機械学習については長らく興味があったものの、手を出さないまま数年が経ってしまった。ここらで勉強を始めてみようと思ったところで、ちょうど面白そうな画像コンペがあったので、データだけ拝借して練習してみることにした。(コンペ自体は既に終了しているが、データは利用可能で結果の提出も可能。)
タスク自体はとても素直なもので、物体検知と分類の両方を行う。最近ではEfficientDetという、これら両方のタスクが一度にできるモデルがあるそうで、これを使って実装してみることにした。しかしまあこれがまた難しく、思うように進まない。Kaggleのnotebook上で実装していたが、インポートしたパッケージ内の修正を求めるエラーメッセージも出てきたので一度断念。google colabのnotebookを使い、小さい例から始めることにした。
ネットを徘徊していて見つけたのがendaamanさんのブログ。正方形の黒い背景の中に赤い丸が一つあり、それを検知するという例である。基本的には上記の記事内にあるソースコードでテスト可能だが、2023年4月時点、google colabのnotebookで実験した際にはいくつかエラーが発生した。エラーの内容と対処した方法、学習後の精度についてメモしておく。
エラーの内容と対処方法
- view size is not compatible with input tensor's size and stride
学習ループの中では、モデルに画像と正しいバウンディングボックス情報を入力する。具体的には下記の箇所である。
# 訓練
for epoch in range(1, args.epoch+1):
...
for (inputs, targets) in t:
...
losses = bench(inputs, targets)
...
# エラーの内容
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-7-9f3114f08672> in <cell line: 19>()
33 targets['cls'] = targets['cls']
34 optimizer.zero_grad()
---> 35 losses = bench(inputs, targets)
36 loss = losses['loss']
37 loss.backward()
/usr/local/lib/python3.9/dist-packages/effdet/anchors.py in batch_label_anchors(self, gt_boxes, gt_classes, filter_valid)
396 cls_targets[count:count + steps].view([feat_size[0], feat_size[1], -1]))
397 box_targets_out[level_idx].append(
--> 398 box_targets[count:count + steps].view([feat_size[0], feat_size[1], -1]))
399 count += steps
400 if last_sample:
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
effdet内でview関数というものが呼ばれるが実態はreshape処理をしており、こちらを使えというもの。effdetの内のanchors.pyの中に該当箇所があるので、下記のように修正した。(2023年4月時点に'pip install effdet'でインストールしたパッケージに対して実施。)
> 398行目 修正前
#box_targets[count:count + steps].view([feat_size[0], feat_size[1], -1]))
> 修正後
box_targets[count:count + steps].reshape([feat_size[0], feat_size[1], -1]))
- Labels vanish when the bounding box goes out of boundaries
データセットの中で、Augmentationの処理を行っている。この処理の最初の方に画像をランダムに切り取るという処理があるが、ここでもしバウンディングボックスの範囲が切り取られた場合、画像に紐づいていたバウンディングボックスとラベルの情報が削除されることになる。バウンディングボックスについては空のデータを作る処理がなされているが、ラベルについての処理をしていなかったのでエラーが発生。
class CircleDataset(Dataset):
...
def __getitem__(self, idx):
...
if bboxes.shape[0] == 0:
bboxes = torch.zeros([1, 4], dtype=bboxes.dtype)
...
return x, y
...
# エラーの内容
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-10-9f3114f08672> in <cell line: 19>()
28 t = tqdm(loader, leave=False)
29
---> 30 for inputs, targets in t:
31 inputs = inputs
32 targets['bbox'] = targets['bbox']
/usr/local/lib/python3.9/dist-packages/torch/utils/data/_utils/collate.py in collate_tensor_fn(batch, collate_fn_map)
161 storage = elem.storage()._new_shared(numel, device=elem.device)
162 out = elem.new(storage).resize_(len(batch), *list(elem.size()))
--> 163 return torch.stack(batch, 0, out=out)
164
165
RuntimeError: stack expects each tensor to be equal size, but got [0] at entry 0 and [1] at entry 1
バウンディングボックス情報が消えた際、空のラベル情報も定義してあげることでエラーを回避した。
# 修正後
if bboxes.shape[0] == 0:
bboxes = torch.zeros([1, 4], dtype=bboxes.dtype)
labels = torch.FloatTensor(np.array([0])) # 追加箇所
学習後の予測精度
トレーニングセットと同じデータセットからランダムに画像を一つ取り出し、モデルに入力して予測結果を得た。
予測はeffdetに含まれるDetBenchPredictを行う。画像データのサイズは(3, 512, 512)であるが、DetBenchPredictはバッチを入力値として取るため、'unsqueeze'関数を使って次元を一つ追加している。
DetBenchPredictの出力は(N, 6)サイズのテンソルである。Nは予測されたバウンディングボックスの数で、残りの6要素の意味は順に下記の通りである。
- バウンディングボックス左上のx座標
- バウンディングボックス左上のy座標
- バウンディングボックス右下のx座標
- バウンディングボックス右下のy座標
- 分類されたクラスが正解である確率
- 分類されたクラス
使用したコードは下記の通り。描画は確率が50%以上のもののみを表示するようにしている。
image, targets = dataset.__getitem__(0)
image = image.unsqueeze(0)
bench = DetBenchPredict(model)
with torch.no_grad():
output = bench(image)
# Draw the predictions with over 50% probability
fig, ax = pp.subplots()
ax.imshow(image[0,:,:])
for i in range(output.shape[1]):
if output[0, i, 4] > 0.5:
x1 = int(output[0, i, 0])
y1 = int(output[0, i, 1])
width = int(output[0, i, 2] - output[0, i, 0])
height = int(output[0, i, 3] - output[0, i, 1])
rect = patches.Rectangle((x1, y1), width, height, edgecolor='r', facecolor='none')
ax.add_patch(rect)
print(output[0,i,:])
pp.show()
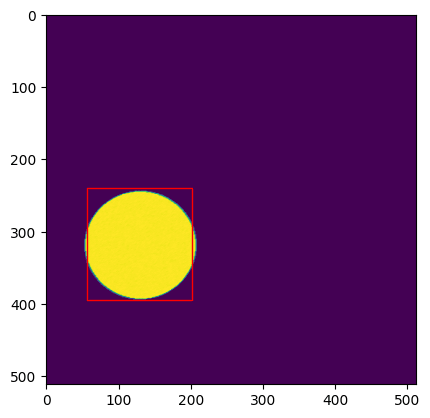
ちなみに、エポック1回分でこのくらいの精度。
(output[0, i, :)
tensor([ 14.0453, 114.7553, 26.5884, 158.7972, 0.6781, 1.0000])
tensor([144.7045, 129.4016, 182.4770, 259.8239, 0.6156, 1.0000])
tensor([ -0.6067, 162.9664, 68.7289, 175.3027, 0.5549, 1.0000])
tensor([ -4.6260, 7.1583, 156.3810, 120.1586, 0.5246, 1.0000])
tensor([ 29.6035, 88.9964, 99.8469, 168.4458, 0.5069, 1.0000])
tensor([182.1268, 257.2897, 182.7585, 465.5251, 0.5004, 1.0000])

エポック10回分でこのくらいになった。
(output[0, i, :])
tensor([ 56.7382, 239.4214, 201.9494, 395.7658, 0.8747, 1.0000])