はじめに
Amazon AthenaはS3に入ったログをSQLで抽出したり集計したりできる超便利機能。
でも、Terraformで一発で作ろうとするとちょっとクセがあるので、整理をしてみた。
Amazon Athenaに必要なリソース
Amazon Athenaに必要なリソースは以下の5つ。
- ワークグループ
- データベース
- テーブル
- データ
- SQL
だ。データベースに登録するデータはS3に格納しておく必要がある。
ワークスペース+データベースの作成
これはそんなに難しいことはない。Terraformで普通に定義していこう。
################################################################################
# Athena #
################################################################################
resource "aws_athena_workgroup" "example" {
name = local.athena_workgroup_name
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = false
result_configuration {
output_location = "s3://${aws_s3_bucket.athena_output.id}/"
}
}
force_destroy = true
}
resource "aws_athena_database" "example" {
name = local.athena_database_name
bucket = aws_s3_bucket.athena_output.id
force_destroy = true
}
resource "aws_s3_bucket" "athena_output" {
bucket = local.s3_output_bucket_name
acl = "private"
force_destroy = true
}
それぞれのリソースの属性を force_destroy = trueにしているのは、中身が入っていると terraform destroy でエラーが発生するため。壊す必要がない商用のリソース等であれば、付与する必要はない。
テーブルの作成
ここは少し曲者で、Terraform ではテーブルの作成をするSQLを実行することはできない。aws_athena_named_query というリソースはあるが、実行することはできないのと、初回しか実行しないテーブル作成のSQLを保存しておいてもなので、データベース作成時のみ発動する null_resource を活用しよう。
resource "null_resource" "initialize_db" {
provisioner "local-exec" {
command = <<-EOF
aws athena start-query-execution \
--work-group "${aws_athena_workgroup.example.id}" \
--query-execution-context Database="${aws_athena_database.example.id}" \
--query-string "${replace(replace(replace(data.template_file.create_example_table_sql.rendered, "`", "\\`"), "\"", "\\\""), "$", "\\$")}"
EOF
}
}
data "template_file" "create_example_table_sql" {
template = file("../sql/01_create_table.sql")
vars = {
athena_database_name = aws_athena_database.example.id
athena_table_name = local.athena_table_name
input_bucket_name = aws_s3_bucket.athena_input.id
}
}
resource "aws_s3_bucket" "athena_input" {
bucket = local.s3_input_bucket_name
acl = "private"
force_destroy = true
}
CREATE EXTERNAL TABLE IF NOT EXISTS ${athena_database_name}.${athena_table_name} (
`request` STRING,
`remote_addr` STRING,
`time_local` STRING
)
PARTITIONED BY (
`file_datehour` STRING
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
"serialization.format" = "1"
)
LOCATION 's3://${input_bucket_name}/${athena_table_name}/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'projection.enabled'='true',
'projection.file_datehour.type'='date',
'projection.file_datehour.format'='yyyy/MM/dd/HH',
'projection.file_datehour.range'='2021/02/27/00,NOW',
'projection.file_datehour.interval'='1',
'projection.file_datehour.interval.unit'='HOURS',
'storage.location.template'='s3://${input_bucket_name}/${athena_table_name}/$${file_datehour}'
);
なお、Athena は大量のログを扱う際、スキャンに対して料金がかかるため、テーブルの設計が重要になる。
集計をする単位でパーティショニングしておくことで、ログが有効活用できるようになる。
今回は、FireLens で出力されたログを集計することを前提にしたテーブル構成にしてみた。
※FireLens については、こちらの過去記事を参照。
パーティショニングに関する記述が、SQL の TBLPROPERTIES に書かれた部分だ。file_datehour というキーを定義し、PARTITIONED BY で指定を行い、TBLPROPERTIES で詳細を指定するイメージだ。TBLPROPERTIES の射影の設定については、公式のドキュメントが参考になる。
さて、これでデータを投入すれば準備は完了だ。
SQLの実行
Athena のマネージメントコンソールでワークスペースを切り替え……
Query editor でSQLを実行!
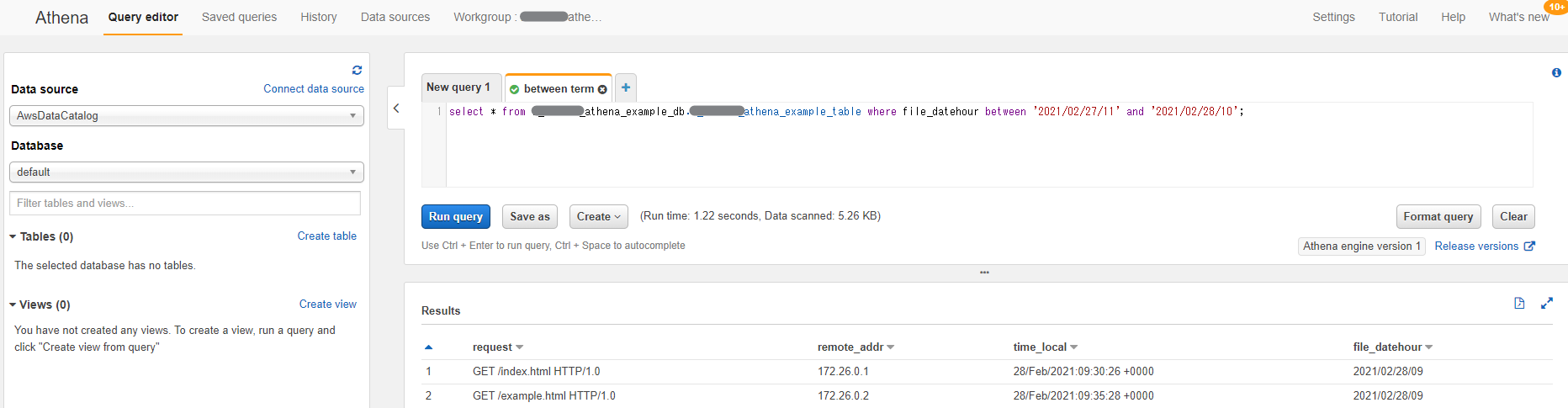
やった!結果が得られた!
抽出結果は、local.s3_output_bucket_name で指定したS3バケットにもCSV形式で保存されている。
何度も実行するようなSQLであれば、aws_athena_named_query で保存しておこう。
resource "aws_athena_named_query" "between_term" {
name = "between term"
workgroup = aws_athena_workgroup.example.id
database = aws_athena_database.example.name
query = "select * from ${aws_athena_database.example.name}.${local.athena_table_name} where file_datehour between '2021/02/27/11' and '2021/02/28/10';"
}
こうしておくと、コンソールから簡単に実行ができる。CLIはちょっと面倒だけど……。

これで、快適なS3ログ解析生活が送れるようになる!