経緯
サーバの監視で使っているPrometheus+GrafanaではGCEやEC2などのインスタンスに対しては、サービスディスカバリで自動的に認識しているので、
誰かが勝手に作ったりすると分かるようになっています。
ですが、RDSやCloudSQLや、他のPaaSサービスに関しては検知が出来ないので、代わりに課金情報を可視化して分かるようにしたい。
GCPの機能で課金情報を日次で自動エクスポートする機能があるので、それを利用して、CSVからMySQLに入れてそれをGrafanaデータソースとして表示させようと思います。
BigQueryにもエクスポート出来るので、単純にGCPの課金情報を可視化するだけなら、そっちにした方が良いです。
今回はpythonを全く使った事が無いインフラエンジニアが、勉強の為に面倒な事をしてます。(笑)
事前の確認
CSVの中身
エクスポート機能を使うとCloudStorageに自動的に日付単位でエクスポートされるようになります。
とりあえず中身を確認します。(csvをエクセルで開いてます)
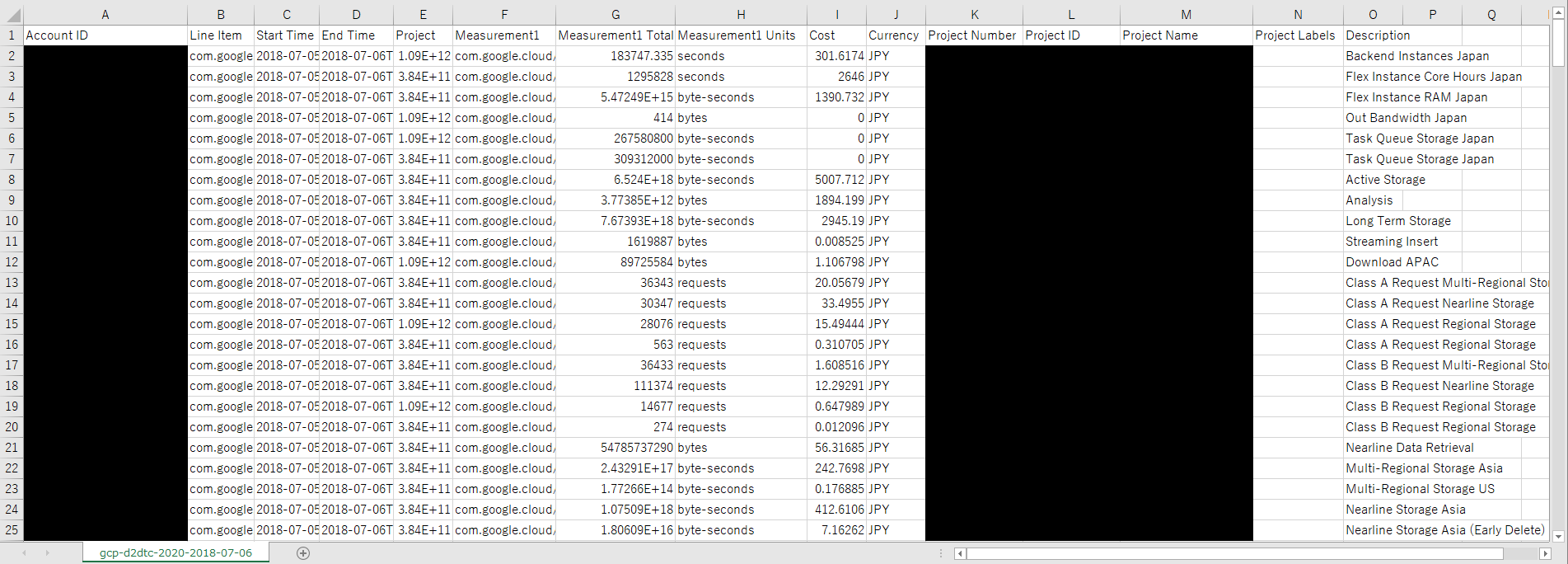
カラム名は以下となっているようです。
(環境によっては増減します)
- Account ID
- Line Item
- Start Time
- End Time
- Project
- Measurement1
- Measurement1 Total Consumption
- Measurement1 Units
- Credit1
- Credit1 Amount
- Credit1 Currency
- Cost
- Currency
- Project Number
- Project ID
- Project Name
- Project Labels
- Description
Grafana側の仕様や方法
参考URL
公式using-mysql-in-grafana
MySQLのデータをGrafanaでグラフィカルに表示してみた
実装 流れ
- CSVダウンロード
- CSVを加工
- MySQLへデータ挿入
- Grafanaでダッシュボード作成
上記の流れで、1はgsutil、2,3はpythonでやります。
実行するのは、Grafanaを実行しているサーバ上(Ubuntu16.04)を想定しています。
CSVダウンロード
gsutilを使うだけなので、コマンド1発ですね。※gsutilの導入や設定はここでは省きます。
一応 csvを格納するディレクトリを作ってそことrsyncするようにしています。
また、中間ファイル用にtmpディレクトリも作成します。
mkdir -p /usr/local/gcp/billing/csv
mkdir /usr/local/gcp/billing/tmp
gsutil -m rsync gs://csvエクスポートパス/ /usr/local/gcp/billing/csv
また、定期的にダウンロードしたいのでcronに登録します。
0 1 * * * /root/google-cloud-sdk/bin/gsutil -m rsync gs://csvエクスポートパス/ /usr/local/gcp/billing/csv
csv加工
pythonソース
まずソースを全部載せてから、各処理の説明をします。
アプリケーション開発未経験のインフラエンジニアが完全に独学と試行錯誤をして書いた物なので、糞ソースなのはご了承ください。
(こういうやり方の方が良いというご指摘があればコメントくれるとうれしいです)
# !/usr/bin/python3
import os
import sys
import glob
import csv
# import sqlite3
import pymysql as db
from sqlalchemy import create_engine
import pycurl
import pandas as pd
import re
import subprocess
from datetime import datetime, date, timedelta
import time
# db setting
user = 'XXXX'
password = 'XXXXXX'
host = 'localhost'
dbname = 'XXXXXX'
port = '3306'
pd.set_option('display.max_columns', None)
pd.set_option("display.max_colwidth", 150)
pd.set_option("display.precision",3)
pd.set_option("display.notebook_repr_html", True)
pd.set_option("display.float_format",'{:f}'.format)
os.path.dirname(os.path.abspath(__file__))
os.chdir(os.path.dirname(os.path.abspath(__file__)))
def getcsvlist():
csvs = glob.glob("./csv/*.csv")
return csvs
def csvjoin(csvs,o):
df_list = []
for csv in csvs:
df = pd.read_csv(csv)
df_list.append(df)
df2 = pd.concat(df_list,sort=True)
df2.drop(columns=['Account ID','Line Item','Project Number','Project Labels','Currency','Measurement1 Total Consumption','Measurement1 Units','End Time'])
df2 = df2.ix[:,['Project Name','Measurement1','Description','Start Time','Credit1','Credit1 Amount','Cost']]
df2 = df2.rename(columns={'Project Name':'ProjectName', 'Start Time':'Date', 'Credit1':'Credit', 'Credit1 Amount':'CreditAmount'})
#df2 = df2.reset_index(drop=True)
#df2.set_index('Start Time', inplace=True)
#df2['Start Time'] = df2.to_datetime(df2['Start Time'])
#print(type(df2.index[0]))
df2.to_csv(o,index=False,mode='w')
def alltodb(csv):
df = pd.read_csv(csv)
engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s' % (user, password, host, port, dbname))
with engine.begin() as con:
df.to_sql('billing', con=con, if_exists="replace",index=False)
def diffinsert(csv):
engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s' % (user, password, host, port, dbname))
q = 'DELETE FROM billing WHERE Date BETWEEN \''+ fro +'\' AND \''+ to +'\';'
#q = 'SELECT * FROM billing WHERE Date BETWEEN \''+ fro +'\' AND \''+ to +'\';'
res = engine.execute(q)
print(res.rowcount)
#for row in res:
# print(row)
df = pd.read_csv(csv)
with engine.begin() as con:
df.to_sql('billing', con=con, if_exists="append",index=False)
def datenumdays(n):
global to
global fro
today = datetime.today()
fromday = today - timedelta(days=n)
to = datetime.strftime(today, '%Y-%m-%d %H:%M:%S')
fro = datetime.strftime(fromday, '%Y-%m-%d %H:%M:%S')
def diffcsv(i,o,start,end):
df = pd.read_csv(i, index_col=3,parse_dates=['Date'])
#print(i,o,start,end)
#df2 = df['2018-08-31 19:03:49':'2018-09-03 19:03:49']
df2 = df[start:end]
df3 = df2.reset_index()
df3.set_index('Time', inplace=True)
df3.to_csv(o,mode='w')
def convertime(i,o):
df = pd.read_csv(i, parse_dates=['Date'])
df['Time'] = df['Date'].apply(posix_time)
df['Date'] = pd.to_datetime(df['Date'])
df = df.sort_values(by=['Time'], ascending=True)
df.set_index('Time', inplace=True)
df.to_csv(o,mode='w')
def formatt(i,o):
csvfile = open(i,'r')
csvout = open(o,'w')
# Project Name,Measurement1,Description,Start Time,Credit1,Credit1 Amount,Cost
## Descriptionを簡単に名前寄せ
for line in csvfile:
#line = re.sub(r'([0-9]...-[0-9].-[0-9].)([^,]*)','\\1',line)
line = re.sub(r'(com.google.cloud\/services\/)([^,]*),([^,]*)','\\1\\2,Other',line)
line = re.sub(r'(com.googleapis\/services\/)([^,]*),([^,]*)','\\1\\2,API',line)
if line.find('cloud-storage') != 1:
line = re.sub(r'(com.google.cloud\/services\/cloud-storage)([^,]*),([^,]*)','\\1\\2,Cloud Storage',line)
if line.find('app-engine') != 1:
line = re.sub(r'(com.google.cloud\/services\/app-engine)([^,]*),([^,]*)','\\1\\2,App Engine',line)
if line.find('big-query') != 1:
line = re.sub(r'(com.google.cloud\/services\/big-query)([^,]*),([^,]*)','\\1\\2,BigQuery',line)
if line.find('app-engine') != 1:
line = re.sub(r'(com.google.cloud\/services\/compute-engine)([^,]*),([^,]*)','\\1\\2,Compute Engine',line)
if line.find('cloud-sql') != 1:
line = re.sub(r'(com.google.cloud\/services\/cloud-sql)([^,]*),([^,]*)','\\1\\2,Cloud SQL',line)
csvout.write(line)
csvfile.close()
csvout.close()
## Measurement1 drop
df = pd.read_csv(o)
df = df.drop(columns=['Measurement1'])
df = df.reset_index(drop=True)
df.to_csv(o,index=False,mode='w')
def main()
args = sys.argv
argc = len(args)
print(args)
if (argc != 2):
print('Usage: # python3 %s diff(or)all ' % args[0])
quit()
csvs = getcsvlist()
csvjoin(csvs,'./tmp/csvjoin.csv')
formatt('./tmp/csvjoin.csv','./tmp/format.csv')
convertime('./tmp/format.csv','./tmp/billing.csv')
if args[1] == "diff":
print('diff')
datenumdays(4)
diffcsv('./tmp/billing.csv','./tmp/diff.csv',fro,to)
diffinsert('./tmp/diff.csv')
elif args[1] == "all" :
print('all')
alltodb('./tmp/billing.csv')
else:
print('Usage: # python3 %s diff(or)all ' % args[0])
quit()
main()
csv結合
def getcsvlist():
csvs = glob.glob("./csv/*.csv")
return csvs
def csvjoin(csvs,o):
df_list = []
for csv in csvs:
df = pd.read_csv(csv)
df_list.append(df)
df2 = pd.concat(df_list,sort=True)
df2.drop(columns=['Account ID','Line Item','Project Number','Project Labels','Currency','Measurement1 Total Consumption','Measurement1 Units','End Time'])
df2 = df2.ix[:,['Project Name','Measurement1','Description','Start Time','Credit1','Credit1 Amount','Cost']]
df2 = df2.rename(columns={'Project Name':'ProjectName', 'Start Time':'Date', 'Credit1':'Credit', 'Credit1 Amount':'CreditAmount'})
#df2 = df2.reset_index(drop=True)
#df2.set_index('Start Time', inplace=True)
#df2['Start Time'] = df2.to_datetime(df2['Start Time'])
#print(type(df2.index[0]))
df2.to_csv(o,index=False,mode='w')
- getcsvlist
csvディレクトリのcsvファイルをリストで取得する
- csvjoin
pandasで全csvを読みこんで結合、
Grafanaで表示に必要の無いカラムの削除
何処か(忘れた)でスペースがあるとダメと言われたので、カラム名をスペース無しにリネーム
csvへ出力
名寄せ
def formatt(i,o):
csvfile = open(i,'r')
csvout = open(o,'w')
# Project Name,Measurement1,Description,Start Time,Credit1,Credit1 Amount,Cost
## Descriptionを簡単に名前寄せ
for line in csvfile:
#line = re.sub(r'([0-9]...-[0-9].-[0-9].)([^,]*)','\\1',line)
line = re.sub(r'(com.google.cloud\/services\/)([^,]*),([^,]*)','\\1\\2,Other',line)
line = re.sub(r'(com.googleapis\/services\/)([^,]*),([^,]*)','\\1\\2,API',line)
if line.find('cloud-storage') != 1:
line = re.sub(r'(com.google.cloud\/services\/cloud-storage)([^,]*),([^,]*)','\\1\\2,Cloud Storage',line)
if line.find('app-engine') != 1:
line = re.sub(r'(com.google.cloud\/services\/app-engine)([^,]*),([^,]*)','\\1\\2,App Engine',line)
if line.find('big-query') != 1:
line = re.sub(r'(com.google.cloud\/services\/big-query)([^,]*),([^,]*)','\\1\\2,BigQuery',line)
if line.find('app-engine') != 1:
line = re.sub(r'(com.google.cloud\/services\/compute-engine)([^,]*),([^,]*)','\\1\\2,Compute Engine',line)
if line.find('cloud-sql') != 1:
line = re.sub(r'(com.google.cloud\/services\/cloud-sql)([^,]*),([^,]*)','\\1\\2,Cloud SQL',line)
csvout.write(line)
csvfile.close()
csvout.close()
## Measurement1 drop
df = pd.read_csv(o)
df = df.drop(columns=['Measurement1'])
df = df.reset_index(drop=True)
df.to_csv(o,index=False,mode='w')
- fortmatt
課金のサービス名(gceとかcloudstorageとか)を分かりやすく表示される為にMeasurement1カラムの値を基に、Descriptionカラムを置換
置換したらMeasurement1は必要ないので、削除してcsv出力
Unix時間追加
def convertime(i,o):
df = pd.read_csv(i, parse_dates=['Date'])
df['Time'] = df['Date'].apply(posix_time)
df['Date'] = pd.to_datetime(df['Date'])
df = df.sort_values(by=['Time'], ascending=True)
df.set_index('Time', inplace=True)
df.to_csv(o,mode='w')
- convertime
Grafanaの仕様でUnix時間を利用して時系列データにしないといけないので、「Start Time」(リネームしてDate)を基にしてUnix時間のカラムを追加
csvをMySQLにデータ挿入
def alltodb(csv):
df = pd.read_csv(csv)
engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s' % (user, password, host, port, dbname))
with engine.begin() as con:
df.to_sql('billing', con=con, if_exists="replace",index=False)
- alltodb
csvのデータをそのままテーブル[billing]に挿入する。
これだと、毎回テーブル丸ごと入れ替えるので、直近データのみを入れ替える処理も追加する。
直近のcsvをMySQLへデータ挿入
def datenumdays(n):
global to
global fro
today = datetime.today()
fromday = today - timedelta(days=n)
to = datetime.strftime(today, '%Y-%m-%d %H:%M:%S')
fro = datetime.strftime(fromday, '%Y-%m-%d %H:%M:%S')
def diffcsv(i,o,start,end):
df = pd.read_csv(i, index_col=3,parse_dates=['Date'])
#print(i,o,start,end)
#df2 = df['2018-08-31 19:03:49':'2018-09-03 19:03:49']
df2 = df[start:end]
df3 = df2.reset_index()
df3.set_index('Time', inplace=True)
df3.to_csv(o,mode='w')
def diffinsert(csv):
engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s' % (user, password, host, port, dbname))
q = 'DELETE FROM billing WHERE Date BETWEEN \''+ fro +'\' AND \''+ to +'\';'
#q = 'SELECT * FROM billing WHERE Date BETWEEN \''+ fro +'\' AND \''+ to +'\';'
res = engine.execute(q)
print(res.rowcount)
#for row in res:
# print(row)
df = pd.read_csv(csv)
with engine.begin() as con:
df.to_sql('billing', con=con, if_exists="append",index=False)
- datenumdays
n日(今回は4日)の日時をfroとtoに格納
- diffcsv
元のcsvから指定した期間のcsvを出力
- diffinsert
MySQLに接続して指定の期間のデータを削除
↑で出力したcsvをMySQLへ追加
main
def main()
args = sys.argv
argc = len(args)
print(args)
if (argc != 2):
print('Usage: # python3 %s diff(or)all ' % args[0])
quit()
csvs = getcsvlist()
csvjoin(csvs,'./tmp/csvjoin.csv')
formatt('./tmp/csvjoin.csv','./tmp/format.csv')
convertime('./tmp/format.csv','./tmp/billing.csv')
if args[1] == "diff":
print('diff')
datenumdays(4)
diffcsv('./tmp/billing.csv','./tmp/diff.csv',fro,to)
diffinsert('./tmp/diff.csv')
elif args[1] == "all" :
print('all')
alltodb('./tmp/billing.csv')
else:
print('Usage: # python3 %s diff(or)all ' % args[0])
quit()
引数で直近のデータ挿入か、丸ごとか選べるように条件分岐
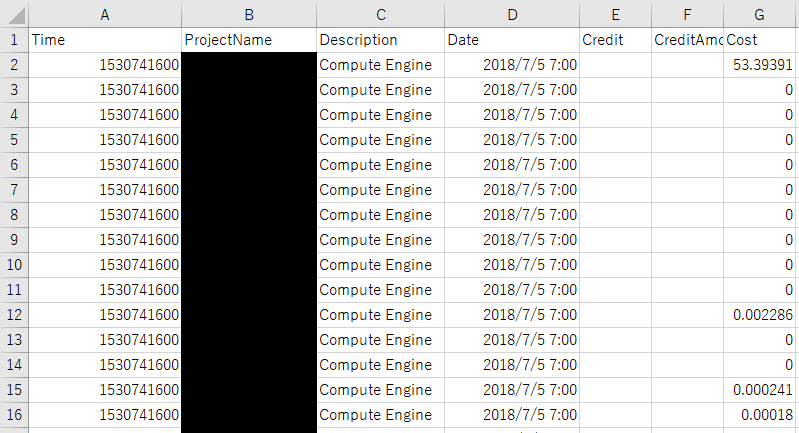
ちなみに最終的なcsvの形は以下になります。
大まかに分かればいいのでこういう形にしました。(本当はこんな省略しないでクエリで制御すればいいんだろうな。。)
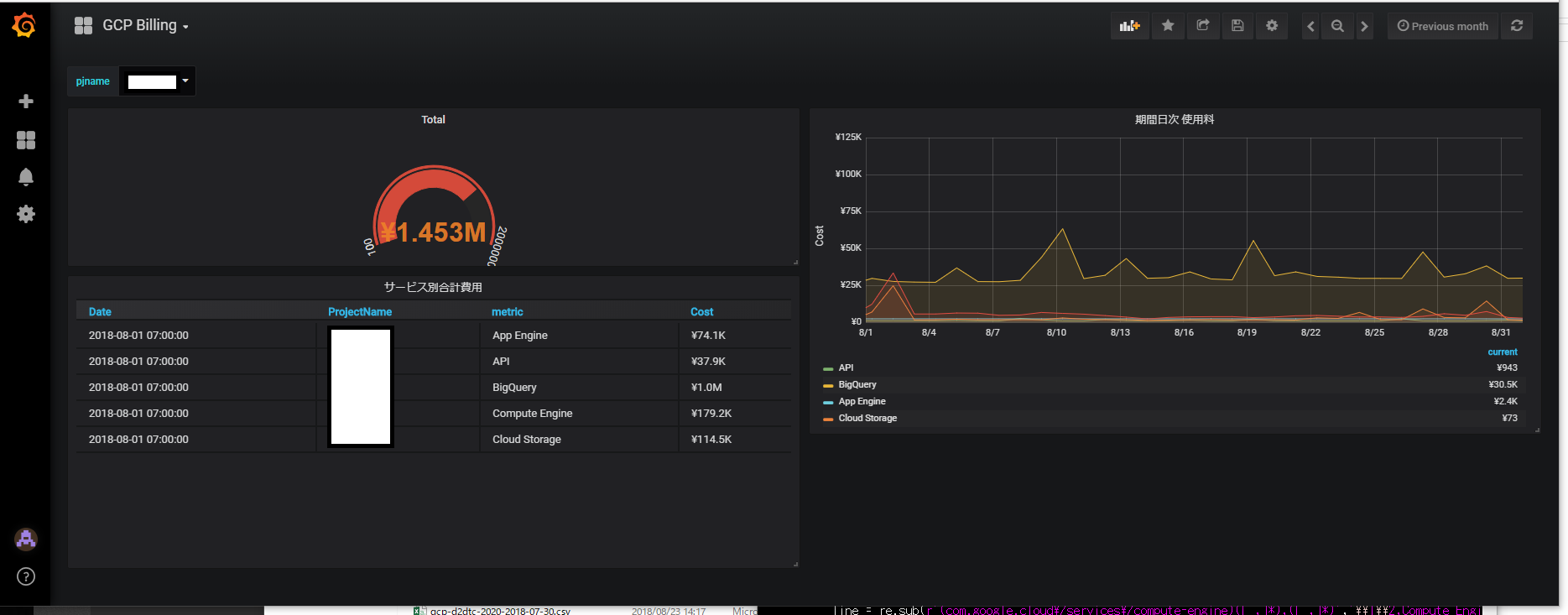
Grafanaで表示
プロジェクト別に、日次でのサービス別費用、指定した期間のサービス別費用、指定した期間のTOTAL費用を表示するようにしました。
select ProjectName from billing
SELECT
SUM(Cost) as Total
FROM billing
where Time BETWEEN '$__unixEpochFrom(Time)' and '$__unixEpochTo(Time)'
AND ProjectName=$pjname
GROUP BY ProjectName
ORDER BY Time DESC;
SELECT
Time as time_sec,
SUM(Cost) as value,
Description as metric
FROM billing
where Projectname=$pjname
GROUP BY metric, time_sec
ORDER BY time_sec ASC;
SELECT
Date,
ProjectName,
Description as metric,
SUM(Cost) as Cost
FROM billing
where Time BETWEEN '$__unixEpochFrom(Time)' and '$__unixEpochTo(Time)'
AND ProjectName=$pjname
GROUP BY metric
ORDER BY Time ASC;
感想
Python書くのもSQL文書くのも、初めてすぎて大変でした。。
たったこんだけやるのに4人日くらい掛かってます^^;