はじめに
AWS Dav Day 2023の以下のスライドを読んでいたら、これまではLambdaやECSタスクで実装していたものをAWS Batchのジョブにしてもなかなか良いのではないかと思って触ってみた。
技術的負債になりかけていた機能をリアーキテクティングしたらめちゃくちゃ改善した話
本記事を読むにあたっての前提知識としては以下のあたりがあれば良い。
- ECS on Fargate等のコンテナ実行環境の基礎知識がある
- Terraformの基礎知識がある
AWS Batchのジョブ実行に必要なリソース
AWS Batchの実行に必要なリソースは、AWS Batchそのもの以外に以下がある。
- コンテナイメージの元ネタになるECRリポジトリ
- セキュリティグループ
- IAMロール(AWS Batchのサービスロール)
- IAMロール(AWS Batchのタスク実行(ジョブ実行)に必要なロール)
- IAMロール(AWS Batchのタスクにアタッチするロール)
- CloudWatch Logsのロググループ(ログ出力する場合のみ)
※なお、VPCは既に作ってある前提。
それぞれコードを準備していこう。
ECRリポジトリ
特に難しいところはない。リソース作成時にイメージのPUSHまで終わらせておきたいなら、null_resourceの中で対応しておこう。
resource "aws_ecr_repository" "batch_job_image" {
name = local.ecr_repository_name
image_tag_mutability = "MUTABLE"
}
data "aws_ecr_authorization_token" "token" {}
resource "null_resource" "image_push" {
provisioner "local-exec" {
command = <<-EOF
docker build ../ -t ${aws_ecr_repository.batch_job_image.repository_url}:latest; \
docker login -u AWS -p ${data.aws_ecr_authorization_token.token.password} ${data.aws_ecr_authorization_token.token.proxy_endpoint}; \
docker push ${aws_ecr_repository.batch_job_image.repository_url}:latest
EOF
}
}
セキュリティグループ
セキュリティグループも特段難しいことはない。今回はアプリケーション要件も特にないが、各種AWSリソースにアクセスするためにegressのポートは開けておく。
resource "aws_security_group" "batch" {
vpc_id = data.aws_vpc.my.id
name = local.security_group_name
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
IAMロール
AWS Batchのサービスロール
resource "aws_iam_role" "batch_service" {
name = local.batch_service_role_name
assume_role_policy = data.aws_iam_policy_document.batch_service_assume.json
}
data "aws_iam_policy_document" "batch_service_assume" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["batch.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role_policy_attachment" "batch_service" {
role = aws_iam_role.batch_service.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBatchServiceRole"
}
AWS Batchのタスク実行(ジョブ実行)に必要なロール
resource "aws_iam_role" "taskexecution" {
name = local.taskexecution_role_name
assume_role_policy = data.aws_iam_policy_document.taskexecution_assume.json
}
data "aws_iam_policy_document" "taskexecution_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"ecs-tasks.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy_attachment" "taskexecution" {
role = aws_iam_role.taskexecution.id
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy"
}
AWS Batchのタスクにアタッチするロール
今回は、DynamoDBにアクセスする機能を持っているコンテナを用意するために、DynamoDBを実行する権限をタスクにアタッチするロールに付与しておく。
resource "aws_iam_role" "batch_job" {
name = local.batch_job_role_name
assume_role_policy = data.aws_iam_policy_document.batch_job_assume.json
}
data "aws_iam_policy_document" "batch_job_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"ecs-tasks.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy" "batch_job" {
role = aws_iam_role.batch_job.id
name = local.batch_job_policy_name
policy = data.aws_iam_policy_document.batch_job_custom.json
}
data "aws_iam_policy_document" "batch_job_custom" {
statement {
effect = "Allow"
actions = [
"dynamodb:PutItem",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"ssmmessages:CreateControlChannel",
"ssmmessages:CreateDataChannel",
"ssmmessages:OpenControlChannel",
"ssmmessages:OpenDataChannel",
]
resources = [
"*",
]
}
}
CloudWatch Logsのロググループ
ログ出力する場合はロググループを作っておこう。
resource "aws_cloudwatch_log_group" "batch_job_loggroup" {
name = local.batch_job_loggroup_name
retention_in_days = 3
}
AWS Batchのリソース
AWS Batchのリソースは以下の3種類の定義が必要になる
- ジョブ定義(aws_batch_job_definition)
- コンピューティング環境(aws_batch_compute_environment)
- ジョブキュー(aws_batch_job_queue)
コンピューティング実行環境に対して、ジョブキューを通してジョブ定義を流し込むイメージをすると分かりやすいだろうか。
それぞれのリソース定義をしていこう。
ジョブ定義
ジョブ定義は以下のように定義する。
Fargateで実行する場合は、type = "container"にして、platform_capabilities = [ "FARGATE" ] にする。
container_propertiesは、ECSのtaskdef.jsonのようなものと考えれば良い。リソース割り当てやログ設定等、が、こちらはDockerで指定しているコマンドを上書きできる(今回はNode.jsのアプリを実行している)。より詳しい設定は、公式のAPIリファレンスを参照。
セキュリティ上の留意点
以下の例ではnetworkConfigurationでassignPublicIp = "ENABLED"としているが、本来はここはDISABLEDにすべきである。ただし、ここをDISABLEDにすると、インターネット経由の通信ができなくなり、コンテナのPull等に失敗する。セキュアに動作させるには、ジョブを動作させるコンピューティング環境のサブネットに、必要なVPCエンドポイントや、NATゲートウェイを設定しよう。このあたりは公式のブログも参照すると良い。
resource "aws_batch_job_definition" "example" {
name = local.batch_job_name
type = "container"
platform_capabilities = [
"FARGATE",
]
container_properties = jsonencode({
command = ["node", "index.js"]
image = aws_ecr_repository.batch_job_image.repository_url
jobRoleArn = aws_iam_role.batch_job.arn
fargatePlatformConfiguration = {
platformVersion = "LATEST"
}
resourceRequirements = [
{
type = "VCPU"
value = "0.25"
},
{
type = "MEMORY"
value = "512"
}
]
executionRoleArn = aws_iam_role.taskexecution.arn
logConfiguration = {
logDriver = "awslogs",
secretOptions = null,
options = {
awslogs-group = aws_cloudwatch_log_group.batch_job_loggroup.name,
awslogs-region = data.aws_region.current.name,
awslogs-stream-prefix = "job",
}
}
networkConfiguration = {
assignPublicIp = "ENABLED"
}
environment : [
{
name = "DYNAMODB_TABLE_NAME",
value = aws_dynamodb_table.example.name
},
]
////////////////////////
// default parameters //
////////////////////////
// ephemeralStorage = {
// sizeInGiB = 20
// }
// instanceType = ""
// linuxParameters = {}
// mountPoints = []
// privileged = true
// readonlyRootFilesystem = true
// secrets = []
// ulimits = []
// user = ""
// volumes = []
})
}
コンピューティング環境
コンピューティング環境も様々な設定が可能だが、ひとまず動かすのであれば以下で良い。
どのコンピューティングタイプを、どのサブネットのどのセキュリティグループで動作させるか。サービスロールに何の権限を与えるかを設定する。
resource "aws_batch_compute_environment" "example" {
depends_on = [
aws_iam_role_policy_attachment.batch_service
]
type = "MANAGED"
compute_environment_name = local.batch_compute_env_name
compute_resources {
type = "FARGATE"
max_vcpus = 16
subnets = flatten([data.aws_subnet_ids.my_vpc.ids])
security_group_ids = [
aws_security_group.batch.id
]
}
service_role = aws_iam_role.batch_service.arn
}
ジョブキュー
ジョブキューも特に難しいことは無いので、以下のように最低限の設定をしておこう。
resource "aws_batch_job_queue" "example" {
name = local.batch_job_queue_name
state = "ENABLED"
priority = 1
compute_environments = [
aws_batch_compute_environment.example.arn,
]
}
これで、実行の準備は整った。
いざ、実行!
実行はコンソールからでもCLIからでも良い。
今回はCLIでの実行方法を例として挙げる。
Terraformのtfstateを参照できる場所で以下を実行しよう。
output "batch_definition_name" {
value = aws_batch_job_definition.example.name
}
output "batch_queue_name" {
value = aws_batch_job_queue.example.name
}
BATCH_DEFINITION_NAME=`terraform output -raw batch_definition_name`
BATCH_QUEUE_NAME=`terraform output -raw batch_queue_name`
aws batch submit-job --job-name [任意のジョブ名] --job-definition ${BATCH_DEFINITION_NAME} --job-queue ${BATCH_QUEUE_NAME}
さて、これで実行して以下のJSONが帰ってきたら起動は完了だ。
{
"jobArn": "arn:aws:batch:ap-northeast-1:XXXXXXXXXXXX:job/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"jobName": "[指定したジョブ名]",
"jobId": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
}
コンソールで実行結果を確認しよう。
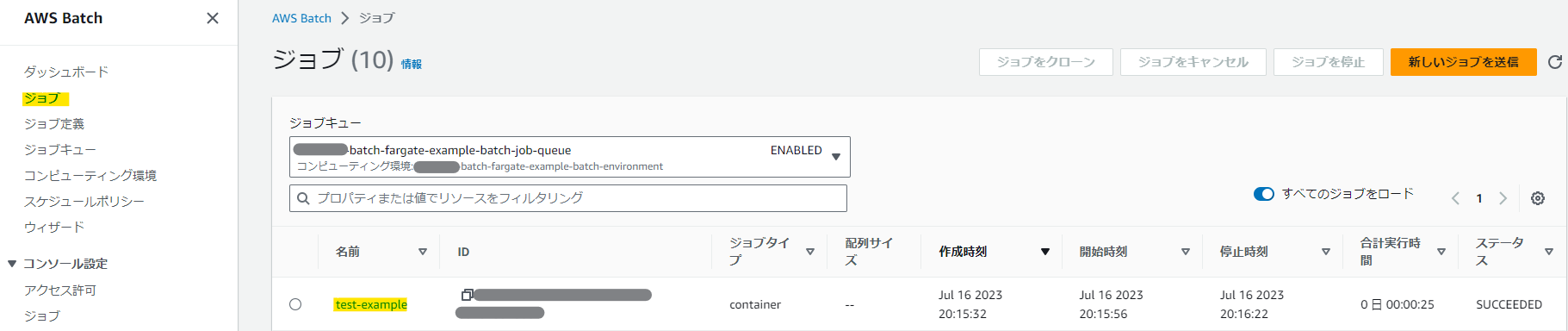

ステータスがSUCCEEDEDになっていれば成功だ!
これでサーバレスでバッチ処理を動作させられるようになった!
次回予告
だが、実際のユースケースを考えた場合、実行失敗時の監視やリトライがまともに動かなくては使い物にならない。
次回は、リトライ方法や、リトライオーバー時のモニタリングの方法を検証していく。