最近ではAlphaGoが世間を騒がせていますが、今度はGoogleがロボット14台を並べてハンドで物をつかむのを800,000回の学習データを使って学習させた研究が発表されました。

http://googleresearch.blogspot.jp/2016/03/deep-learning-for-robots-learning-from.html
http://gigazine.net/news/20160310-google-deep-learning-robot/
論文は以下にあります。
http://arxiv.org/pdf/1603.02199v1.pdf
驚いたのは、ただ色んな物をつかむだけでなく、散らかった環境から邪魔なものはどけつつ、物をつかむのを学習によって習得したそうです。さらに、**ロボットには個体差を持たせていて、カメラ位置、ハンドの形状が異なるそうです。**以下がその驚きの動画です。

今回はこの論文を読んだ内容をまとめてみたいと思います。
CNNによる把持成功予測
次のような構成のCNNを学習します。
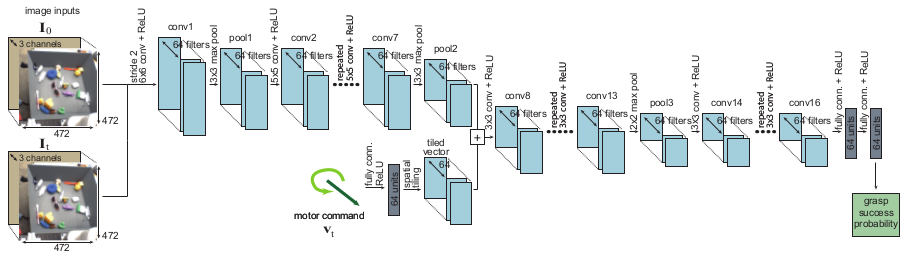
- 入力
- 初期画像 $I_0$ (サイズ472×472)
- 現在画像 $I_t$ (サイズ472×472)
- $v_t = 最終ハンド位置 - 現在ハンド位置$
- 出力
- 把持成功確率
画像はロボットハンドの上部に設置された単眼カメラから取得されます。一連の把持シーケンスが$T$ステップで行われるとしたときに、$i$番目の把持シーケンスにおいて、$(I_t^i, p_T^i - p_t^i, l^i)$を学習データに用いるようにします。ここで、$p_T^i$は最終ハンド位置、$p_t^i$は$t$ステップ目でのハンド位置、$l^i$は$i$番目の試行における把持成功かどうかのラベルです。
CNNからモータコマンドの作成
現在画像$I_t$から最適なモータコマンド$v_t^*$を求めます。
方法としては、上で説明したCNNを使って、現在画像を入力した際に出力の把持成功確率が最大になるように入力$v_t$を求めます。
\newcommand{\argmax}{\mathop{\rm argmax}\limits}
v_t^* = \argmax_{v_t} (g(I_t, v_t))
最適化の手法としてはCEM(Cross Entropy Method)という手法が用いられています。
この$v_t^*$をそのまま使うのではなく、アームを動かさないとき(その位置で把持する)の確率$g(I_t, \emptyset)$との比を計算して、その値に応じてモータコマンドを決定しているようです。
データ収集
まずランダムなモータコマンドから開始して、ステップ数$T=3$でデータを集めます。全データ中半分はランダムモータコマンドによって得られたデータを用いて、もう半分はそれまでとられたデータが適用されたネットワークから得られたデータを用います。ネットワークは4回更新し、把持シーケンスのステップ数$T$を3〜10まで増加させています。
結果
以下の4つの方法を比較して本手法の優位性を示しています。
- ランダムに動作を行った場合
- ハンドチューニング動作
- オープンループ(画像を最初だけ用いて、その中で把持確率が高い物体を把持する動作)
- 提案手法(毎タイムステップでモータコマンド求めるサーボループ)
提案手法はランダムやハンドチューンよりもちろん良い結果なのですが、オープンループと比較しても半分くらいの失敗率になってました。
まとめ
このタスクでは比較的閉じられた世界での学習データ収集が可能ですが、今後は様々なタスクを行っていくために実世界でのロボットによるデータ収集方法を考えていくそうです。
感想
いよいよ実ロボットでもDeep Learningが使われ始め、成果が出てきているのを見ると、SFに出るようなAIも夢では無い気がしてワクワクしてきますね。まだまだ今後も発展していく分野だと思うので、自分も勉強していきたいと思いました。