はじめに
フルマネージドな時系列データベースのAmazon Timestreamが9/30に一般公開されたので触ってみる。
時系列データベースは存在自体は以前から知っていたものの、使ったことはないので楽しみ。
新しすぎてまだCloudFormationもTerraformも対応していないので、今回はコンソールからポチポチやってみる。ちなみに東京リージョンではまだ使えないので、コンソールを利用可能なリージョンに向けておこう。
データベースを作ってみる
さて、自分で作ってみようとしたらよく分からなかったので、こういう時はチュートリアルを見ながらやるのが定石だろう。
Timestreamの以下の画面で「Create database」のボタンを押す。
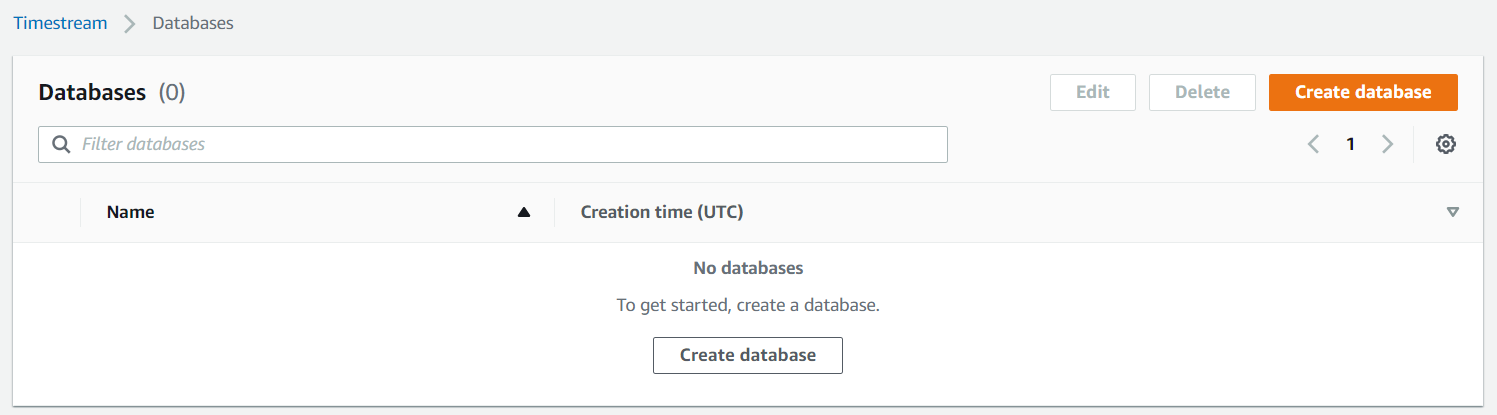
で、開いたデータベース作成の画面で、データベース名を設定する。
※お手軽設定もあるが、今回はStandard databaseを選択する。
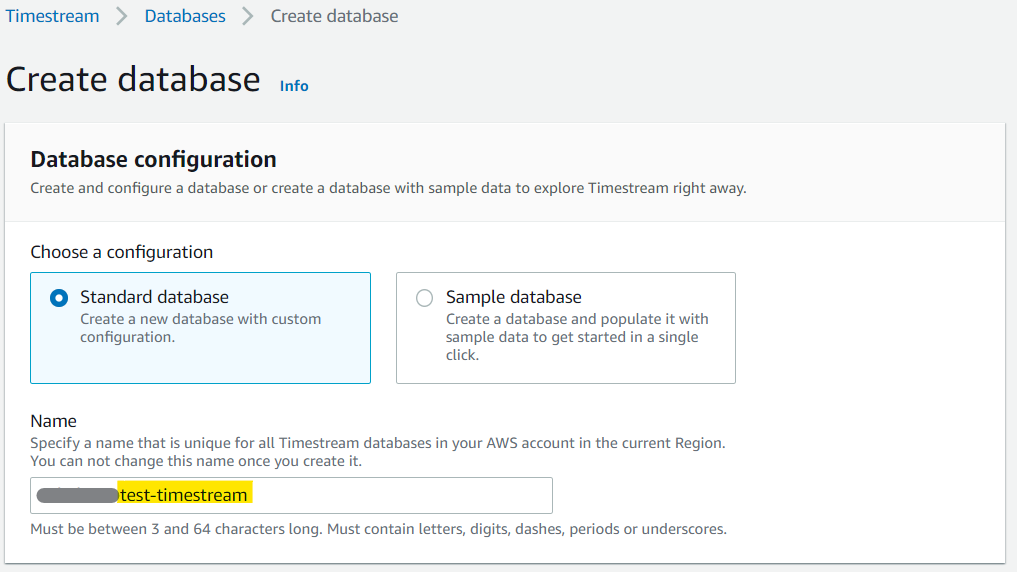
KMSの設定は、空白にしておくと勝手にキーを作成してくれた。
タグを好きに設定して「Create database」ボタンを押す。
作成完了!

テーブルを作ってみる
さて、↑で作ったテーブル名のリンクを押してみよう。
データベースの詳細画面に「Create table」のボタンがあるので押す。
で、開いたテーブル作成の画面で、テーブル名を設定する。
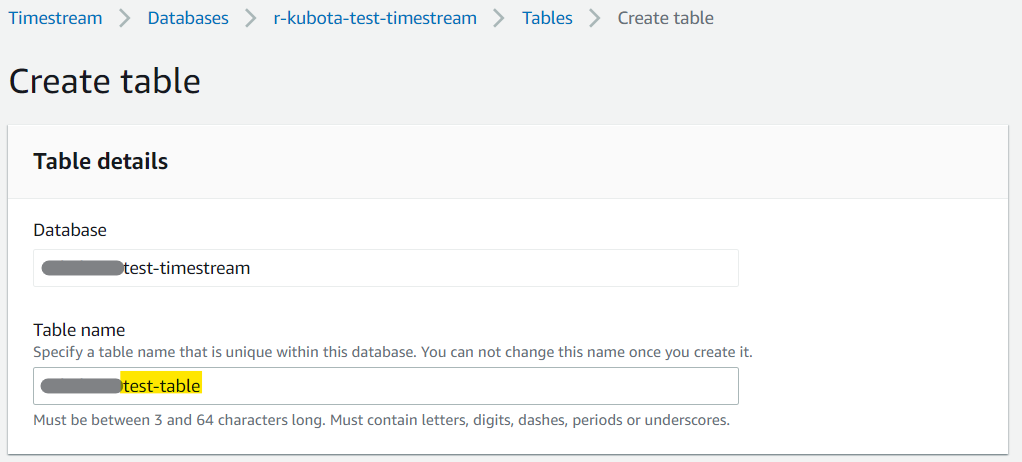
データ保存の設定は、今回はお試しなのでテキトーに。
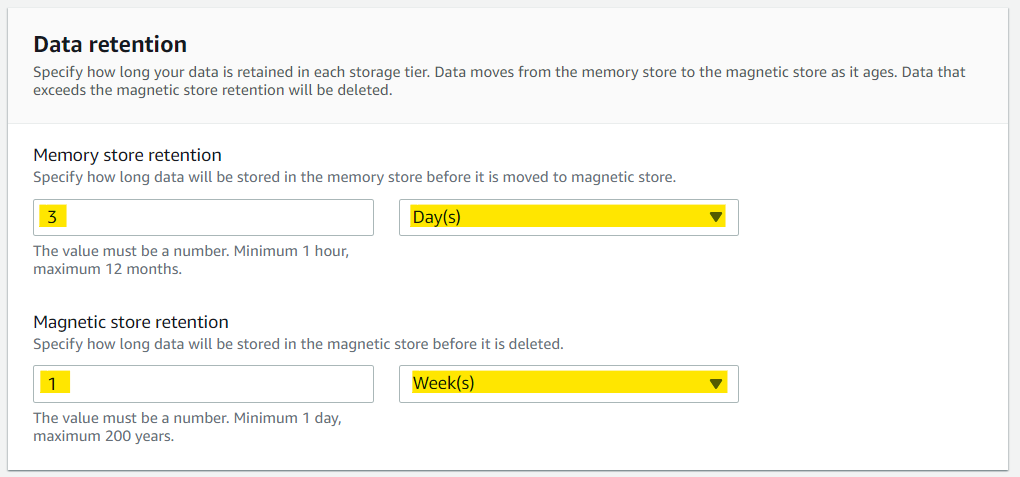
タグをお好みで設定して「Create table」のボタンを押す。
テーブルの作成も完了!
データを登録する
チュートリアルと同じように作るのは面白みがないので、Locustの出力するデータを登録してみることにしよう。
登録対象のデータは以下のようなイメージだ。
Timestamp,User Count,Type,Name,Requests/s,Failures/s,50%,66%,75%,80%,90%,95%,98%,99%,99.9%,99.99%,100%,Total Request Count,Total Failure Count,Total Median Response Time,Total Average Response Time,Total Min Response Time,Total Max Response Time,Total Average Content Size
1603535373,20,GET,/xxxxx/,1.000000,0.000000,5,6,6,6,8,9,9,9,9,9,9,16,0,4.11685699998543,5.413748562499876,4.11685699998543,9.385663000045952,14265.0
これを、以下のPythonでコマンドを作ってロードする。
ディメンションというのがよく分からないかもしれないが、要するに分類するための属性情報だと思えば良い。
今回は、HTTPのリソースとメソッドを属性として定義した。
import sys
import csv
import time
import boto3
import psutil
from botocore.config import Config
FILENAME = sys.argv[1]
DATABASE_NAME = "xxxxx-test-timestream"
TABLE_NAME = "xxxxx-test-table"
def write_records(records):
try:
result = write_client.write_records(DatabaseName=DATABASE_NAME,
TableName=TABLE_NAME,
Records=records,
CommonAttributes={})
status = result['ResponseMetadata']['HTTPStatusCode']
print("Processed %d records.WriteRecords Status: %s" %
(len(records), status))
except Exception as err:
print("Error:", err)
if __name__ == '__main__':
session = boto3.Session()
write_client = session.client('timestream-write', config=Config(
read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10}))
query_client = session.client('timestream-query')
with open(FILENAME) as f:
reader = csv.reader(f, quoting=csv.QUOTE_NONE)
for csv_record in reader:
if csv_record[0] == 'Timestamp' or csv_record[3] == 'Aggregated':
continue
ts_records = []
ts_columns = [
{ 'MeasureName': 'Requests/s', 'MeasureValue': csv_record[4] },
{ 'MeasureName': '95Percentile Response Time', 'MeasureValue': csv_record[10] },
{ 'MeasureName': 'Total Median Response Time', 'MeasureValue': csv_record[18] },
{ 'MeasureName': 'Total Average Response Time', 'MeasureValue': csv_record[19] },
]
for ts_column in ts_columns:
ts_records.append ({
'Time': str(int(csv_record[0]) * 1000),
'Dimensions': [ {'Name': 'resource', 'Value': csv_record[3]}, {'Name': 'method', 'Value': csv_record[2]} ],
'MeasureName': ts_column['MeasureName'],
'MeasureValue': ts_column['MeasureValue'],
'MeasureValueType': 'DOUBLE'
})
write_records(ts_records)
だが、一般公開されたばかりの機能なので、boto3のバージョンが古い人がいるだろう。
$ pip list -o
で、boto3がLatestになっているか確認しよう。
Package Version Latest Type
--------------------- -------- ---------- -----
boto3 1.13.26 1.16.4 wheel
pipでのアップデートは -U で行う。
$ pip install -U boto3
また、aws configure でデフォルトリージョンを、↑でデータベースを作ったリージョンに向けておこう。
psutilが入っていない場合は以下でインストールする。
$ yum install python3-devel
$ pip3 install psutil
いずれ修正されると思うが、2020/10/25時点では↑の公式のブログではコマンド名が間違っているので、ブログを信じてpip3するとインストールできなくて悲しい気持ちになる。
さて、無事データロードできただろうか。
クエリを発行する
左のメニューから「Query Editor」を選択すると以下のような画面が表示されるので、テキトーに属性を絞りながらSQLを実行してみよう。/xxxxx/ の GET リクエストの平均レスポンス時間を知りたい!
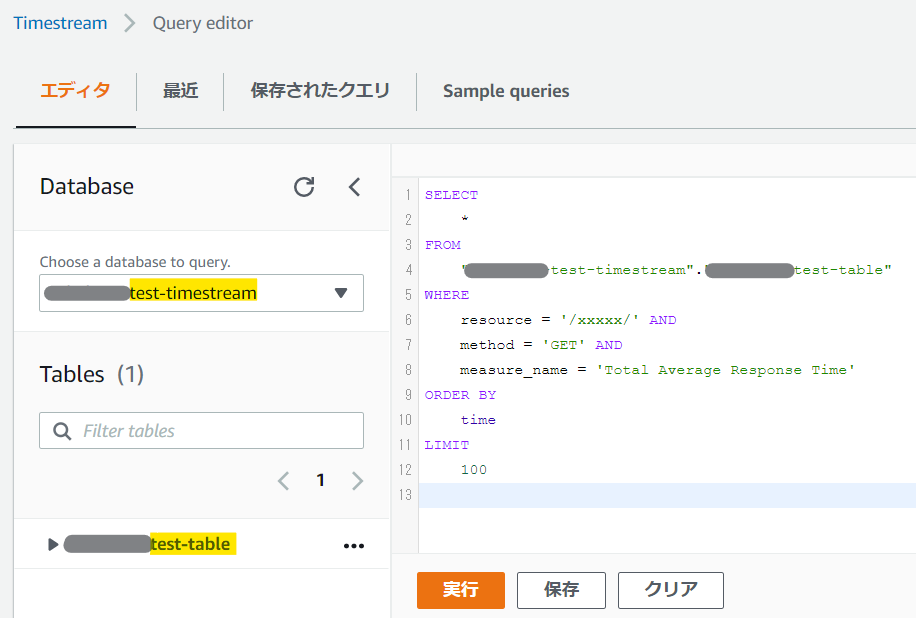
実行したら、バッチリ欲しい情報だけが抽出された!
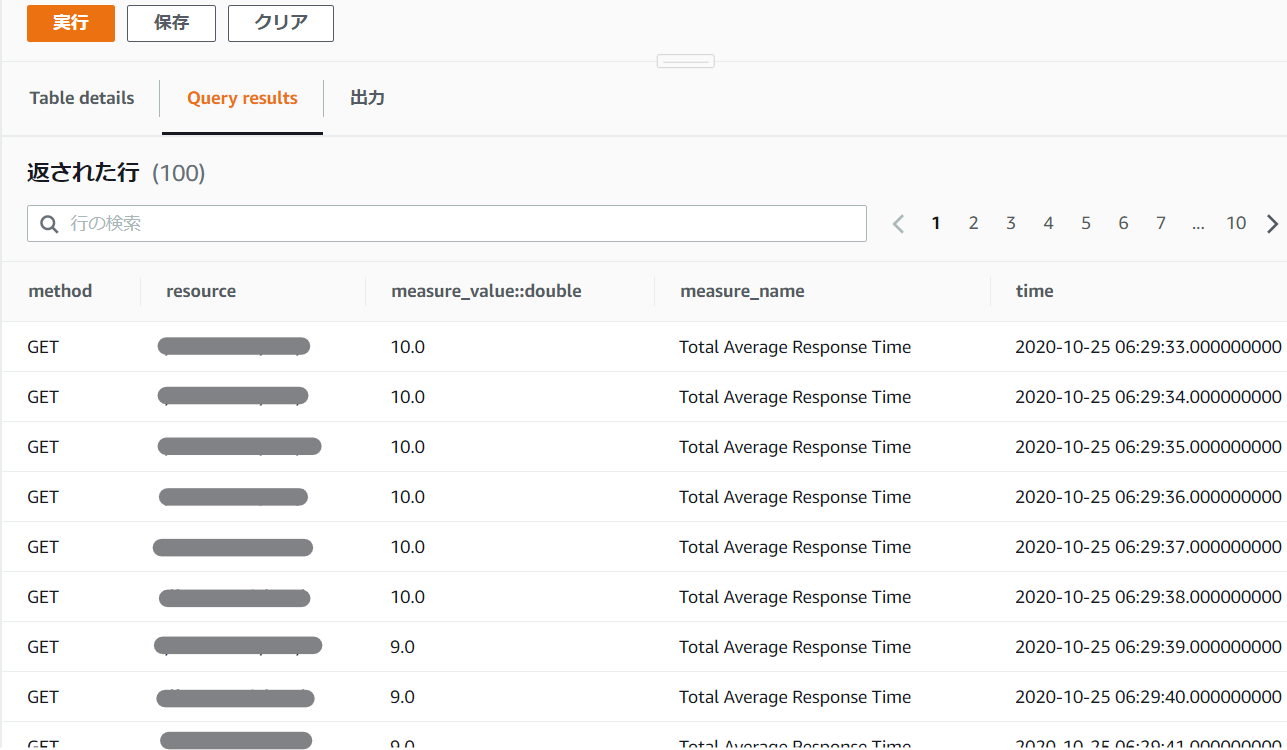
これを生データで取得するには、またCLIなりboto3なりで取得する。
ページネーターが必要だったりで結構面倒。
そもそもちょっとした分量なら、pandasを使うのが楽なのだけど、実際の利用シーンでは、何千台もあるサーバ等から定感覚で収集した情報を素早く取り出すので、ローカルでpandasで整形できるような情報量ではないはずだ。
Grafanaと組み合わせてリアルタイムにモニタリングしたりできるという点が真骨頂なんだろうな……。