はじめに
「機械学習するときは、まずデータセットを眺めて概要を掴んでから」といわれます。
PandasのDataFrameを可視化する方法としてPandas Profilingがメジャーですが、もう少しグリグリできるとうれしいです。
OSSのBIツールでアレコレしたら良い感じなのでは?と思い、最近人気急上昇のMetabaseとPandasを組み合わせる方法を共有します。
↓irisデータを読み込ませて、自動探査(X-ray)してみました。

このMetabase、使いやすさと見た目のかっこよさはダントツなのですが、データソースはデータベースからの読み込みのみ(ブラウザ上で「手元のcsvデータをアップロードしてインポートする」ができない)な模様です。そこで、Docker上にMetabaseおよびデータベース(PostgreSQL)を立て、そのデータベースに対してDataframeの中身を書き込みます。
環境
macOS 10.15
やり方
ファイル類はgithubにアップロードしてあります。以下コマンドでローカルに落としてください。
$ git clone git@github.com:nekodango/metabase-pandas.git
コンテナを立てる
Metabase・データベース(PostgreSQL)がまとめて立つようdocker-compose.ymlを書きます。
version: "3"
services:
metabase:
container_name: metabase
image: metabase/metabase:v0.33.3
environment:
MB_DB_FILE: /metabase-data/metabase.db
volumes:
- ./data/metabase_data:/metabase-data
ports:
- "3000:3000"
depends_on:
- postgres
postgres:
container_name: postgres
image: postgres:11.5
environment:
POSTGRES_DB: metabase
POSTGRES_USER: metabase
POSTGRES_PASSWORD: metabase
ports:
- "5432:5432"
volumes:
- ./data/postgres_data:/var/lib/postgresql/data
で、ターミナルからこのdocker-compose.ymlと同じディレクトリを開いて以下を実行してください。
$ docker-compose up -d
Metabaseの初期設定
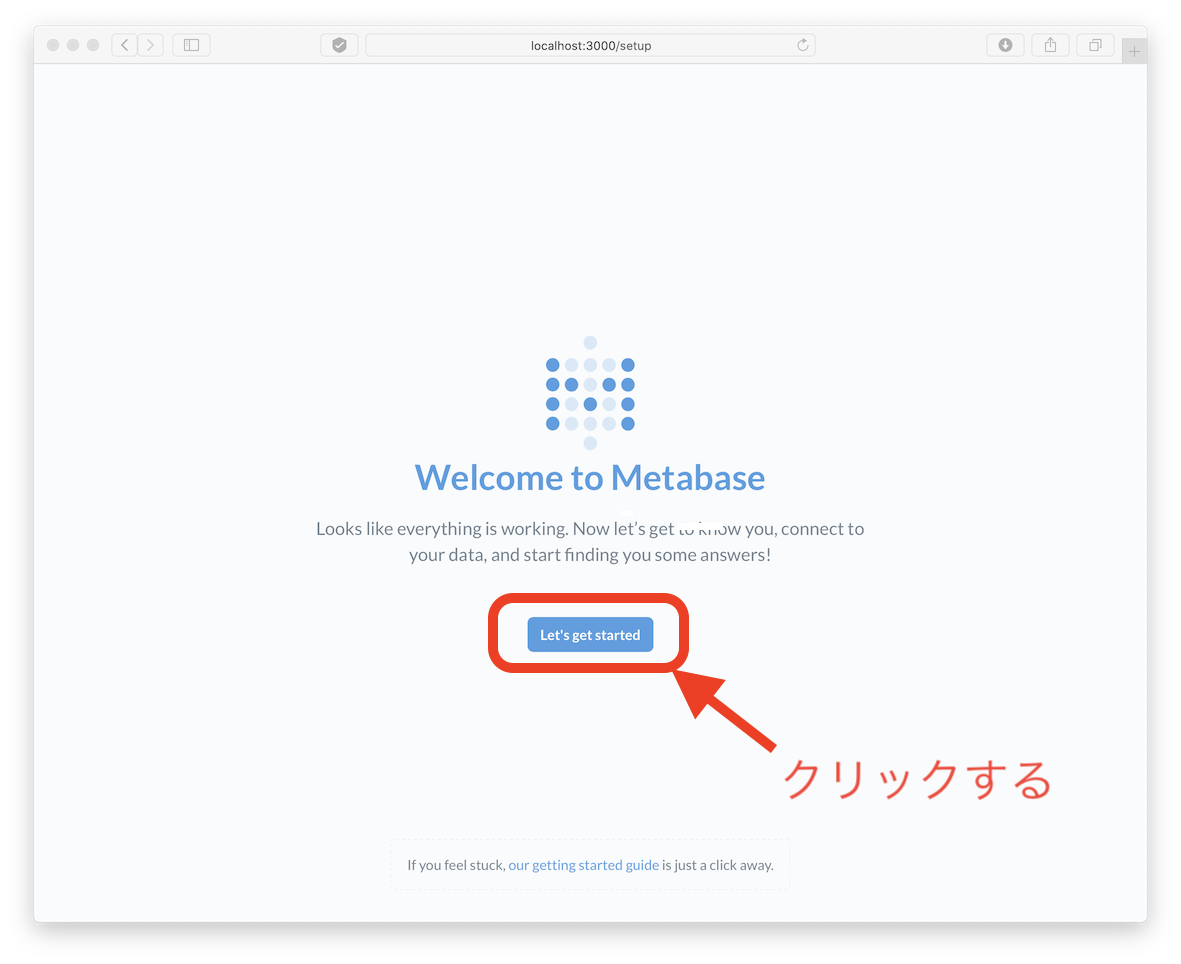
- ブラウザで http://localhost:3000 を開くと、以下の画面が出ます。

- 「Let's get started」をクリックすると、アカウント作成画面に進みます。
- 必要事項を入れます。
| 項目名 | 例で入れる値 | 備考 |
|---|---|---|
| ①姓 | neko | |
| ②名 | dango | |
| ③メールアドレス | metabase@example.com | 実在しないメールアドレスでもいける |
| ⑥会社名 | # | 空欄だと先に進めないので、何でもいいので入れる |

-
「Next」をクリックすると、

-
データベース設定画面になります。「PostgreSQL」を選んで、

- 必要事項を入れます。
| 項目名 | 例で入れる値 |
|---|---|
| ①設定名 | postgres |
| ②データベースのホスト名 | postgres |
| ③ポート番号 | 5432 |
| ④データベース名 | metabase |
| ⑤ユーザ名 | metabase |
| ⑥パスワード | metabase |

- 「Next」をクリックすると

- 「匿名データの提供に同意しますか?」と出るので、お好みでスイッチを切り替えてから「Next」をクリックすると

- 「Take me to Metabase」をクリックすると完了です。

表示を日本語に変更する
画面表示が英語のままなので、日本語にします。


一度ログアウトします。

Python環境を作る
Pandas,SQLAlchemy,Psycopg2をAnaconda環境に作ります。
$ conda create -n metabase python=3.6
$ conda activate metabase
$ conda install pandas sqlalchemy psycopg2
irisのcsvをデータベースに書き込む
import pandas as pd
import datetime
from sqlalchemy import create_engine
connection_config = {
'user': 'metabase',
'password': 'metabase',
'host': 'localhost',
'port': '5432',
'database': 'metabase'
}
engine = create_engine('postgresql://{user}:{password}@{host}:{port}/{database}'.format(**connection_config))
df = pd.read_csv('data.csv')
df.to_sql('iris', con=engine, if_exists='replace', index=False)
「data.csv」を同じディレクトリに置いた状態でこの「to_postgres.py」を実行すると、csvを読み込んでデータベースに書き込みます。
ここではirisのcsvをダウンロードして、「to_postgres.py」を実行してみます。
$ curl https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv -o data.csv
$ python to_postgres.py
データベースを同期する
データベースと手動で同期すると、いま投入したirisテーブルが出てきます。



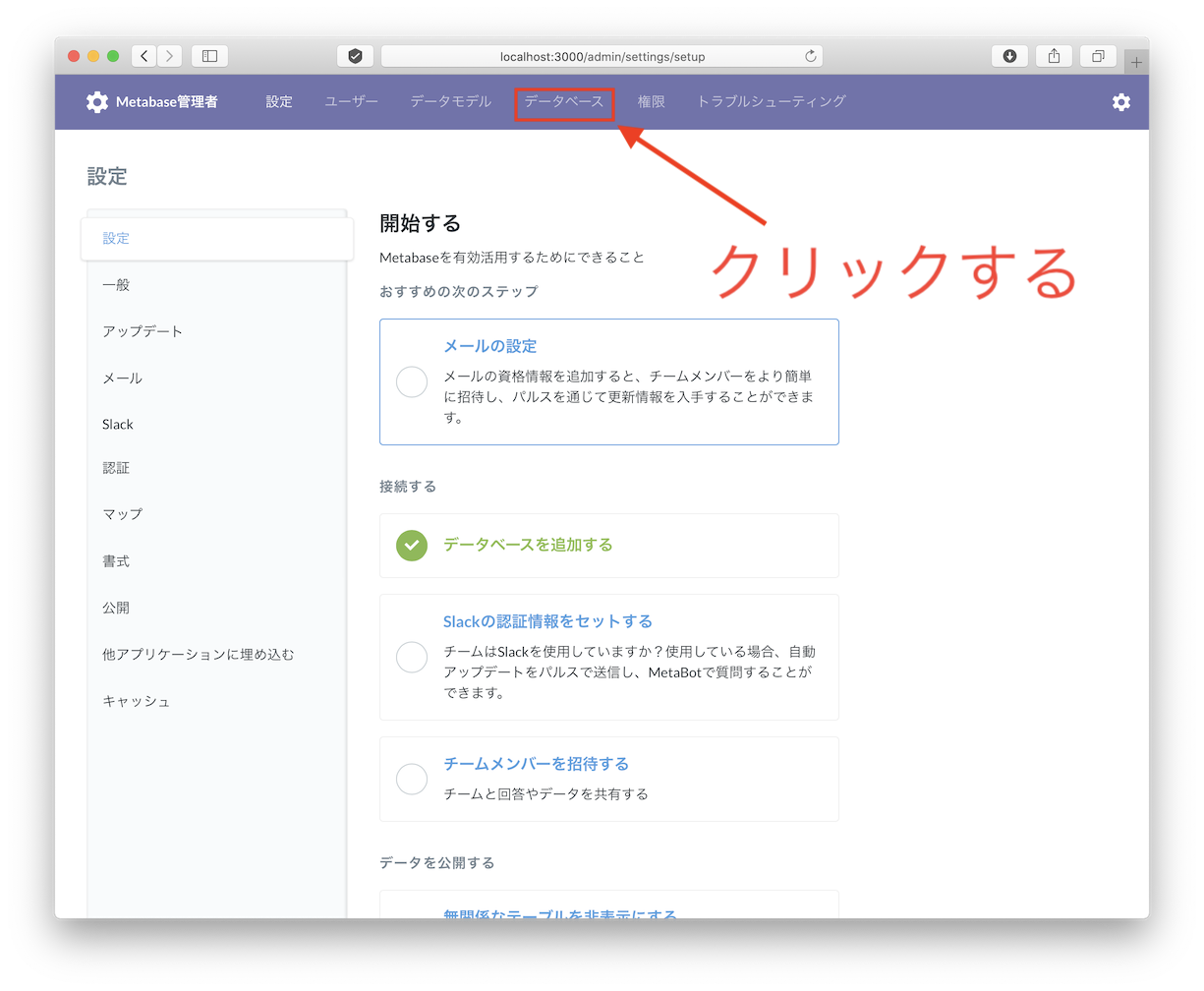

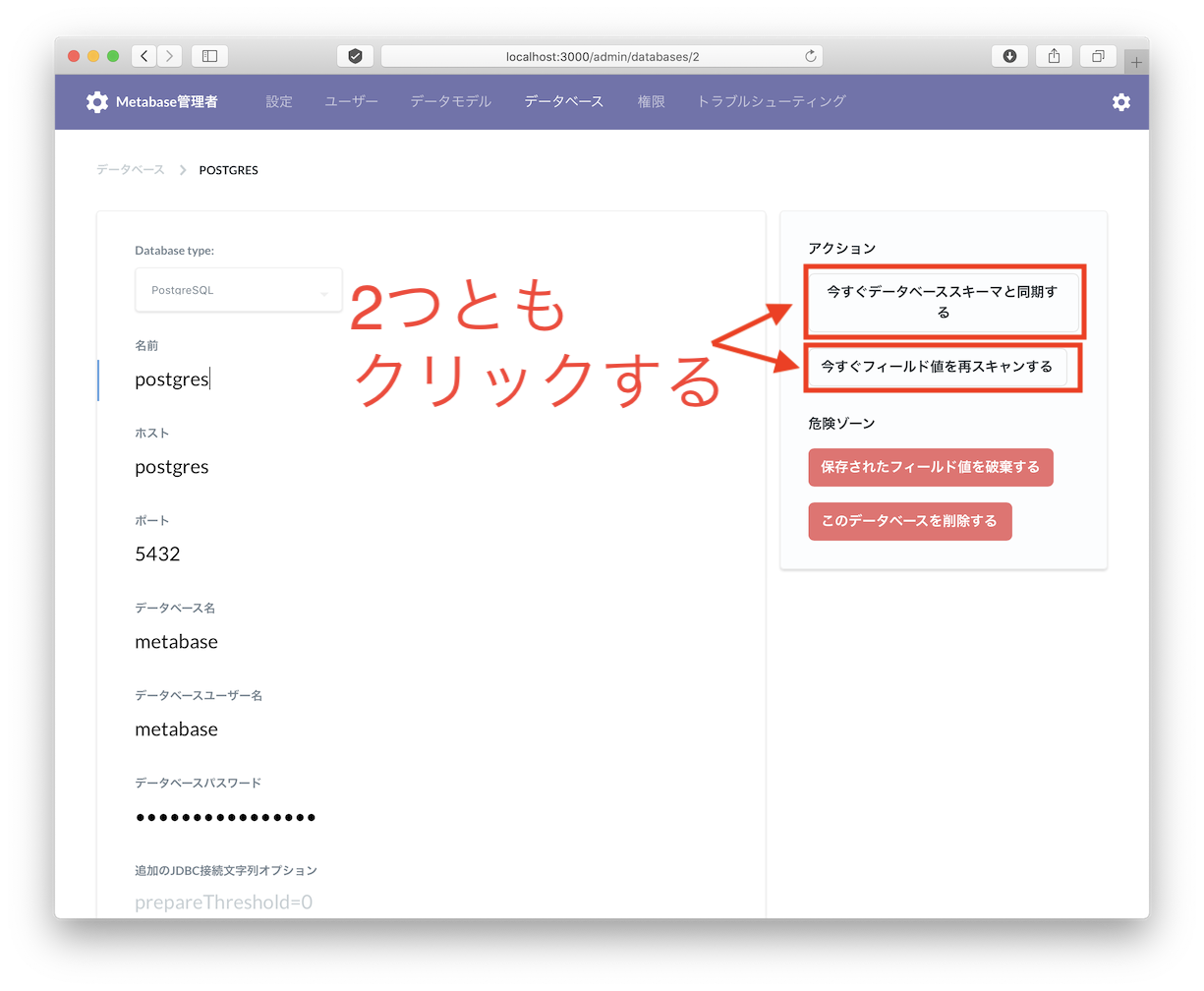

先ほど投入したデータが出ていることを確認する
動機が完了すると、先ほど作ったテーブルが表示されます。

自動探査(X-ray)できます。
