概要
東京都新型コロナウイルス感染症(COVID-19)対策サイトにて、陽性患者数の日別推移が掲載されています。同時にこのデータはオープンデータとしてCSVファイルで公開されているため、これをGoogle Colabのノートブック上で読み込み、Seabornで日別・年代別に可視化してみました。
別の切り口から推移を分析する際の土台としても使えるかと思い、ノートブックを公開します。
ノートブックのリンク
GitHubに置いてあります。
https://github.com/nekodango/tokyo_stopcovid19_opendata
ノートブックをGoogle Colabで実行する
-
上記GitHubリンクから「tokyo_opendata_covid19_patients.ipynb」をクリックして開く
-
「Open in Colab」バナーをクリックする
-
「ランタイム」> 「すべてのセルを実行」の順番でクリックする
実行するたび、その時点での最新データを取得して集計・描画します。
(2020/3/31現在、CSVデータの更新頻度は「毎日8:30更新」とのことです)
可視化結果
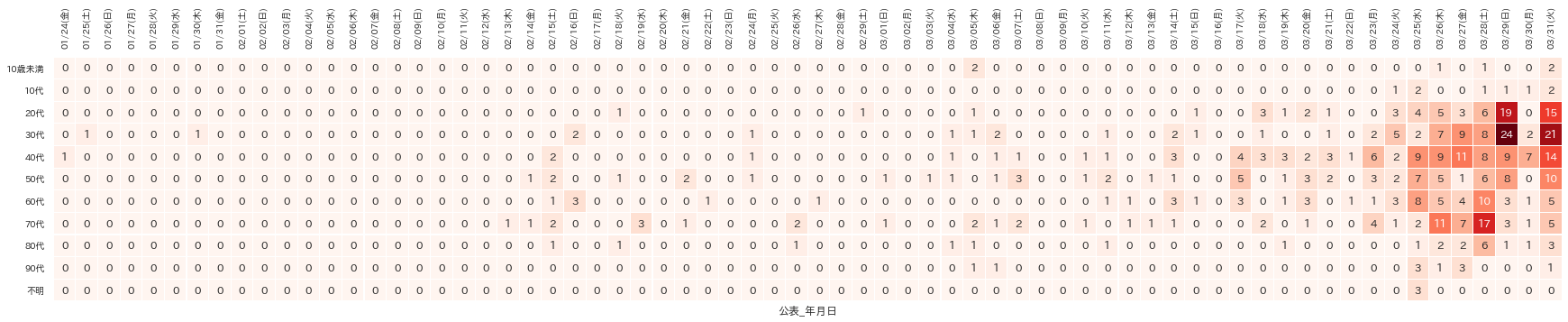
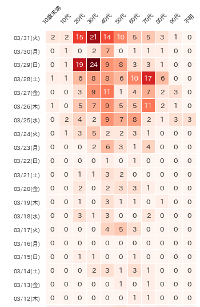
この3連休(3/27〜3/29)を境にして、20代・30代の陽性患者の増加に拍車がかかっているように見えます。
元データのヘッダを見ると、この日付は「発症年月日」ではなく「発表年月日」なので、解釈には一応注意が必要かと。
ノートブックでやったこと
ライブラリの読み込み
import pandas as pd
データの取得
wgetを使ってCSVデータをダウンロードします。
Google Colabでコマンドを実行する際は、"!"を先頭に付けます。(マジックコマンド)
!wget https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv
CSVデータをPandas DataFrameに変換
df_patientsにダウンロードデータが入ります。
df_patients = pd.read_csv('130001_tokyo_covid19_patients.csv')
df_patients['公表_年月日'] = pd.to_datetime(df_patients['公表_年月日'], format='%Y-%m-%d')
データを見てみる
この段階では、陽性患者1名につき1行のデータとなっています。
df_patients.head(5)

日別集計表を作成する
日付ごとの年代別陽性患者数を、集計表にまとめます。
df_tmp = df_patients[['公表_年月日', '患者_年代']]
df_tmp['人数'] = 1
df_tmp2 = df_tmp.pivot(columns='患者_年代', values='人数' )
df_tmp = pd.concat([df_tmp['公表_年月日'], df_tmp2], axis=1).fillna(0)
df_tmp = df_tmp[['公表_年月日', '10歳未満', '10代', '20代', '30代', '40代', '50代', '60代', '70代', '80代', '90代','不明']]
df_tmp = df_tmp.groupby('公表_年月日').sum()
df_dairy_patients = df_tmp.resample('D').mean().fillna(0)
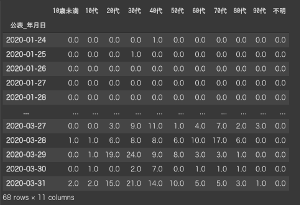
日別集計表を見てみる
df_dairy_patients
Seabornで日本語フォントを使えるようにする
Seabornで日本語を含んだグラフを描画できるよう、おまじないを唱えておきます。
これやっとかないと、日本語部分だけ「□」(いわゆる豆腐)で表示されます。
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
日付の曜日を日本語表示にする準備
「03/31(Tue)」より「03/31(火)」の方がわかりやすいので、期間中の日本語日付をdate_labelに入れます。
week = {'Sun': '日', 'Mon': '月', 'Tue': '火', 'Wed': '水', 'Thu': '木', 'Fri': '金', 'Sat': '土'}
date_monthday = list(df_dairy_patients.index.strftime('%m/%d'))
date_week = [week[x] for x in list(df_dairy_patients.index.strftime('%a'))]
date_label = [f'{monthday}({week})' for monthday, week in zip(date_monthday, date_week)]
ヒートマップの作成(横バージョン)
縦軸に年代、横軸に日付をとった陽性患者数のヒートマップを描画してみます。
# 画像のサイズを指定する
plt.figure(figsize=(30, 16))
# 横軸の日付を上部に持ってくる(デフォルトは下部)
plt.tick_params(axis='both', which='major', labelsize=10, labelbottom = False, bottom=False, top = False, labeltop=True)
# 横軸ラベル(xticklabels)に日本語表示の日付(date_label)を設定して、ヒートマップ描画する
sns.heatmap(df_dairy_patients.T, square=True, annot=True, cbar=False, cmap='Reds', linewidths=0.1, xticklabels=date_label)
前掲「可視化結果」のヒートマップが出力されます。
ヒートマップの作成(縦バージョン)
縦軸に日付、横軸に年代をとった陽性患者数のヒートマップを描画します。
直近の変化が見やすいように、新しい日付ほど上に来るよう並び替えて描画しました。
# 画像のサイズを指定する
plt.figure(figsize=(20, 30))
# 横軸の日付を上部に持ってくる(デフォルトは下部)
plt.tick_params(axis='both', which='major', labelsize=10, labelbottom = False, bottom=False, top = False, labeltop=True)
chart = sns.heatmap(df_dairy_patients.sort_index(ascending=False), square=True, annot=True, cbar=False, cmap='Reds', linewidths=0.1, yticklabels=list(reversed(date_label)))
# 横軸ラベルを斜め45度傾ける
_ = chart.set_xticklabels(chart.get_xticklabels(), rotation=45)
まとめ
新型コロナウイルス感染症対策を行う方々(特に患者数推移のデータを分析する方々)にとって、この記事のコードおよび手法が参考になれば幸いです。