はじめに
HDInsightを使っててイラッとした話です。
やりたいこと
バッチ処理を作成していました。1日1回バッチを回して結果をグラフ化、レポートを作成する処理を作ってました。俗に言うETLとかいうやつですね。
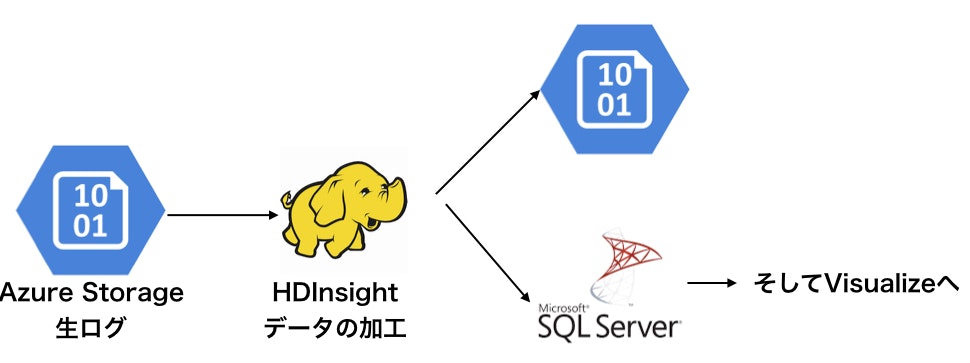
データがストレージに1日分溜まったらHDInsightでデータを処理、結果をまたストレージやSQLSERVERに転送、あとは分析官が解析したりレポートやグラフを作成していました。
HDInsight(後HDIと表記)とは簡単にSparkクラスタを作成できるAzureのサービスです。AmazonのEMRとかと同じです。これを使えばデータが少なくなったときはクラスタの台数を削減し、データが大きくなったらクラスタを大きくすればいいわけですね。
バッチ処理は1日1回しか回さないので、料金を節約するために必要なときHDIを作成、処理が終わったら削除していました。
バッチ処理はきれいに完成し、末永く幸せに暮す予定でした。
HDIのここが嫌
しかし、2年ほど運用していくにつれ、HDIに不満がでてきました。
不満1: HDIの作成に時間がかかる
HDIの作成には15分から20分かかります。
たまに分析官が「マスターデータがまちがっていたから今日のバッチ処理をもう一度回してくれないかね。」などと言ってきたときは、もう一度バッチを回すことがあります。また、テストのときには手動でHDIの削除、作成などを頻繁に繰り返すときがあります。このたびにいちいち20分ほど待たされることにイライラしました。AzureVMではStopモードがあり、VMを停止、起動が素早く行うことができ、しかもStop中は課金されません。しかしHDIにはそのような機能はなく、料金を節約しようとすると、HDIを削除するしかありませんでした。しかしこれは待てばよいだけなので、特に問題にはなりませんでした。
不満2: HDIの作成にときどき失敗する
分析官が、「おやおや、今日のバッチ処理ができてないよ。これでは解析業務ができないじゃないか。」と言ってきました。慌てて本日の処理を見ると、HDIの作成に失敗していました。この現象は月に数回は起きました。HDIの作成に失敗したときは、HDIを一度削除して、何分か経ったらもう一度HDIを作成するよう、リトライ機能を強化しました。このリトライ機能の強化はうまくいきました。一時はどうなるかと思いましたが、また平穏な日々を取り戻しました。
不満3: 中身が勝手にアップデートされる
エラーその1
ある日突然バッチ処理が意味不明なログを大量に吐いてログサーバーを圧迫し始めました。バッチ自体は正常に終わっていましたのでなんとかなりました。慌ててマイクロソフト(後MSと表記)のサポートセンターに問い合わせました。当日は解決しなかったので、ログの削除ローテーションの期間を短くしてログがサーバーを圧迫しないよう調整しました。MSは何日かあとに、HDIのイメージが更新されたせいだと言いました。
自分は「おいおい、こっちは毎回同じ設定ファイルでHDIを作成しているんだよ。毎回同じバージョンのHDIを指定したら同じものができあがってもらわないと困るじゃないか。アップデートするなら新しいバージョンを作って別物としてくれよ。せめてサイレントアップデートはやめて通知しれくれるとかできないのか?」と言いましたが、
MS「すみません今後はデバッグをきちんとやりますが、どうしても全部の機能をカバーしきれません。」とのことでした。
いまだにサイレントアップデートはされているようです。
MSはHDIのイメージを修正してくれ、謎のログは出力されなくなりました。
エラーその2
ある日バッチ処理がエラーを吐くこともなく、宙ぶらりんの状態でいつまでも終わらない現象が起こりました。gitのソースコード履歴には誰もコードを変更した経歴はありません。慌ててMSに緊急度Aで問い合わせました。
「おい、HDIのジョブが終わらないのだが。こちらではHDIを作成する設定ファイルも実行するソースコードも全く変えていない。HDIが勝手にアップデートされたのではないかね?それならもとにもどしてくれ。」
MS「こちらでHDIのイメージがアップデートされた履歴はありません。Sparkのオープンソースのバグと考えられますので、こちらではわかりかねます。」
「そんなわけないだろ。昨日まで全く同じ設定で動いていたんだ!」
MS「こちらでHDIのイメージが(以下同文)」
とても疲れました。
中身が勝手にアップデートされる(と疑われる)ことによるエラーは頻発するわけではありませんが、年に数回あります。
解決策
その1 VMを使う
AzureVMはこの2年でとても大きなメモリーやCPU数を持っているものが登場しており、HDIを使わずともこれで十分なのではと思いました。VMにはStopモードがあり、Stopさせていれば課金されません。しかもStopからstartにするのは30秒から1分ほどで終わります!stopからstartの移行に失敗することもほとんどありません。VMにSparkをインストールしてしまえば勝手に中身がアップデートされてしまう不安からも解消され、上記の3つの不満から解消されます。
その2 Spark Standaloneモードを使う
それでもログ数が増えてVMの上限以上のパワーが必要になったらどうすればよいのでしょうか?
SparkにはStandaloneモードというのがあり、簡単に複数台のサーバーを用いてクラスタが組めるようになっていますので、VMを複数台立ててStandaloneモードを使いましょう。HDIにはYARNとかJupyterNotebookとかhdfsストレージとか様々な便利機能がありますが、日次バッチを回すだけならそんな機能いらないです。
参考:
https://dev.classmethod.jp/business/bigdata/construct-spark-cluster/
まとめ
- HDIを毎日削除、作成を繰り返す運用はミッションクリティカルな業務にはおすすめできない。一回作ったら消すな。消さなければイメージが勝手にアップデートされることはない。
- 最近はVMのサイズはでかいものが用意されている。それで済むならそれが便利。
- それでもマシンパワーが足りなければSparkStandaloneモードで自力でクラスタを組もう。
追記
AzureならdatabricksもSparkが使えます。databricksはバージョン管理がしっかりしてます。
databricksでもクラスタの作成に失敗するときはあるので、リトライの作り込みはHDIと同様に必須です。
クラスタの起動はdatabricksのほうが速いように感じます。