Of the Utmost Importance:
Resource Prioritization in HTTP/3 over QUIC という論文が公開されていたので読んでみました。
HTTP/3の優先度制御について、11個の異なる方法を比較検討しています。ウェブページのロードの実験を複数のサイトのデータを使って行い、その実験結果から利点欠点と今後の標準化への提案を行っています。
評価結果から、優先度制御の方法はシーケンシャルな方法のほうがラウンドロビンの方法より優れているということがいえます。また、すべての場合に速い方法はないので、複数の実装が許容されているほうが良いようです。そして、サーバ側はウェブページのロードを早くするうえで重要なリソースを知っているのでその情報をクライアントに通知できるとよいと主張しています。
ちなみに、HTTP/3からは優先度制御は削除されるという結論になったようです。
- HTTP のプライオリティが大きく変わろうとしている話(その他 IETF 105 雑感)
- Remove PRIORITY #2922
読んでみた所感は
- ウェブページのロード時にラウンドロビンにリソースを割り振るよりも、リクエストが来た順にシーケンシャルに処理したほうが良いのが参考になった。
- ウェブページのロードに限定しても常に優れた優先度制御の方法は存在しない。
- 標準化とはいえ各社自分たちに有利な技術を入れたがるので、HTTP/2の優先度制御は複雑になってしまったのだと思った。
- サーバ側は何が重要なリソースか知っているので、それをクライアントに通知するのは確かに効果がありそう
です。
以下内容をメモしたものになります。
2 HTTP/2 PRIORITIZATION
2.1 Background: web page loading
ウェブページを構成する複数のリソース
ウェブページはHTML、 javascript、 CSS、 フォントファイル、 画像ファイルなど異なるリソースから構成されます。これらのリソースは重要度が異なります。また、ページをロードする過程でそれぞれが異なる役割を果たします。
ウェブページのロードでは、HTMLを順番にパースしていきます。
JavascriptとCSSは、実行と適用されるためにはすべてダウンロードされていないといけません。さらに、CSSは、新しいCSSをインクルードしたら、そのCSSが継続するHTMLがどのように見えるかに影響するかもしれないのでHTMLのレンダリングをブロックします。また、javascriptは、HTMLの構造を変えかねないため(要素を消したり追加したりできる)パースをブロックします。
ウェブページのロードには、クリティカルパスがあります。ウェブページのロードにおけるクリティカルパスという概念(Tangari et al., 2019) があります。そのパス上にあるリソースの遅延がページロードの遅延につながります。
結論として、典型的には、HTMLから参照されているJSとCSSは、可能な限り速くダウンロードされている必要がります。
事前に必要になるリソースが分からない
ブラウザは事前に必要となるリソースをわかりません。ページをロード中にその情報を徐々に得ることになります。それらの多くはHTMLに直接書かれていますが、フォント、背景、APIデータなど多くがCSSやjavascriptからインポートされます。また、それらはCSSやjavascriptが完全にダウンロードされて実行されてから見つかります。典型的には、HTMLの内部で記述されているのが見つかってからリクエストされます。
すべてのリソースの重要度が高いわけではない
ユーザーは典型的には、ページ全体をすぐに見たいわけではありません。例えば、スクリーンの高さより下はすぐに見る必要がありません。すぐに見る場所は、Above The Fold (ATF)呼ばれています。ATFにある大きい画像は、Below The Fold にあるものより重要と考えられています。同様に、ページのメインのコンテンツを取得するAPIを呼び出すjavascriptは、別のSNSとの共有ボタンなどに使われるjavascriptよりも重要です。
まとめ
ウェブページは、HTML、javascript、CSS、フォントファイル、画像などの異なるリソースから構成されます。これらのリソースはユーザーにとって重要度が同じなわけではありません。またこれらのリソースをすべて組み合わせるとウェブページのロードには複雑な依存関係が発生します。それぞれのリソースの重要性は、そのリソースの種類、機能、HTMLのどこに書かれているか、そして、どれくらいリソースの依存関係を含んでいるかに依存します。
それらの情報は、ページのロードを開始した時点ではわかりません。ブラウザはページのロードに必要な複数のリソース、異なるリソース間の重要度、それらの依存関係が分からないため、リソース間の相対的な重要さを複雑なヒューリスティックに頼って決めてウェブページをロードしています。
2.2 Dependency tree: what and why?
クライアントは、HTTP/2の優先度制御システムを使って、サーバのリソーススケジューリングを制御します。HTTP/2では、クライアンがPRIORITY frameという制御メッセージを使うことでサーバに望ましいスケジューリングを通知することができます。
Dependency Tree
サーバ側は、異なるストリームを一つのノードとして扱うdependency treeでスケジューリングを制御します。
通信帯域は以下のシンプルな2つのルールでノードに分けられます。
- 親は子より先にすべて転送される
- 兄弟ノードは帯域を分け合う
例えば、あるノードAの重みが128、Aの兄弟Bの重みが64だとします。理想的にはパケットのシーケンスは、AABAABAAB... となります。
ブラウザは内部のヒューリスティックをツリー構造に落とし込みます。ツリー構造は、とてもフレキシブルで、たくさんのアプローチを可能としています。しかし、実際によいヒューリスティックのマッピングを決めるのは自明ではありません。なぜなら、ページロードの過程で新しいリソースが見つかるからです。
もし新しく見つかったリソースが、すでにツリーの中にあるノードより優先度が高かったら、ブラウザは優先度制御を初期化したいです。そのため、新しいノードを何とか今あるノードより帯域が割り当てられるように追加する必要があります。同じ効果を得るために、既存のリソースの優先度を下げる方法もあります。
このような、優先度の変化に対応するために、ツリーの構造とスケジューリングロジックは非常に不安定で複雑になります。
HTTP/2では、このような複雑性に対応するためにクライアントに柔軟で多様な方法で優先度の再設定する方法を提供しています。
1つめは、ノードに子供を追加する方法を複数提供することです。non-exclusiveは、親に子供として追加します。exclusivelyは、siblingをすべて自分の子供にして追加します。これによって、一つの操作でアグレッシブに、ノードのグループの優先度が変わることになります。
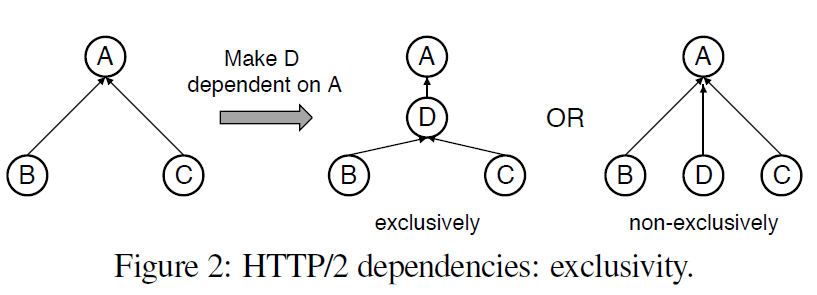
2つ目に、ノードに対して、そのノードに依存するノードをグループにする'placeholder'という概念です。placeholderは実際のリソースである必要はありません。
サーバはパケットを送信するときに、依存関係の木を(再)構築してどのリソースを送るかを決めます。頻繁な再構築によって、適切に次に送るリソースを決めることがきわめて非自明で計算負荷が高くなります。また、リソースが多くなるとメモリ負荷も高くなります。それを防ぐために、送信が終わったノードを消すことができます。ただ、それによってクライアントがすでに消されたノードに対して子供を追加しようとしたときにも問題が起きてしまいます。
これに関して、HTTP/2のサーバはルートの子供としてつけるというフォールバックがあります。しかし、これによって望むことなくそのリソースの優先度を上げてしまいます。つまり、優先度が高いノードと同じ優先度になってしまいます。
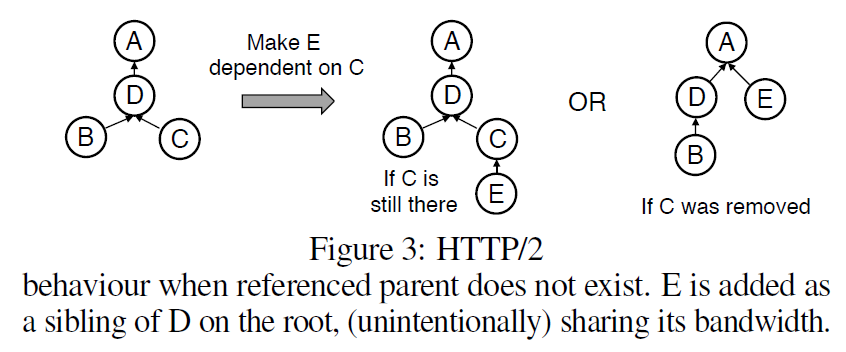
このデフォルトフォールバックの問題は、例えばサーバプッシュなどの別な状況でも起きる可能性があります。HTTP/2ではクライアントとサーバのツリーの同期は行われません。言い換えるなら、連続した、あるいは、明示的な同期がサーバとクライアント間で行われないため、適切なスケジューリングに対してクライアントとサーバ側で異なる見方をしている状態になりえます。その結果予期せぬ動作をするかもしれません。
著者は、このように複雑なセットアップがあるのに、最初にクライアントが決めるのはなぜかという点を疑問に思っています。なぜならサーバ側はリソースを知っているからサーバが決めればいいからです。
その場合、サーバ側にはクライアントのPRIORITY メッセージを無視する仕組みが必要になります。また、最適なスケジューリングを自身で決める必要が出てきます。
また、ウェブページのロードのユースケースをサポートするには複雑すぎます。シンプルにする方法がいくつかHTTP/3で提案されています。
SPDYは8レベルのシンプルな形だったのに、なぜ、複雑な優先度制御が採用されたのでしょうか。メーリングリストやスレッドなどの会話から集めた情報によると、cross-connection prioritizationのようなより進んだユースケースをサポートしようとしたことが理由のようです。
あるパーティーは、一つのHTTP/2のコネクション上に複数のHTTP/2のコネクションを張ろうとしました。例えば、一般的なproxy/VPNや、CDNのロードバランシング/エッジなどが考えられます。エッジサーバーが、多くのユーザーからのコネクションを受け付けます。そしてそれらのデータを一つのHTTP/2のコネクションでオリジンのサーバに対して接続して対応します。また、クライアントごとに優先度をつけたい場合なども考えられます。
そのような場合に、複数のクライアントをまたいだ優先度制御を行う場合に、とても巨大なdependency treeが必要になります。
他のユースケースは、ブラウザが同じウェブサイトに対して複数のタブ、ウィンドウで、1つのHTTP/2コネクションをシェアして接続する場合です。今見えているページは優先度を高くします。これもタブをまたいだ複雑なdependency treeで実現できます。
ブラウザ、CDN、プロキシ、ウェブサーバ、のどれも、著者の知る限りではそのような複雑なものは実装されていません。シンプルなユースケースでさえ、ほとんど最適化されていない、あるいは適切に実装、デプロイされていないのが現状のようです。
(ここまで見た)
2.3 Related work: Theory vs Practice
HTTP/2 Prioritization and its Impact on Web Performance
10種類のブラウザの優先度制御の方法を調べる研究です。
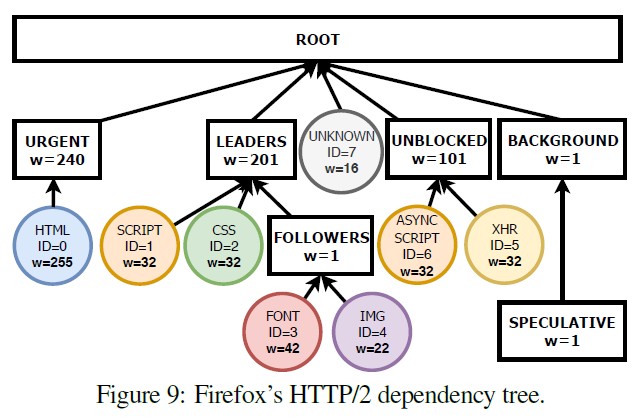
Firefoxだけが複数のレベルのplaceholderを使った非自明な優先度制御木を実装していました。Chromeはシーケンシャルな実装を行っています。すべてのリソースが親ノードにexclusivelyに追加されます。Safariはinterleaved modelを実装しています。すべてのリソースはnon-exclusivelyにrootに追加されます。Chromium engineになる前のEdgeは優先度を無視します。つまり、すべてのリソースをルートに重さ16で追加します。(=ラウンドロビン)。この中で、ラウンドロビンが一番悪い結果になりました。
Tracking HTTP/2 Prioritization Issues
いくつかのHTTP/2の実装が、どのくらい厳密に(再)優先度制御を実装しているか調べた研究です。最初に低い優先度のものをリクエストして、そのあとすこし遅れて優先度が高いリソースをリクエストします。正しく優先度制御をしていれば、優先度が高いものが先に送られてきます。
この論文では35個のCDNとHTTP/2のウェブサーバで実験しています。その結果、9個だけが適切に優先度制御を実装していることが分かりました。
こうなっているのにはいくつかの理由があります。一つ目の理由は間違って実装している場合や、サーバがクライアントのPRIORITYを遵守しない場合がある点です。二つ目の理由は、優先度制御木が適切に構築されていても、実装の非効率さによってmis-prioritizedが起きている点です。3つ目の理由は、多様な形のbufferbloatが原因になっています。例えば、大きいバッファを使う場合、優先度が低いデータでバッファがいっぱいになってしまうリスクがあります。ネットワークに出てしまったパケットやカーネル空間のバッファは、優先度が高いリソースを先に送信しようと思ってもクリアすることができません。
Optimizing HTTP/2 prioritization with BBR and tcp_notsent_lowat
バッファサイズが大きすぎると、優先度が高いリソースへのリクエストが来る前に、優先度が低いリソースがバッファに入る可能性があります。特にネットワーク上やカーネル空間のバッファにリソースが入ると、優先度が高いリソースが必要になったときにクリアすることはとても難しいです。この調査では、アプリケーションレベルのバッファサイズの制限とBBRによってその問題を解決しています。
Better HTTP/2 Prioritization for a Faster Web
BrowserのヒューリスティックやHTTP/2の依存関係へのマッピングは最適ではないとしてbucket と呼んでいる手法を提案しました。
HTTP/2に限らない、ブラウザの最適なヒューリスティックと優先制御の関連研究
Demystifying Page Load Performance with WProf は、リソースの依存関係とそれによるページ全体のロード時間への影響の研究。クリティカルパスを求めて、それをもとにリソースをロードする順番を事前に決める方法を提案しています。
Polaris、Shandian 、Vroom では、JSのメモリヒープのレベルまでブレイクダウンしたページロードの情報を集めて、複雑なリソースの送信とスケジューリングの計算スキームを構築しています。PolarisとShandianは、medianで34%-50%性能が向上しました。Vroomは、flat medianで、5秒ロード時間を減らしています。
[Akamai](Accelerate your website with minimal development effort.)では、エッジサーバーから統計情報を集めて、どのリソースが速く必要されているかを判断し、それらのリソースは明示的なリクエストなしにプッシュ送信しています。
この時点では、Cloudfareだけが、高度なHTTP/2の優先度制御を実装しています。これによって、オリジナルのEdgeより50%早くなっています。また、アプリケーションで、顧客自身で優先度を設定できるようにしているようです。
全体として、高度なサーバ側での優先度制御は、現実では相対的に証明されていないといえます。また多くのPRIORITY メッセージを無視しているサーバは、最適なカスタムスケジュールロジックを採用していません。
3. HTTP/3 Prioritization
優先度制御は最近になって、大きな変更を加えようという議論が出てきました。
その理由の1つ目は、dependency treeの設定は複雑で、現実では使われていない点です。2つ目は、QUICの独立したストリームに対して、優先度制御を自明な方法ではポーティングできない点です。
最初に、どの問題が認識されていて、どの解決方法がv20で取り込まれたのかについて述べます。それから、なぜ、どのようにして、それらがv21で変更されたのかを取り上げます。
3.1 Before draft 21
大きな問題は、Exclusive dependenciesです。これは、PRIORITY メッセージの順番に大きく依存します。PRIORITY メッセージはリソースのストリームで送信されるため、パケットロスやジッターによって順番が変わると、dependency treeのレイアウトが非決定的になってしまいます。
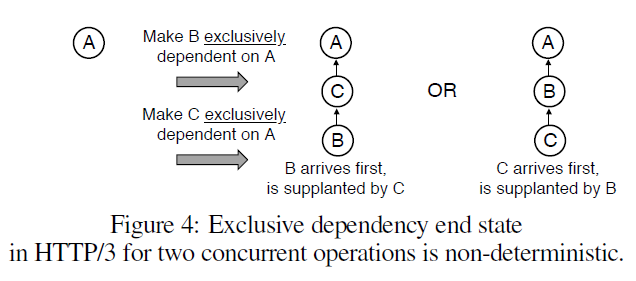
Figure 4 では、メッセージが到着する順番によってdependency treeの形が変わります。
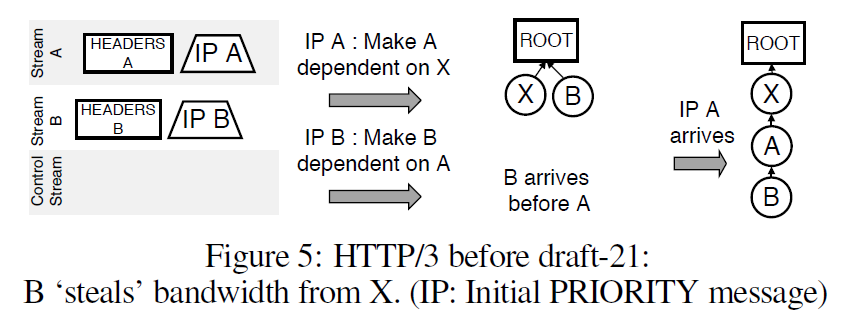
元々の解決方法は、exclusive dependencyを削除することでした。しかしそれでも、exclusive dependency以外の問題を起こしてしまいます。
例えばリクエストAの直後に、Aを親とするリクエストBが送信されます。この時に、BがAより先につくと、Aはdependency treeには存在していません。
この場合2つの選択肢があります。Bをルートに追加するか、初期化されていないAを追加するかです。しかし2つ目のケースであっても、Aはルートに追加されてしまいます。なぜなら、Aの親がどれかわからないからです。
これによって新しいストリームが、優先度の高いストリームと帯域を分け合ってしまうという問題が起きます。
この解決方法は、単に無視することが考えられます。Aがすぐに到着することを考えると、Bの優先制度の設定ミスは長い目で見ると問題にはなりません。しかし、long-fat network (帯域が大きくて、レイテンシも大きい)の場合は、少なくともRTT1回分は優先度が間違った状態になってしまいます。もしBが小さくて、輻輳制御ウィンドウが大きかった場合、Aの再送が到着する前にBの送信が終わってしまいます。
優先度を更新する場合に部分的にこの問題を緩和する方法があります。HTTP/3はcontrol streamを持っています。これは単一のストリームなので、すべてが順番になります。そうするためにdraft20では、PRIORITY メッセージをストリームの最初のデータとして送り、それ以降はcontrol streamで送るようにしました。
しかし、これでもすべてのエッジケースを解決できるわけではありません。より良い可能性がある方法として、初期のPRIORITY メッセージもcontrol streamで送るという方法が提案されました。
これによって、決定的にdependency treeを構築できるようになります。しかし、もしリクエストしたストリームのHTTP Headerが最初のPRIORITY メッセージよりも先に到着してしまうと、そのノードはルートの子供になってしまいます。
この問題を防ぐためにplaceholderを再考します。しかし、もしplaceholderを使ったとしても、Figure 3の問題に苦しめられてしまいます。サーバはどのノードがplaceholderなのかが分からないためそれらを木から消してしまうことが起こるためです。
なので、HTTP/3ではplaceholderを明示的に木全体からわけることにしました。優先順位設定用のplaceholderを接続の開始時に作成し、placeholderを削除しないようにします。そうするとplaceholderに依存するノードは最初から存在することになり、依存先がルートになり優先度が高いリソースと帯域を分け合う問題は起きなくなります。
ただし、これはシーケンシャルなdependency chainにはあわない方式になります。しかし、exclusive dependencyが削除されたので、ノードはplaceholder以外のノードに依存することができるようになりました。
3.2 draft-21
WGには、HTTP/2に近い方法を採用するか(exclusive-prioritiesを再度採用する)か、もっと大きな変更を伴う方法を採用するかの選択肢がありました。後者に関して、HTTP/2で採用していた方法と同等かより優れた方法が必要なので、実装や実験結果が必要と考えられていました。
結果として、当面は、HTTP/3の優先度制御はもともとのHTTP/2に近づけることになりました。
その方法は以下の2つの変更で実現されています。
一つ目は、すべてのPRIORITY メッセージがcontrol stream経由で送信される点です。これによって、exclusive-dependencyが再登場しました。
ただし、PRIORITYフレームがロストする場合の問題が再度発生します。control streamのロスが発生すると、PRIORITY メッセージは届かなくなります。その結果、優先されないリソースがルートに直接接続されることが起きる状態は改善されていません。
この問題への対処方法は、デフォルトのフォールバックを変えることでした。この時点では、デフォルトで優先度がない場合はルートの下に重み16でついてしまします。しかしこれは、他の優先度が高いノードのリソースを奪ってしまう。
そこで二つ目として、Orphan Placeholder が提案されました。これは、rootとは別にplaceholderを用意し、優先度が設定されていないノードはそこの下に追加します。rootの下で帯域が使われていない場合のみ帯域が割り当てられます。
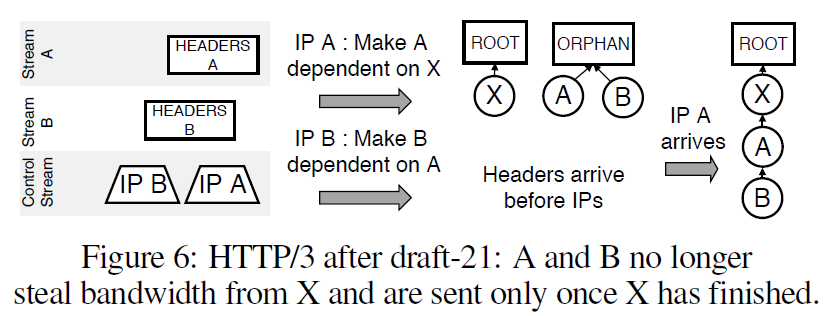
3.3 Alternatives for HTTP/3 priorities
提案前の話
Draft21の前に、HTTP/2の優先度制御の代替案がいくつか提案されていました。それらの提案には4つの課題を解決する方法が含まれています。
一つ目は、ラウンドロビンが多くのウェブページのロード時に望ましくないという点です。優先度が高いリソースはなるべく早くダウンロードされることが望ましいです。しかし、ラウンドロビンは重要なリソースのダウンロードが他のリソースによってインターリーブされるので、ダウンロードが完了するのが遅くなってしまいます。
なので、そのような重要なリソースはシーケンシャルにダウンロードできることが望ましいです。一方で、Progressive Imageなどの優先度が低いリソースはラウンドロビンがより適していることもあります。
この時点では、HTTP/3には排他的なリソースの設定がサポートされないことが決まっていたので、多くの提案にはどのように排他的なリソース設定をサポートするかが含まれていました。
二つ目は、placeholderのオーバーヘッドです。接続時に生成され、接続が終わるまで削除できないという点です。これによって、攻撃者が多くのplaceholderを生成することでメモリベースのDoS攻撃が可能になってしまいます。
対抗策としてサーバ側でplaceholderの制限をするという手段があります。しかしどのくらいplaceholderがあれば十分かを決めることは難しいです。またいくつかの提案では合理的な理由で多くのplaceholderを必要とします。
そのような状況なので、placeholderの数の制限や、placeholderを削除する提案が行われていました。
三つ目は、多くの人がHTTP/2の優先度制御は複雑なので、実装しやすいほうが好ましいという点です。
四つ目は、多くの人がクライアントとサーバのスケジューリングの組み合わせて使うことが必要で、両方の情報を使うことにはメリットがあるという点です。
理論的には、クライアントが設定した優先度をサーバが上書きすることは可能ですが現実的には難しいです。なぜなら、クライアント自由に異なる方法でdependency tree を設定するため、サーバ側でそれを推測することが難しいからです。これによって、手動でリソースの優先度を正しい場所に入れることは困難になります。
提案の話
ここからは著者の提案を含む3つの提案を紹介します。
一つ目の提案は、CloudflareのPatrick Meenanによる、bucketです。
この提案では、dependency treeの代わりに'priority bucket' を定義します。
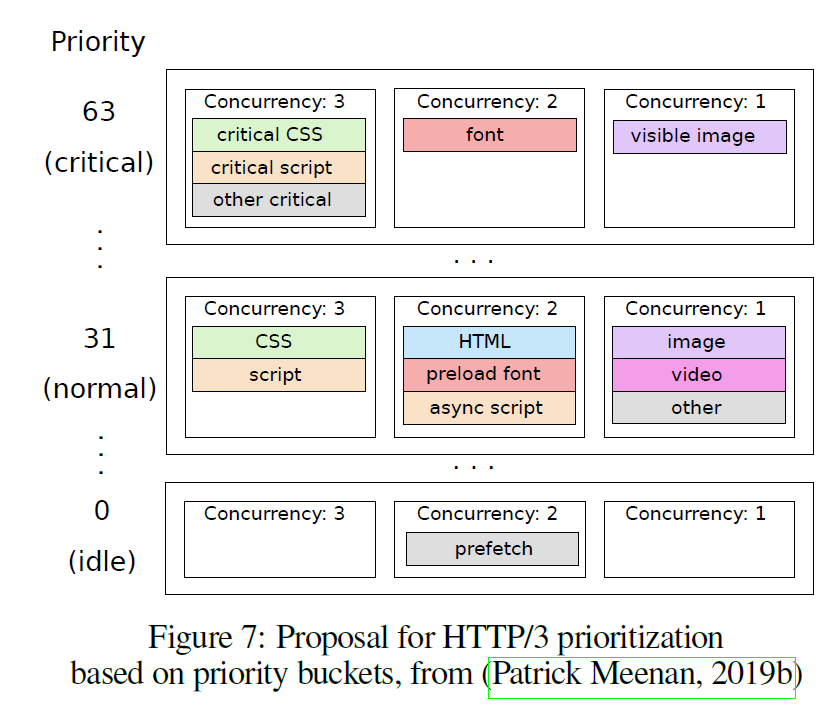
優先度が高いバケットは優先度が低いバケットよりも先に処理されます。そして、バケット内で3つの優先度が存在しています。バケット内では、concurrency 3が最初に処理されます。concurrency 3内ではストリームIDが小さい順に処理されます。
concurrency 1と concurrency 2は、concurrency3が空の時にそれぞれ50%ずつ帯域が割り当てられます。concurrency 2では、ストリームIDが低いものから順番に処理されます。concurrency1 はラウンドロビンで処理されます。
この方法は、1ストリーム毎に伝える情報が1バイトの優先度とconcurrency numberのみと少なくなっています。また、リソースの移動も簡単にできます。ただし多くのリソースを一度に設定を変えるのは不可能のようです。
この方法であれば、優先度設定が明確なので、サーバからのdirectiveを送るのも容易になります。
サーバから優先度の変更を指示したい場合、優先度の順番が明確なので容易になります。
'strict priorities'
2つ目の方法は、GoogleのIan Swettが提案したbucketと既存の優先度制御木を組み合わせた方法です。
ノードは、優先度とウェイトの両方を持ちます。高い優先度を持つ兄ノードは他のよりも先に送信されます。
そして、ストリームが相互に依存することを許しません(=placeholderだけを親に持つことができます。)。
この方法では、exclusive dependencies無しで、シーケンシャルな送信を実現します。なお、この方法は理論的にbucketと同じであるため評価はしていないようです。
zeroweight
これは著者が提案している手法です。この手法では、ノードに0から255の値を重みとしてもたせます。そして、0と255には特別な意味を与えます。兄弟ノードの中で重みが255のものが、ストリームIDが小さい順に処理されます。次に、254-1までの重みのノードが重み付きラウンドロビンで処理されます。最後に、他の兄弟がすべて処理されたら、重み0のものがストリームIDの小さい順に処理されます。
この方法は、HTTP2の優先度制御から微小な変更で実現できます。
これらを含めて、優先度制御の議論については、https://github.com/quicwg/wg-materials/blob/master/interim-19-05/priorities.pdf が詳しいようです。
これらの優先度制御の提案は、どれもすごく新しいアイディアを提案しているわけではありません。基本的なコンセプトはラウンドロビンVSシーケンシャルになっています。提案手法毎に、実装の容易さ、オーバーヘッド、優先度の再設定、粒度などが違うようです。
比較対象の手法
本論文では、以下の11の手法が検証されています。

比較方法
それぞれの手法の比較は、HTTP/2 Prioritization and its Impact on Web Performance で使っている42の実際のウェブサイトを保存して使います。それと追加で、2つテスト用のページが使用されています。一つは著者が用意したもので、もう一つはHTTP/2 priorities test page.
Onlineで紹介されているものです。
サーバ側はQuickerが使われています。Quickerを使ったのは高レベルの言語のため優先度制御が実装しやすかったかららしいです。クライアント側はブラウザの実装がないので、Quickerのコマンドラインを使う。ブラウザに近づけるために、WProfXを使っている。
WProfXのChromeの拡張で、リソース間の依存関係や、クリティカルパスなどウェブページのロードを解析することができます。
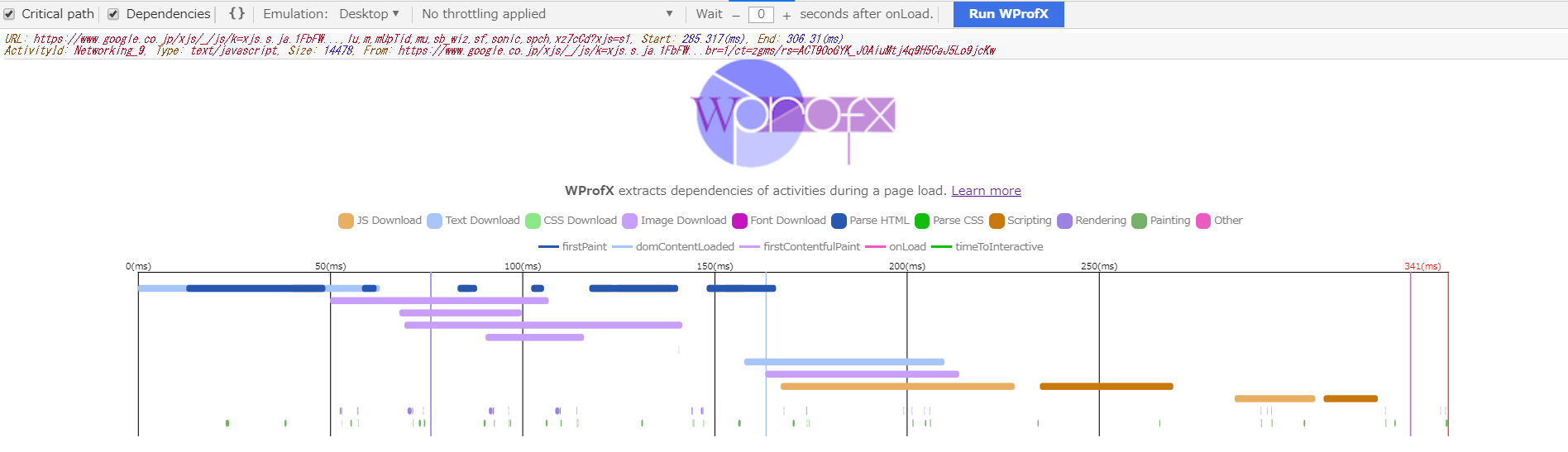
著者は、一度ローカルで、H2OとChromeを使って、それぞれのテストコーパスの解析を行いました。その結果をもとに、Quickerのクライアントで、依存関係をもとにレコードした結果をリプレイしています。
オープンソースのQUICのスタックには、TCPの輻輳制御と同等の性能が出る輻輳制御の実装がないようなので、輻輳制御は行わずに実験をしています。優先制御の性能に注目するため。1ストリームのレスポンスを含む1400byteのパケットを、10msごとに送るようにしているようです。
これによって、ネットワークの輻輳と再送がない状態での理想の上解を与えることができると著者は考えています。
輻輳制御の代わりに、アプリケーションレベルでのバッファサイズのサイズによるbufferbloatの影響と、jitterを加えた場合の独立したストリームに対する影響を確認しています。
評価指標には、Above The Fold(ATF)を使っています。ATFには、典型的には、HTML、重要なjavascript、 CSS、すべてのフォント、ヒーローイメージが含まれます。クリティカルパスになるものは、WProfXで計算したものを主に使っています。
また、bucket/zero weightの手法では、サーバ側でヒーローイメージなどの画像に手動で高い優先度を設定しています。
評価手法は、Time-To-Completion (TTC)ではなく、ByteIndexを使っています。ATFのリソースが何%ダウンロードされているかを100msごとに計算する。下の図のように、その値をもとにグラフ上の線の上の部分の面積を求めています。
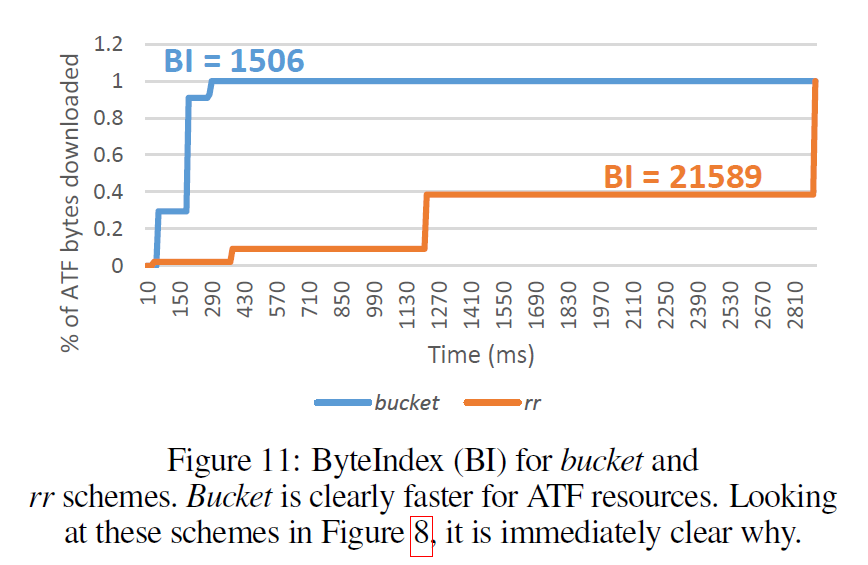
結果
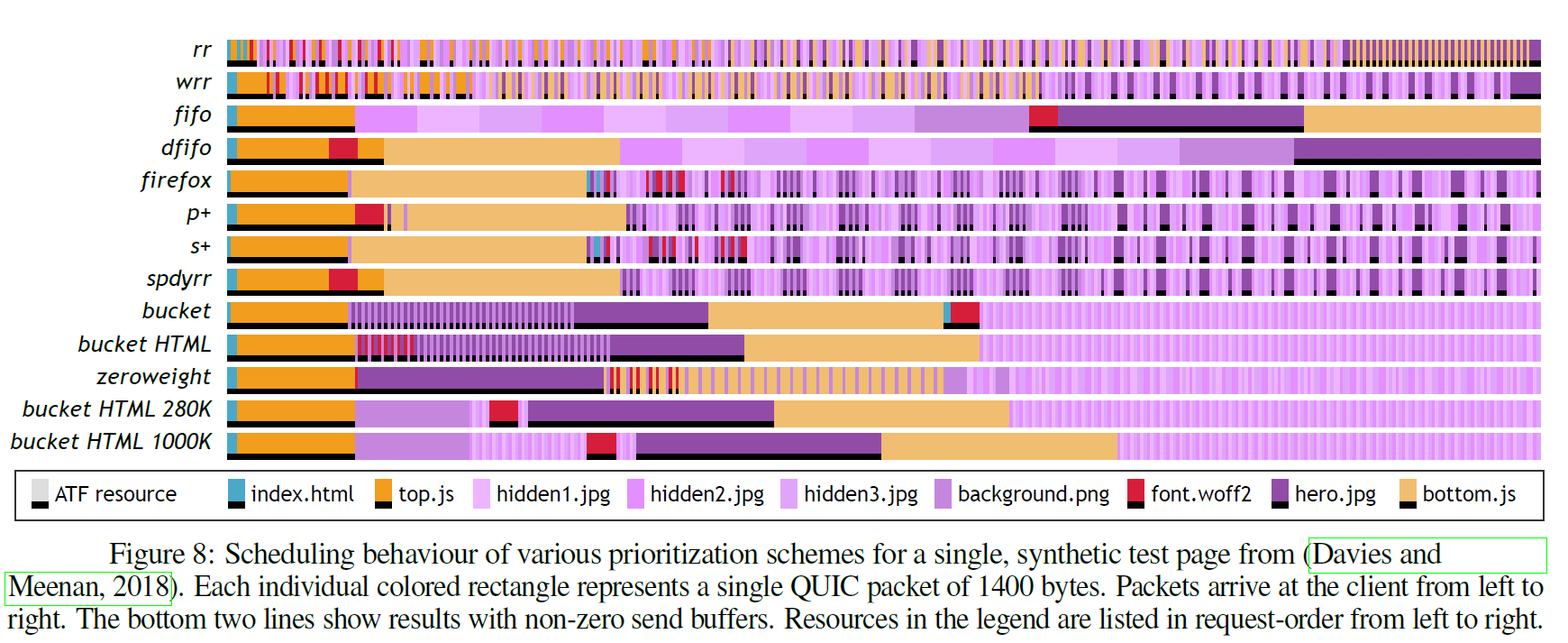
Figure 8. はDaview and Meenan 2018 のテストページの結果です。
グラフの縦軸は、それぞれの優先度制御の方式で、横軸が1パケット毎にどのリソースが受信されたのかを示しています。それぞれ凡例の中で、下が黒く塗られているものがATFリソースです。この中では、index.html、top.js、font.woff2、hero.jpg、bottom.jsがATFのリソースに該当します。
ラウンドロビンの場合、ATFリソースのhero.jpgが最後までダウンロードされていないことが見て取れます。これは、wrr、firefox、p+、s+、spdyrrなどで似た傾向が確認できます。
一方本論文で使用を提案しているbucket、bucketHTML、zeroweightなどはATFリソースがかなり速いタイミングでダウンロードが完了しています。
この例に限らず、ラウンドロビン (rr)が一番悪い結果になるので、そこからのスピードアップで性能を算出しています。例えば優先度制御手法XのBIが1500で、rrのBIが750だと、x2のスピードアップになります。
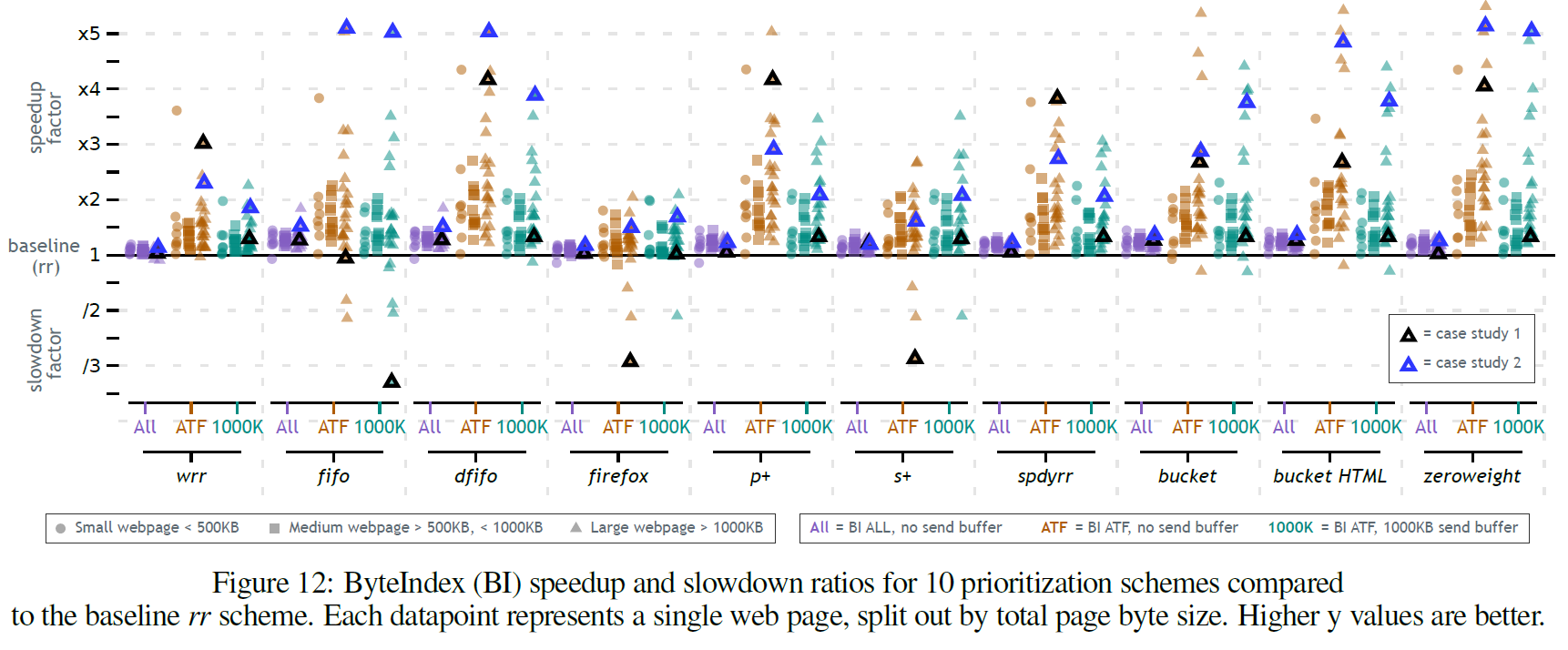
Figure12はベースラインをラウンドロビンにしたときの10個の手法の比較結果です。それぞれ、すべてのリソースをロードしたときのスピードアップ、ATFのスピードアップ、バッファを1000KBにしたときの(おそらく文脈的にはATF)のスピードアップをプロットしています。
このグラフから以下のことが分かります。
- ほとんどが、
rrより速い -
firefox、wrr、s+などを除くと、ほとんどがx3.5~x5のスピードアップを達成している - 500KBより大きく1000KBより小さいページでは全体的にスピードアップの値が低い。500KBより小さいページや1000KBより大きいページのほうが効果が大きい
- すべてのウェブサイトで他の手法より良い結果を出す方法はない
- 1000KBの送信バッファの影響は見えるが、先行研究( Patrick Meenan, 2018) で言われているほど大きくないように見える。
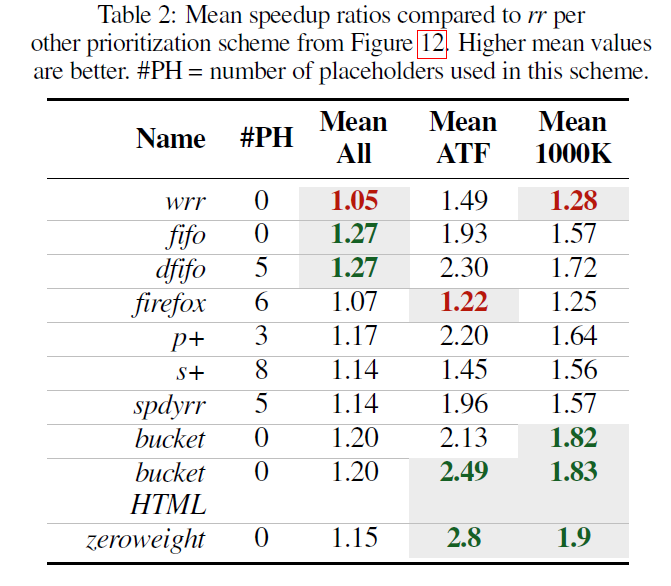
Table2はすべてのテストページの平均の値です。
このテーブルからは、以下のことが読み取れます
- すべてのリソースをロードする場合のスピードアップを見ると、
fifoはrrよりデフォルトの選択肢としてよい - ATFだけを見ると、
firefoxやsafariのwrrはあまりよくない。ブラウザの中ではChromeが一番良い。bucket HTML、zeroweightについでChromeが良いという結果になっている - 送信側のバッファサイズが大きい時は、
bucket HTML、zeroweightが良い。
bucketHTML、zeroweightが良い結果となった理由は、hero imageに高い優先度を割り当てるように設定していることが一部影響していると私は思いました。この結果が、クライアントとサーバの優先度のdirectiveを組みわせることにはメリットがあるという著者の主張につながっていると思います。
送信バッファが大きい時に、スピードアップの値が低下する振る舞いになったのは以下の2つの理由で説明できます。
- 送信バッファが大きい時は、後で見つかった重要なリソースのために優先度を再設定した場合のスケジューリングに影響を与えると考えられる。しかし、使用したデータセットにはそのようなページはあまり多くなかった。
- 送信バッファのサイズが大きくなると、振る舞いが
fifoに近くなる。fifoは全体的に良い結果になるので、送信バッファを多く確保したときも似たような結果になる
PlaceHolderを使っている手法が部分的に良い結果を出していますが、実装の複雑さを鑑みると、bucket HTMLが一番良いと著者は主張しています。ただ、あとから、zeroweight、 spdyrrといった方法を追加するのも簡単で直感的であるとも考えているようです。
QUIC's HOL-blocking resilience
QUICでストリーム間のHOL-Blockingが起こらないことがどう影響するかを確認しています。
セミランダムにジッターを入れることで確認をしています。具体的には4つのパケットのうち一つにジッターを加えます。ジッターを加えたパケットより後の1~3個のパケットはそのまま送信されます。その結果、ジッターを加えられたパケットより先に送信された本来後に送信されるべきパケットは、先に上位レイヤーに渡されます。
これが実際にどのくらいの問題になるかを確認するために、QUICクライアントにHOL-blocking modeを実装して比較しています。

Figure13では、rrとfifoをHOL-blockingがある場合とない場合でそれぞれ4つの組み合わせの結果を比較しています。図は、横軸が時系列、縦軸があるタイミングで上位に渡されるパケットのスタックになっています。
いくつか空白の場所が図に見られます。これはその場所では上位レイヤーにパケットを渡せなかったことを意味します。
rr
rrの場合はストリームが独立していることの利点が見られます。一方、
rrの場合は、最大でも2個のパケットが上位に渡されています。
一方、HOL-blockingを設定している場合は、criticalなリソースがそうでないリソースにブロックされることが起きています。
fifo
fifoの場合は、HoL-blockingありの場合と無しの場合で違いがみられません。
QUICはストリーム間の依存関係は削除していますが、同じストリーム内の依存関係は残っているのが理由です。fifoの場合は常に一つのストリームが処理されます。その結果、ストリーム間のHoL-blockingの設定の有無にかかわらず、fifo送信されている一つのストリーム自身がHoL-blockingされてしまいます。
6. Discussion & Conclusion
シーケンシャルな方法は、ラウンドロビンより優れている。
結果で見てきた通り、シーケンシャルな方法はラウンドロビンを使う方法よりも良い結果になっている。なので、デフォルトのフォールバックを今のrrからfifoに変更したほうがよい。その際に、orphan placeholderを一緒に採用する。これにより、優先度が低いリソースによって優先度が高いリソースの帯域が奪われることを防げます。
パケットロスが多い場合やジッターが大きい場合は調整が必要
パケットロスが多い場合やジッターが大きい環境では、シーケンシャルな方法よりもラウンドロビンの方法の方が並列にリソースを送信しているため、QUICのトランスポートレイヤーのHoL-blockingの影響を取り除けるため良い結果になっています。
ただし、これは仮説なので、実際のロスがあるネットワークで輻輳制御をあわせて使った時の結果を検証する実験は必要になります。
ウェブブラウジングのユースケースで性能を失うことなく、シンプルな優先度制御のフレームワークに移行することが可能である。
bucketHTMLやzeroweightはシンプルで、placeholderを必要とせず、多くのサイトで性能検討の良いベースラインになる。
ただ、結果からわかるようにすべてのサイトで常に速い方法は存在しません。完全に汎用な方法を作るのはほとんど不可能です。そういう背景があるので、自動的に優先度を決定する方法や、'Priority Hint'のように手動でリソースの優先度を決めるような仕組みが検討されています。
しかし、著者は複雑な自動化されたシステムや手動で多くの労力を必要とする方法は、(特に小さい会社で)スケールしないと考えています。
要約すると、それぞれのページでデフォルトのヒューリスティックよりはよい性能を得たいが、高い自動化や手動のコストは支払いたくない、というのが著者の主張になります。
すべてのHTTP/3クライアントは複数の優先度制御の方法を同時に実装する
優先度制御の方法を複数実装すると、開発者は自分たちのページで性能が出せる優先度制御の方法を自動で簡単に実験して調べることができます。そしてクライアントには接続時にその方法を通知することが可能になります。
この方法には以下のような利点があります
- より進んだシステムよりは劣るかもしれないが、汎用のヒューリスティックよりも良く機能する
- Priority Hintのように手動でやる方法に対して補完的です
- クライアントに送る方法のリストを決めるのに、ネットワークの知識を取り込むことができます。例えば、例えばCDNはネットワークのタイプを知っていて、ロス、レイテンシなどのパラメータも推測できます。
-
bucket HTMLのようなより良いクライアントの優先度制御の方法と組み合わせることで、サーバ側で適切な方式を記述していない場合でも性能が保証されます。
クライアントに広い方式の実装を求めると、dependency treeのような柔軟なシステムの下でのみ実現できる
この主張は良くわかりませんでした。クライアントにいくつかの方式を実装すること=サーバとクライアントの組み合わせが前提になっています。なので、クライアントとサーバがお互いのメタデータを交換する方法を検討する必要があるというのが主張したかったことだと思います。
ここでいうメタデータは、どの優先度制御の方式を使うかに限らず、どのリソースがクリティカル、そのリソースがレンダー/パースをブロッキングするのか、そのリソースはincrementallyに処理できるのか、といったものも含まれます。
長い目で見れば、dependency treeのような複雑な方法には価値がある。すでにHTTP/2のクライアントはサポートしている。クライアントが複数実装する方式はHTTP/2でも実装したほうがよいと著者は考えているようです。