はじめに
普段はKotlinをメイン言語として扱っている筆者が、別のパラダイムの言語を勉強したいというモチベから、動的型付けかつ関数型プログラミング言語のElixirという言語を触ってみました。そこで学んだことをつらつらと書いていこうと思います。
その過程でパズドラ風味のコンソールアプリも作りました。分量的にこちらのコードの紹介はしないので、気になる方だけリポジトリをみてみてください。
有識者の方は、もしよければPR等でレビューをいただけるとめっちゃ嬉しいです💪
お手本のコードではないので、初心者の方は他の信頼できるソースコードを読んでみてください。
関数型プログラミングという言葉は知っているけれども、触ったことないし内容はよくわからないみたいな方に読んでほしいなと思います。
関数型プログラミングとは
まずはwikipediaの概要から読んでいきます。
関数型プログラミングは、関数を主軸にしたプログラミングを行うスタイルである。ここでの関数は、数学的なものを指し、引数の値が定まれば結果も定まるという参照透過性を持つものである。(引用 関数型プログラミング- wikipedia)
これは、参照透過性のある関数を使ってプログラミングをしていくよ! というように言い換えられると思います。すなわちこの参照透過性なるものの意味合いがわかれば関数型プログラミングの概要の部分は掴むことができそうです。
参照透過性とは
またもやwikipediaによる説明を引用します。
参照透過性とは、数学的な関数と同じように同じ値を返す式を与えたら必ず同じ値を返すような性質である。
この文章は少しわかりづらいですが、噛み砕いてみると同じ値を入れたときは必ず同じ値が返ってくるという性質 を示しています。
例えば例として↓のような関数を考えると、3に対してmultipliedBy2を実行するといついかなる時でも答えは6となります。
fun multipliedBy2(value: Int): Int {
return value * 2
}
そのためこの関数は参照透過性を満たしているといえます。図にして考えてみると、
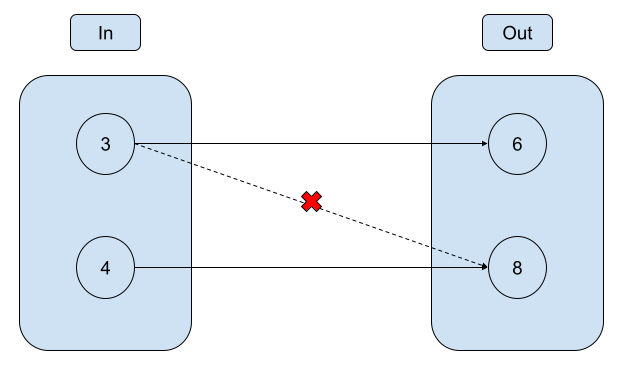
↑のようになります。このとき全ての
Inputから必ず1本だけ矢印が生えている状態というのが参照透過性がある状態といえそうです。
逆に↓のようなコードを考えてみます。
var number: Int = 0
fun sampleA(value: Int): Int {
number++
return value * number
}
fun sampleB(value: Int): Int {
return value * Math.random()
}
このときsampleAとsampleBはともに、呼び出すたびにその戻り値が異なる可能性があります。そのためこれらは参照透過性があるとはいえないようです。
純粋関数とは
さてここまでで参照透過性とは何かという部分はざっくり理解できたかと思います。ここで参照透過性とは別に純粋関数という重要なワードがあるのでこちらも紹介します。
純粋関数の定義とは、以下の2つを満たす関数です。
- 参照透過性がある
- 外部に対する副作用がない
1つ目については前のセクションで説明した通りなのでスキップするとして2について考えてみます。
以下のsampleC関数を考えてみます。
var property: Int = 0
fun sampleC(value: Int): Int {
property++
return value * value
}
fun getProperty(): Int {
return property
}
sampleCはそれ単体で見たときに、全てのvalueに対してただ1つだけ出力が定まるので参照透過性はありそうです。ですが、propertyという外部の変数の値を変更してしまっています。なのでsampleCは参照透過性を持つが純粋関数ではないと言えそうです。
ちなみにこのように外部の値を変更することの何がまずいかというと、propertyのゲッターであるgetPropertyの戻り値がsampleCを呼ぶ前と後で異なってしまうということです。これは外部に対して副作用を起こしてしまっているということであり、バグの温床になってしまいます。
逆にいうと純粋関数のルールを意識してプログラムを作成すると、このような不安定なバグの起きやすい状態は防ぐことができそうです。
KotlinとElixirの比較
ここで抽象的な話ばかりでつまらない文章になってきてしまったので、もう少し具体的な例を出しながら関数型プログラミングの主要概念について見ていこうと思います。
値の不変性
関数型プログラミングでは、値を再代入など変更することができません。まずはこちらのコードをご覧ください。
class Meeting {
private var speaker: String? = null
fun setSpeaker(speaker: String) {
this.speaker = speaker
}
}
defmodule Meeting do
defstruct speaker: nil
@spec set_speaker(t(), String.t()) :: t()
def set_speaker(meeting, speaker) do
## Meeting構造体の作成において既存のmeetingの値を使用しつつ、speakerだけを更新する。
## Kotlinのdata classでいうところのcopyのような感じ。
%Meeting{meeting | speaker: speaker}
end
end
オブジェクト指向的に書いたKotlinのコードと、関数型言語のElixirのコードではいろんな違いがあります。
まずKotlinのコードでは、setSpeakerメソッドを使って、インスタンス変数speakerの値を直接変更しています。一方、Elixirでは、元の構造体のデータを変更せずに新しいMeeting構造体を作成して返しています。
これが値の不変性です。不変性を保つことで、
- データの変更による外部への副作用などが減る
- マルチスレッドでコードを書いたときに、デッドロックなどが起こりづらいスレッドセーフなコードを書くことができる
というようなメリットがあります。このため関数型言語では、値の再代入などを禁止してこの性質を担保しています。
ちなみにですが、Kotlinはオブジェクト指向プログラミングと関数型プログラミングの両方の性質を併せ持っています♡
(某バンジーガムみたいな感じですね。)
そのためKotlinもこの値の不変性を守りながらコードを記述することができるので、そのパターンを記載しておきます。
data class Meeting(val speaker: String? = null)
fun setSpeaker(meeting: Meeting, speaker: String): Meeting {
return meeting.copy(speaker = newSpeaker)
}
繰り返し処理
fun sum(numbers: List<Int>): Int {
var total = 0
for (number in numbers) {
total += number
}
return total
}
defmodule ListSum do
def sum(numbers), do: sum_recursive(numbers, 0)
defp sum_recursive([], acc), do: acc
defp sum_recursive([head | tail], acc) do
sum_recursive(tail, head + acc)
end
end
この手続き処理的Kotlinに対して比較すると、Elixir側ではforではなく再帰を利用しているという大きな違いがあります。
Elixirではfor文がサポートされておらず、基本的に繰り返し処理は再帰を用いて書くことになります。
まずfor文はサンプルコードのtotalのように、forのスコープの外側の状態を変更しながら処理されることが多いです。これは関数型の値の不変性の考え方と相性が悪いです。
また単純なfor文は可読性が低くなりやすいです。基本的にfor文の最初の行はindexの操作の情報だけしかないので、そこだけみても、このforのスコープではどのような処理が意図されているのかということが読み手に少し伝わりづらいです。
このような問題点を、関数型言語では別関数への処理の切り出しと再帰の利用で解決しています。
ちなみにKotlinは優秀なのでこのような再帰的な書き方をすることもできます。
fun sum(numbers: List<Int>): Int {
return sumRecursive(numbers, 0)
}
private fun sumRecursive(numbers: List<Int>, acc: Int): Int {
return if (numbers.isEmpty()) {
acc
} else {
sumRecursive(numbers.drop(1), acc + numbers.first())
}
}
高階関数
fun doubledList(target: List<Int>): List<Int> {
val result = mutableListOf<Int>()
for (number in target) {
result.add(number * 2)
}
return result
}
defmodule ListDoubler do
def doubled_list(target) do
Enum.map(target, fn number -> number * 2 end)
end
end
高階関数とは、引数や戻り値で関数を受渡する関数のことです。Elixirのサンプルコードの中で、Enum.mapの第二引数に無名関数を渡している箇所があります。これがまさに高階関数の例です。このように書くことでいくつかのメリットがあります。
その中でも1番大きいのはロジックの再利用性が高まることです。
サンプルコードについて、現在の仕様はそれぞれのリストの要素を二倍にして返すというものですが新たな仕様変更で、それぞれの要素を二分の一にして返すパターンが追加されたとします。そのときそれぞれのコードでは以下のように対応することになると思います。
fun doubledList(target: List<Int>): List<Int> {
val result = mutableListOf<Int>()
for (number in target) {
result.add(number * 2)
}
return result
}
fun halvedList(target: List<Int>): List<Int> {
val result = mutableListOf<Int>()
for (number in target) {
result.add(number / 2)
}
return result
}
defmodule ListMapper do
def map(numbers, operation) do
Enum.map(numbers, operation)
end
def double(number), do: number * 2
def halve(number), do: number / 2
end
これらを比較すると、明らかにElixir側の方がコード量が少なく仕様追加ができていると思います。これは、リストのそれぞれの要素にあるロジックを適用する部分と適用するロジックそのものを別関数として切り分け高階関数で組み合わせる形で実装していたためです。このように高階関数を使用するとそれぞれのコードブロックの再利用性が高まりやすいです。
もちろんですがKotlinでも高階関数を使うことができます。話がブレるのでやめてほしいですね。
object ListMapper {
fun map(numbers: List<Int>, operation: (Int) -> Int): List<Int> {
return numbers.map(operation)
}
fun double(number: Int) = number * 2
fun halve(number: Int) = number / 2
}
まとめ
ここまでみてきたように、手続き型やオブジェクト指向型と比較して、関数型プログラミングには様々な特徴とメリットがあることがわかりました。もちろんここでは紹介しきれていない様々な概念があるはずなので、それは引き続き勉強していくこととします。色々なパラダイムを学んでみることで、自分がいつも触っている言語がプログラミング言語全体の中でどういう立ち位置にいるのかが俯瞰的にみれた気がします。
最後に、この記事で言いたかったことは皆さんもうお分かりですね??
Kotlin最強マジ卍
Elixirを使用した成果物