はじめに
本記事は論文"Maximum Expressive Number of Threshold Neural Networks"の解説です。
内容は、活性化関数がthreshold関数のニューラルネットワークのデータ表現能力に関する論文で、多層パーセプトロンにおける最大表現数(Maximum Expressive Number)の一般解を求めたものになります。
発表スライドはYouTubeで公開されています。
活性化関数がReLUの場合はこちらの記事にまとめてあります。
データ表現能力とは
ニューラルネットワークにおけるデータ表現能力とは、学習を行う前に決定しなければならないパラメータ1、すなわちハイパーパラメータを固定したニューラルネットワークに対して、どの程度複雑な訓練データを表現できるのかという指標です。
データ表現能力が高いほどより複雑な訓練データを用いて学習を行うことができますが、訓練データの複雑さに対してデータ表現能力が高すぎると過学習を引き起こす可能性があります。すなわち、データ表現能力は学習データの複雑さに合ったハイパーパラメータを決定するための1つの指標となりうるということです。
本記事ではこれらの指標のうち、データ数を基準に定義された"表現数"に着目します。
表現数
表現数を簡単に説明すると以下のような定義になります。
Nを自然数とする。
ニューロン数を固定したニューラルネットワークが表現数Nを持つとは、以下を満たすことである。任意のN個の訓練データに対して、その全てのデータの入出力とニューラルネットワークの入出力が一致するようなニューラルネットワークの重み値、バイアス値が存在する。
とりうる表現数の最大値を最大表現数と呼ぶ。
まとめると、ある大きさのニューラルネットワークの最大表現数がNのとき、訓練データ数がN個以下ならば、そのニューラルネットワークは誤差0で全ての訓練データを表現できてしまう、すなわち学習における収束先が存在することを表しています。
次に今回対象とする活性化関数であるthreshold関数について見てみます。
threshold関数
以下で定義される関数です。
\operatorname{threshold}(x) := \begin{cases}1 & (0 \leq x)\\ -1 & (o.w.)\end{cases}
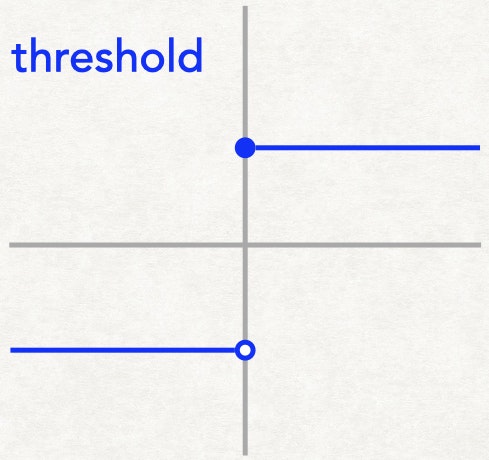
実際の学習では活性化関数として使われることはほとんどありませんが、シンプルな定義であるため数学的な命題を示すのには有用な関数です。
表現数を求めるのには、「任意のデータに対して」の一文があり実験的なアプローチが難しいため、一般的には数学的なアプローチを行います。数学的アプローチには証明を伴うため、実際にはそのオーダーや値が存在する範囲を求めるのが手一杯である場合が多いですが、threshold関数の場合、その定義のシンプルさゆえに最大表現数の具体値の一般解を求めることができます。
thresholdニューラルネットワークの最大表現数
多層パーセプトロンのニューロン数を入力側から順に$n,,a_1,,a_2,,\ldots,,a_{l-1},,a_l,,m$とする。(つまり入力次元がn、出力次元がm、中間層数lのニューラルネットワークです。)
このときthresholdニューラルネットワークの最大表現数は以下のようになります。
\begin{cases}a_1+1 & (l = 1)\\
\min\{a_1+1,\,a_2+1\} & (l = 2)\\
\min\{a_1+1,\,2^{a_2},\,\ldots,\,2^{a_{l-1}},\,a_l+1\} & (l > 2)\end{cases}
この結果から、活性化関数がthreshold関数のときの最大表現数は層が増やしても大きくなることはなく、むしろ減少するのみであるため、もっとも効率的なニューラルネットワークは中間層が1層のときであるということが分かります。
まとめると、一般に層数を増やすほどデータ表現能力が増えるとは限らないということです。
なぜこのような結果になるのか
最大表現数がこのような結果になる理由として考えられるのは、各層で表現できるデータの空間が限られているということです。つまり各データは全ての層で表現できる空間を通過しなくてはいけないため、それら全ての条件を満たすことを最小値を取ることで表されていると考えられます。
今回のケースでは、中間層1層目の表現できるデータ数は$a_1+1$個であり、2層目からl-1層目の各i層目では$2^{a_i}$個、l層目は$a_l+1$個であって、訓練データがこれら全ての空間を通過するためにはデータ数が各層の容量以下、すなわちその最小値以下でなくてはならないということです。
まとめ
活性化関数がthreshold関数のときの最大表現数についての論文内容をまとめました。
この結果から、中間層数が多いほど常に表現能力が大きくなるとは限らず、むしろ減少する場合もあることが分かりました。
-
中間ニューロン数、活性化関数など。 ↩