はじめに
Lambdaのイベントソース処理の設定値と動作は複雑でわかりにくい。
しかも、DynamoDB Streams/Kinesis のストリーム系のイベントソース処理と、SQS イベントソース処理では設定値が異なる。
今回は、上記の非同期系処理を適切にリトライするための設計値をまとめる。
また、Terraformで設定する際のリソースと設定値も付記しておこう。
なお、イベントソース処理は動作上は非同期処理なので、Lambdaの非同期処理と勘違いしがちだが、Lambdaの非同期処理とイベントソース処理はそもそも概念が異なるので注意が必要。具体的なサービスについては、開発者ガイドの以下の節を参照していただきたい。
それぞれの機能の具体的な差異の例として、Lambda実行のリトライ/保持期間/DLQの設定について、非同期呼び出しではLambdaの設定が適用され、イベントソースマッピング呼び出しではイベントソース側の設定が適用される。
ストリーム系非同期処理の設計値
ストリーム系イベントソース処理の設計値は、以下の項目が重要になる。
| マネージメントコンソールの設定値 | Terraformリソース | Terraformの設定値 | デフォルト値 |
|---|---|---|---|
| レコードの最長有効期間 | aws_lambda_event_source_mapping | maximum_record_age_in_seconds | -1(無制限) |
| 再試行 | aws_lambda_event_source_mapping | maximum_retry_attempts | -1(無制限) |
| 障害時の送信先 | aws_lambda_event_source_mapping | destination_config - on_failure | 未設定 |
マネージメントコンソールの画面では以下の項目を見ると良い。
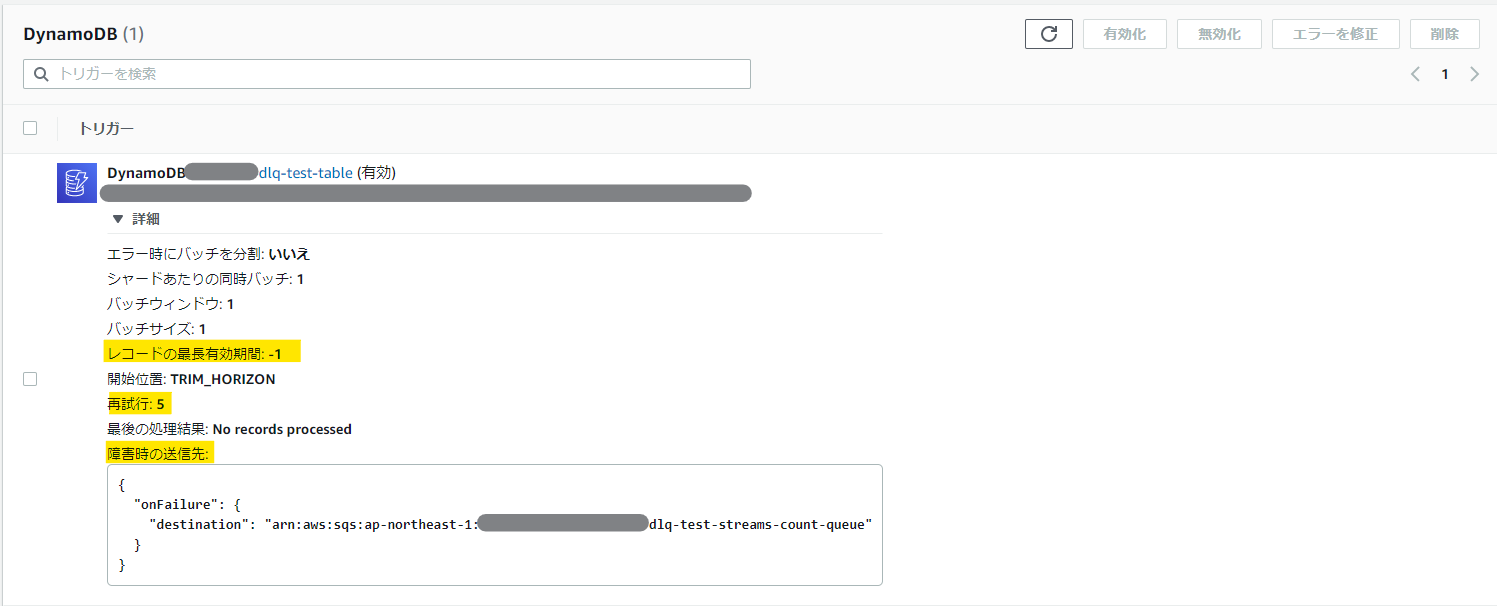
障害時の送信先は、下記のように定義する。なお、本設定を行う場合は、Lambda の IAM ロールに sqs:SendMessage の実行権を付与しておく必要がある。
resource "aws_lambda_event_source_mapping" "example" {
// (中略)
destination_config {
on_failure {
destination_arn = aws_sqs_queue.example.arn
}
}
}
上記のキューは、いわゆるデッドレターキューとは異なる(デッドレターキューは非同期呼び出しの時にLambda側で有効となる設定)ものだ。
maximum_record_age_in_secondsを経過するか、maximum_retry_attemptsの回数を超過してイベントが破棄されたときにキューイングされる。一方で、無限リトライをすると、同一キーの後続処理もろとも詰まってしまうため、リトライポリシーは適切に定めて、ダメなときは諦めて障害時の送信先に後始末を委ねるのが良いだろう。
ログの実装ポリシーをどう設計するか
Lambdaの異常時ログを設計する際、「エラー検知時に出力すれば良い」と考えていると、NullPointerExceptionのように問答無用でプログラムが終了するような例外が発生した際に情報が失われてしまう。かと言って、常に正常ケースでもログを出し続けるのはセキュリティ上の問題も発生し得るし、ログ量が膨大になり障害時解析に支障をきたす可能性がある。
障害時の送信先にはイベント情報が連携されるため、上記のようなケースでも適切に入力情報を取得することができるようになるため、有効に活用していきたい。
さて、障害時の送信先にはどんな情報が連携されてくるのだろうか。
DynamoDB Streamsの場合は以下のような情報がキューイングされる。
{
"requestContext": {
"requestId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"functionArn": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:example-function",
"condition": "RetryAttemptsExhausted",
"approximateInvokeCount": 3
},
"responseContext": {
"statusCode": 200,
"executedVersion": "$LATEST",
"functionError": "Unhandled"
},
"version": "1.0",
"timestamp": "2023-09-24T05:53:08.267Z",
"DDBStreamBatchInfo": {
"shardId": "shardId-xxxxxxxxxxxxxxxxxxxx-xxxxxxxx", ★2
"startSequenceNumber": "000000000000000000001", ★3
"endSequenceNumber": "000000000000000000001",
"approximateArrivalOfFirstRecord": "2023-09-24T05:53:06Z",
"approximateArrivalOfLastRecord": "2023-09-24T05:53:06Z",
"batchSize": 1,
"streamArn": "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/example-table/stream/2023-09-24T04:05:33.235" ★1
}
}
このままだとイベント情報は読めないが、DynamoDBの中身を見ることで情報を取得できる。
aws dynamodbstreams get-shard-iterator --stream-arn '★1のARN' --shard-id '★2のID' --shard-iterator-type AT_SEQUENCE_NUMBER --sequence-number '★3のシーケンス番号'
上記を実行すると、
{
"ShardIterator": "なんか長いイテレータ情報"
}
が取得できるので、このイテレータ情報を
aws dynamodbstreams get-records --shard-iterator 'なんか長いイテレータ情報'
で取得すると、元のイベントソースマッピングで連携された情報を見ることができる。
イベントソースがKinesisの場合も基本的に同様で、KinesisのCLIのget-shard-iteratorとget-recordsを呼び出すことで、Kinesisのストリームにインプットされたイベント情報を参照することが可能だ。
SQSの設計値
SQSによるイベントソース処理の設計値は、以下の項目が重要になる。
| マネージメントコンソールの設定値 | Terraformリソース | Terraformの設定値 | デフォルト値 |
|---|---|---|---|
| タイムアウト | aws_lambda_function | timeout | 3秒 |
| デフォルトの可視性タイムアウト | aws_sqs_queue | visibility_timeout_seconds | 30秒 |
| メッセージ保持期間 | aws_sqs_queue | message_retention_seconds | 345600(4日) |
| 最大受信数 | aws_sqs_queue | redrive_policy - maxReceiveCount | 未設定 |
| デッドレターキュー | aws_sqs_queue | redrive_policy - deadLetterTargetArn | 未設定 |
マネージメントコンソールの画面で関連する部分は以下。
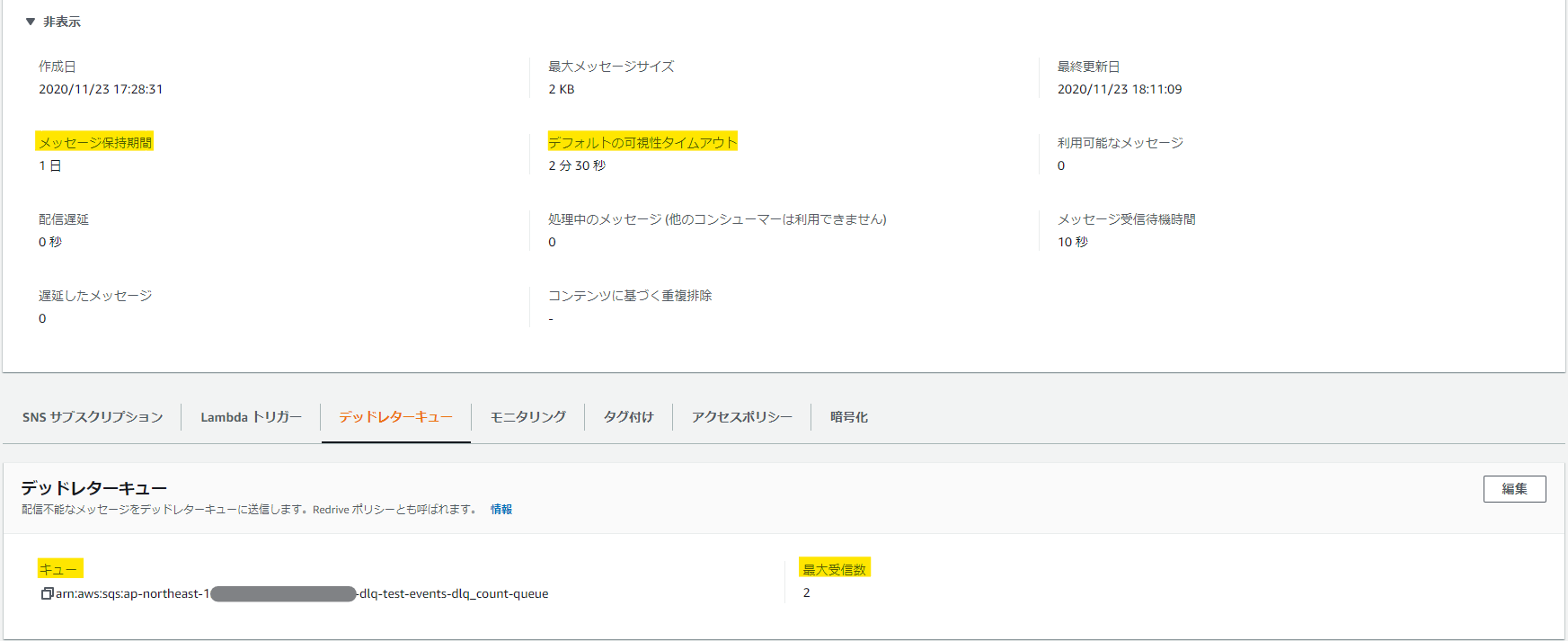
ここで、気を付けなければいけないのは以下の制限事項だ。
- 可視性タイムアウトの設定値は>Lambdaのタイムアウト値 でないといけない
- メッセージの保持期間>デフォルトの可視性タイムアウト×最大受信数 でないといけない(保持期間を過ぎるとDLQに入らず消滅する)
詳細な動作については以下の記事が分かりやすかった。
【Qiita】SQS → Lambdaのリトライ処理について整理してみた
これで、どちらのパターンでもエラー処理のキューに格納することができるようになった。
あとは、エラー処理のキューを監視するなりの設定を入れておくのが良い。