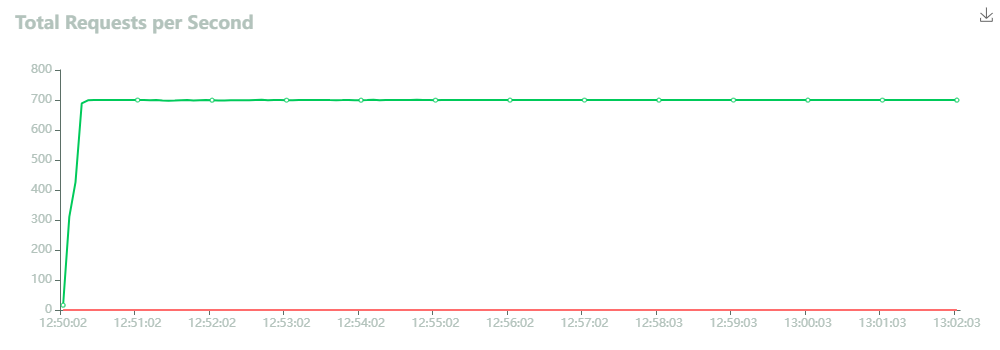
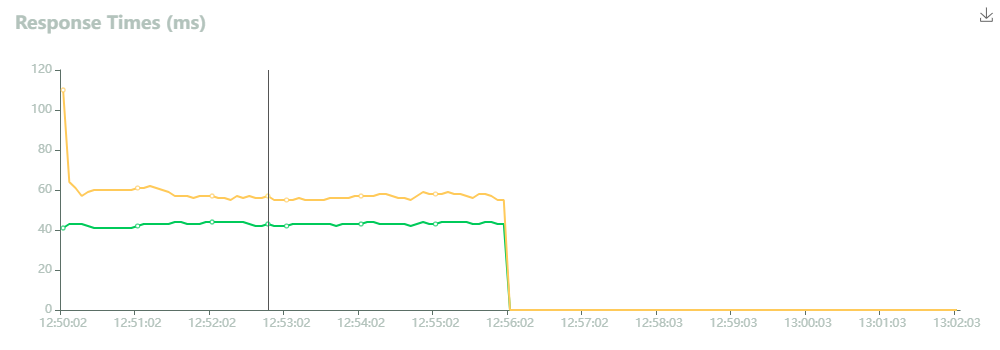
初期だけ、AWS Lambdaのコールドスタートのためにレスポンスタイムが若干悪いが、だいたい40ミリ秒程度で安定している。
レプリケーションのレイテンシ
レプリケーションのレイテンシは、レプリケーションされる大阪リージョン側で確認ができる。
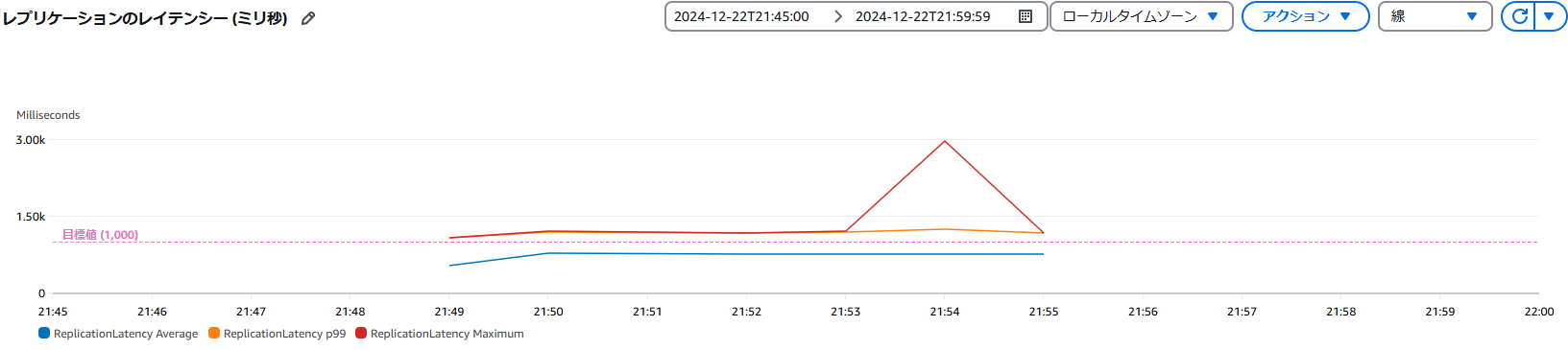
平均であれば、目標値である1秒以内の遅延だが、99%となると1秒を超える。最大は2.5秒程度かかっているが、それでもワークロードの量を考えるとまあまあの性能と言えるだろう。RPOも同程度と言える。
DynamoDB Streamsのメトリクス
また、連動するアプリケーション側でのDynamoDB StreamsのLambda関数についても確認してみる。
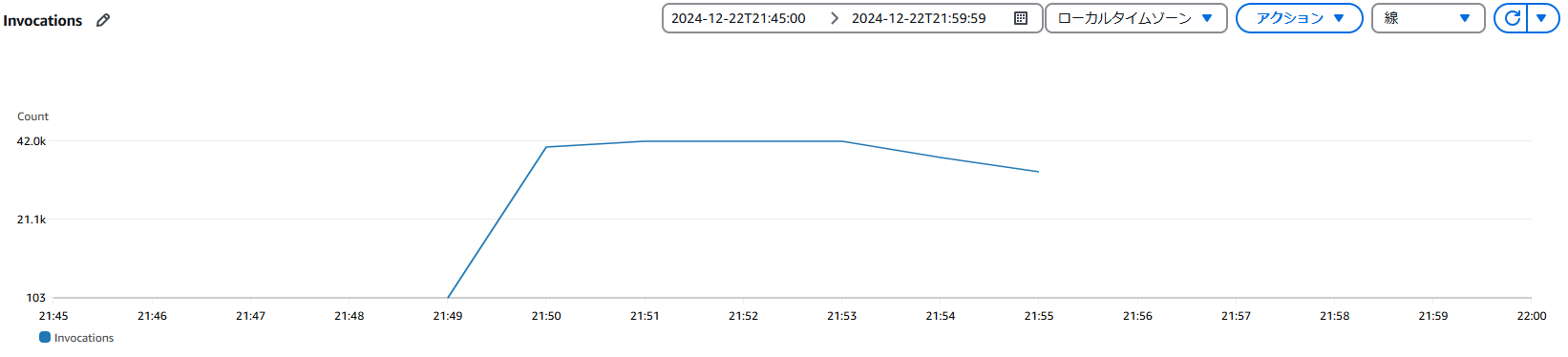
Invocationsの合計値が237,865万程度で、Amazon DynamoDBの「正常に実行された書き込みリクエスト (数)」のメトリクスと合致したため、漏れなく反映されていそうだ。
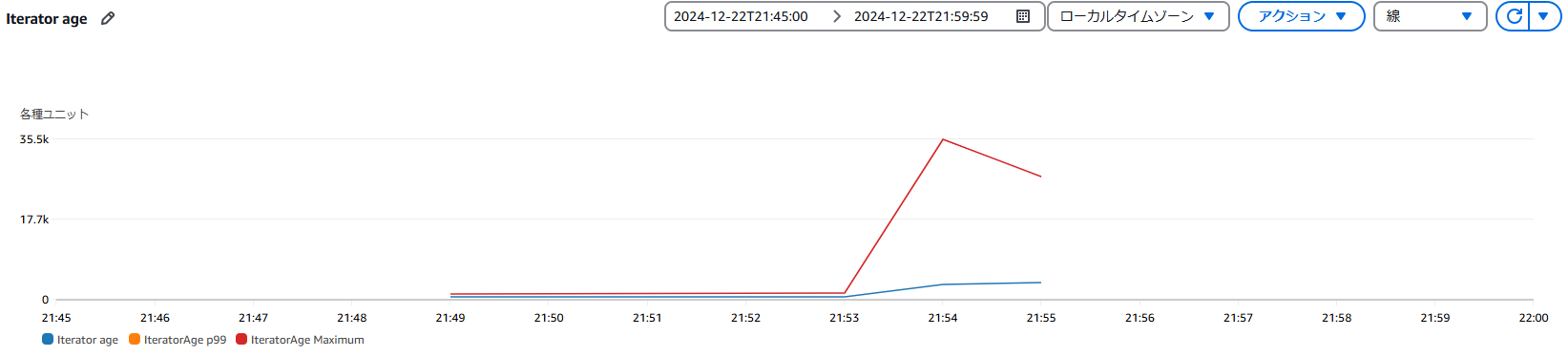
Iterator Ageについては最大で35秒程度かかっている。非同期処理であれば、この程度の遅延は問題にならないだろう。ロストさえなければ充分な性能だろう。
これで、Amazon DynamoDB Global Tablesの仕様に関する理解はだいぶ進んだと言えるはずだ!