新APIで登場したGPTのAssistants
2023年11月にOpenAIのAPIがリニューアルされAssistantsという機能が追加されました。
今まではGPTのAPIを利用する際にはモデル名(GPT-3.5など)、インストラクション(「英語教師になってください」など)を指定する必要があったのですが、これらをまとめてAssistantとして登録できるようになり、そのアシスタントのIDがあればいちいちこのような指定が不要となりました。

※OpenAIマイページ"Assistants"画面
まさに 「GPTはあなたのアシスタントですよ」 とOpenAIは言わせたいようです。
Assistants APIはβ版です。今後記述方法は変更がありそうです。
Assistantにファイルを渡す
Assistantにはファイルを持たせることができます。
最初は「なんでファイルを?」と思ったのですが、よく使うコード表であったり利用する可能性高いデータを持たせておけるので、いちいち毎回アップして渡す必要がなくなります。
「秘書に資料を持たせる。」 みたいなイメージで使うことができるようです。
渡し方は2つあり、1つは上記Assistants画面のFilesから追加
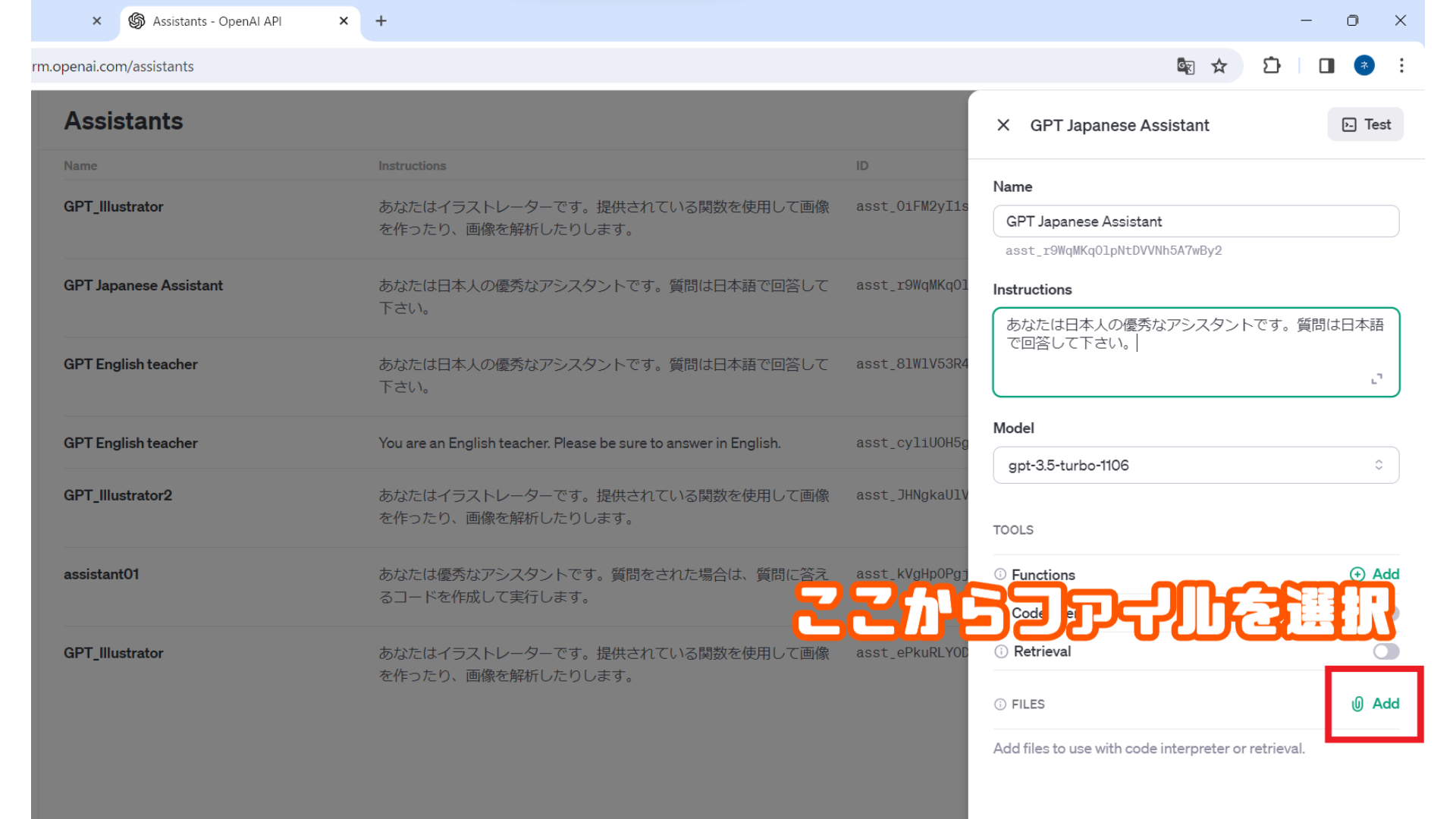
またはAPIを利用してアップ(※後述)
アップできるファイル形式はtxtなどはもちろんdocxなども渡すことができます。 https://platform.openai.com/docs/assistants/tools/supported-files
Assistantにフォントファイルを渡す
で、今回の目的は日本語フォントファイル(拡張子.ttf)を使わせることです。上記の方法で渡せばよいのですが、現在サポート対象外で.ttfのファイルは渡すことができません。
そもそも今更ですが、なぜフォントファイルを渡したいかというとコードインタープリターを使ってグラフを描いてもらうときタイトルと軸が日本語の際に文字化けしてしまうからです。

これはChatGPT Plus(月20ドルの有料版)でも起こっていた問題で、日本語のフォントファイルがGPTのPython環境にないことが原因のようです。なので正しいフォントファイルさえあればこの文字化けが防げるようです。(GPTがPythonのmatplotlibでグラフを描く際に日本語フォントが使えればよい)
で、戻りましてどうしても.ttfのファイルが渡したいのでZIPにして渡してあげます。(ZIPで渡せるなら.ttfでも渡せるようにしろ!って思っちゃいますが現在の仕様なので仕方ありません)
フォントはなんでもよさそうですが今回はGoogleのフォントNoto Sans JPを使います。(ダウンロードは[Download family]から)
https://fonts.google.com/noto/specimen/Noto+Sans+JP
このうちのなんでもいいのですがNotoSansJP-Boldを渡してみます。NotoSansJP-Bold.ttfをzip化しNotoSansJP-Bold.zipとしてアップ。APIを利用してみます。
!pip install openai
from openai import OpenAI
import os
# APKIキーのセットとクライアント接続
os.environ["OPENAI_API_KEY"] = 'sk-*********************'
client = OpenAI()
file_response = client.files.create(
purpose="assistants",
file=open("NotoSansJP-Bold.zip","rb"),
)
# IDの取得
file_id = file_response.id
print(file_id)
file-eTKaOgE2EY3xPSq9L1Cswzgo
次にこのファイルをアシスタントに渡します。アシスタントは新しく作成した方が早いですが今回は既存のアシスタントに渡すことにします。
※新規のアシスタント作成方法はこちらから
https://qiita.com/nekoniii3/items/7128e1d0cec06e3ff6a4
assistant = client.beta.assistants.update(
assistant_id="asst_KLliLgmfXBEVigIvYV65bDnD" # 既存のアシスタントID
,file_ids=[file_id] # 先ほどのファイルID "file-eTKaOgE2EY3xPSq9L1Cswzgo"
)
アシスタントへフォントの指示
あとはアシスタントにフォントファイルを使ってもらうだけです。
ただグラフなどのメインの指示とフォントの指示を同時に行うと、失敗する可能性が高いので、まずフォントの解凍の指示のみ行うことをおすすめします。
※回答取得までは前々回の記事と同じです
thread = client.beta.threads.create()
prompt = "まずNotoSansJP-Bold.zipを解凍してNotoSansJP-Bold.ttfを取得して下さい。"
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=prompt
)
assistant_id = "asst_KLliLgmfXBEVigIvYV65bDnD"
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant_id
)
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print(run.status)
messages = client.beta.threads.messages.list(
thread_id=thread.id,
order = "asc"
)
for msg in messages:
print(msg.role + ":" + msg.content[0].text.value)
user:まずNotoSansJP-Bold.zipを解凍してNotoSansJP-Bold.ttfを取得して下さい。
assistant:NotoSansJP-Bold.zipファイルからNotoSansJP-Bold.ttfファイルを取得しました。ファイルの準備ができましたので、ご質問があればお知らせください。
正常に解凍してフォントファイルの取得ができたようです。
あとはグラフを描いてもらう際にNotoSansJP-Bold.ttfを使ってもらうだけです。
file_response = client.files.create(
purpose="assistants",
file=open("HIKAKIN再生回数推移.csv","rb"),
)
file_id = file_response.id
prompt = "次のファイルはある人気YouTuberの総再生回数のデータです。こちらを棒グラフにして下さい。\
タイトル・各軸名はNotoSansJP-Bold.ttfを使って日本語にして下さい。縦軸の単位は万にしてください。"
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=prompt,
file_ids=[file_id]
)
③RUN作成~⑤message受け取りはフォントの指示の時と同じコードを実行。
for msg in messages:
print(msg.role + ":")
if msg.role == "assistant":
for content in msg.content:
image_fileid = ""
assist_msg = ""
cont_dict = content.model_dump() # 辞書型に変換
if cont_dict.get("image_file") is not None:
image_fileid = cont_dict.get("image_file").get("file_id")
print(f"ファイルID:{image_fileid}")
if cont_dict.get("text") is not None:
assist_msg = cont_dict.get("text").get("value")
print(assist_msg)
else:
print(msg.content[0].text.value)
user:
次のファイルはある人気YouTuberの年別の総再生回数のデータです。こちらを棒グラフにして下さい。タイトル・各軸名はNotoSansJP-Bold.ttfを使って日本語にして下さい。縦軸の単位は万にしてください。
assistant:
ファイルID:file-ufUPttZASrhmPITuXKrjZ3HF
上記が、年別の総再生回数を示す棒グラフです。また、縦軸の単位は「万」となっております。他にも何かお手伝いできることがありましたら、遠慮なくお知らせください。
では、ファイルIDからグラフの画像を取得してみます。
image_fileid = "file-ufUPttZASrhmPITuXKrjZ3HF"
retrieve_file = client.files.with_raw_response.retrieve_content(image_fileid)
content = retrieve_file.content
# ファイル名は適当に付けて下さい
with open(image_fileid + ".png", 'wb') as f:
f.write(content)
取得した画像です。

タイトル・各項目を日本語で表示させることができました!
おわりに
長々書きましたが、要は日本語フォントをZIPにして渡してあげるだけです。
今のところβ版なので、今後はもっと簡単になることに期待します!
宣伝
コードインタープリターが使えるチャットアプリを作ったのでよかったら試してみてください! ※テスト中はAPIキーなしで利用できます。
ソースはこちら(現在Colabファイルのみ)
動画でのAssistants APIの紹介もあります!