昨今クラウド環境の充実や API を通して様々なサービスを利用できるようになり、高度なシステムを手軽に構築できるようになった反面、システムの構成が複雑になり様々な障害を引き起こす要因になっています。急なアクセスの集中、ネットワーク障害、ハードウェア障害など、我々が運用するシステムは障害に見舞われる危険に常に晒されています。
このような障害に対処するための設計パターンを @kawasima さんが下記の記事にまとめてくださっています。
このパターンの一部を実現する手段として、Akka というツールキットが利用できます。この記事では、安定性のパターンを引用しながら、Akka がそのパターンの実現にどう役立つのかということをご紹介したいと思います。
そもそも Akka とは何でしょうか?
Akka とは何か?
 https://akka.io/
https://akka.io/
Akka とは並行処理や分散処理行うシステムの構築をサポートするツールキットです。並行・分散処理に関わる様々なモジュールが提供されており、それぞれを取捨選択して部分的にプロジェクトで利用できるようになっています。Java と Scala の API を提供しています。
ChatWork さんのメッセージングシステム や負荷テストツールの Gatling などで利用されています。
複雑で不安定になりがちな並行処理や分散処理を安定させるための仕組みが多く備わっています。
ここから、安定性のパターンの「タイムタウト」、「サーキットブレーカー」、「Let it Crash」の3つのパターンの実現に Akka がどう役立つのか説明していきます。
なお、各パターンのサンプル実装は実際に動かしてみることができます。詳細は以下のリポジトリを参照してください。
パターン1: タイムアウト
スレッドをブロックする処理は、必ずタイムアウトの設定をしましょうというパターンです。
[安定性のパターン大全 (とその実装) - Qiita]
(https://qiita.com/kawasima/items/2336a310113b0486ff67#%E3%82%BF%E3%82%A4%E3%83%A0%E3%82%A2%E3%82%A6%E3%83%88-timeout)
Future のタイムアウト
たとえ、外部のシステムが提供するAPIを利用していて、そのシステムが障害で応答を返さなくなっていたとしても一定時間内に何らかのレスポンスを返すことが望ましいです。でないと、ユーザーは何が起きているのかわからずストレスが溜まります。レスポンスを返す先が他のシステムなら、そのシステムのスレッドを長時間ブロックし新たな障害を誘発してしまうかもしれません。
しかし、Scala で非同期処理を行うときに用いる Future にはタイムアウトを実現する機能がありません。そのため、基本的にはその Future の値を提供するライブラリ(例えば HTTP クライアント)などのタイムアウトの設定を利用するしかありません。では、そのような設定が存在しないライブラリから返ってくる Future にタイムアウトを適用したい場合はどうすれば良いでしょうか?
Akka の after を利用すると Future のタイムアウトを実現できます。
import akka.pattern.after
val timeout: Future[String] = after(200.millis, using = system.scheduler) {
Future.failed(new TimeoutException())
}
val future: Future[String] = Future {
Thread.sleep(1000)
"hello"
}
val result: Future[String] =
Future.firstCompletedOf(Seq(future, timeout))
// ⇒ Future(Failure(java.util.concurrent.TimeoutException))
after によって指定した時間で結果を返す Future を作ることができます(ここでは Failure(TimeoutException))。
そして、複数の Future のうち、最初に終わった Future の結果を返す Future.firstCompletedOf を用いることで、タイムアウトが先に返された場合は Failure(TimeoutExeption)、処理の結果が先に返された場合は Success("hello") を返す Future を作ることができます(result)。
タイムタウトが設定できないライブラリに遭遇しても Akka があれば安心です。
パターン2: サーキットブレーカー
リモート呼び出しのときに、連続してエラーが発生したり、スローレスポンスが頻発する場合、呼び出し自体を止めるというパターンです。
[安定性のパターン大全 (とその実装) - Qiita]
(https://qiita.com/kawasima/items/2336a310113b0486ff67#%E3%82%B5%E3%83%BC%E3%82%AD%E3%83%83%E3%83%88%E3%83%96%E3%83%AC%E3%82%A4%E3%82%AB%E3%83%BC-circuit-breaker)
障害が起きているときにタイムアウトして返ってくる応答は通常時よりも遅くなるため、APIを呼び出した側のスレッドがブロックされる時間は通常よりも長くなります。障害が長引くとリソースを食いつぶして障害が連鎖してしまうため、サーキットブレーカーを使って障害時でも早く応答を返すことで障害が連鎖するのを防ぎます。
サーキットブレーカーの詳しい振る舞いについては、下記のスライドで解説しています。

Akka ではサーキットブレーカーが標準で提供されています。
import akka.pattern.CircuitBreaker
implicit val executionContext = system.dispatcher
lazy val breaker =
new CircuitBreaker(
system.scheduler, // ActorSystem のスケジューラ
maxFailures = 5, // エラーカウントがこの数字になるとリクエストを遮断
callTimeout = 10.seconds, // リクエストをタイムアウトさせる時間
resetTimeout = 3.seconds // リクエストの遮断を一時的に取り止めるまでの時間
)
// 外部サービスに対してリクエスト
def fetchUserList(): Future[HttpResponse] =
Http().singleRequest(HttpRequest(uri = "http://localhost:8080/users"))
val response: Future[HttpResponse] =
breaker.withCircuitBreaker(fetchUserList)
タイムアウトした場合など、fetchUserList のレスポンス(Future[HttpResponse]) を得るのに失敗した場合にサーキットブレーカーのエラーカウントが増えていきます。エラーカウントが maxFailures に達すると即座にエラーが返るようになります。
レスポンスは返ってきたが、そのレスポンスの内容によってはエラーとみなしたいケースもあるでしょう。その場合は、Future の結果の内容を検証する関数を定義し、 withCircuitBreaker に渡します(下記例では httpErrorResponseAsFailure)。その関数が true を返すと処理が失敗したとみなされます。
// 外部サービスが返した結果を検証する関数
val httpErrorResponseAsFailure: Try[HttpResponse] => Boolean = {
// HTTPのステータスコードが OK 以外の場合はエラーとみなす
case Success(response) => response.status != StatusCodes.OK
case Failure(_) => true
}
val response: Future[HttpResponse] =
breaker.withCircuitBreaker(callService, httpErrorResponseAsFailure)
リトライを頻繁に行って障害が起きたシステムやネットワークに負荷をかけないようにしたい場合は ExponentialBackoff(リトライの間隔を指数関数的に増やす)のオプションが利用できます。ExponentialBackoff のオプションを指定すると、再試行の度に再試行の間隔 resetTimeout が下記の計算式で増えていきます。ただし、maxResetTimeout を超えることはありません。
resetTimeout = resetTimeout × exponentialBackoffFactor
lazy val breaker =
new CircuitBreaker(
system.scheduler,
maxFailures = 5,
callTimeout = 10.seconds,
resetTimeout = 3.seconds,
maxResetTimeout = 30.seconds, // resetTimeout の上限
exponentialBackoffFactor = 1.5 // 再試行の度に resetTimeout の時間を増やす倍数
)
Akka では標準でサーキットブレーカーが提供されているため、手軽に利用できます。外部のAPIを呼び出したりする際は、サーキットブレーカーを使って障害時もすぐに応答を返すようにしましょう。
パターン3: Let it Crash
部分的に再起動・再生成してクリーンな状態にした方が、システム全体に影響を与えず、元の定常状態に戻れるのであればそうしよう、というパターンです。
安定性のパターン大全 (とその実装) - Qiita
Akka のアクター(Actor)モジュールはこのパターンに基いて設計されています。Akka において最も重要で、コアとなるモジュールです。Release It! でも、Let it Crash を実現する方法の1つとして Akka が紹介されていました。
このパターンを用いることによって、
- 障害からの回復がシンプルに行える
- 障害のハンドリングを含めたカプセル化により保守性が高くなる
という利点があります。
障害からの回復がシンプルに行える
データベースにアクセスしてユーザーの登録と参照を行うアクターを考えます。
class UserRegistryActor extends Actor with ActorLogging {
import UserRegistryActor._
val db = Database.forURL("jdbc:h2:tcp://localhost/./sample")
/** DBセッション */
implicit lazy val session = db.createSession()
// ...
/** メッセージを受信した際の振る舞いを定義するメソッド */
override def receive: Receive = {
case GetUsers =>
// SELECT * FROM users;
sender() ! users.list
case CreateUser(user) =>
// INSERT INTO users (name) VALUE ('${user.name}')
users.insert(user)
sender() ! ActionPerformed(s"User ${user.name} created.")
// ...
この UserRegistryActor というアクターはプロパティとしてDBセッションを1つ持ちます。このセッションを用いて、ORマッパーでDBにクエリを投げることでユーザーの登録や参照などを行います。
receive メソッドはアクター独特のメソッドで、ここに GetUsers などのメッセージを受け取った時の振る舞いを定義します。
通常のクラスで同様の機能を実装したとすると下記のようになるでしょうか。
class UserRegistry {
val db = Database.forURL("jdbc:h2:tcp://localhost/./sample")
/** DBセッション */
implicit lazy val session = db.createSession()
def getUsers(): Seq[User] = {
// SELECT * FROM users;
users.list
}
def createUser(user: User): ActionPerformed = {
// INSERT INTO users (name) VALUE ('${user.name}')
users.insert(user)
ActionPerformed(s"User ${user.name} created.")
}
// ...
UserRegistryActor に対してユーザーの一覧を問い合わせる処理は下記のように書きます。
val system: ActorSystem = ActorSystem()
// アクターを生成
val userRegistryActor: ActorRef =
system.actorOf(UserRegistrySupervisor.props, UserRegistrySupervisor.name)
// ? でメッセージを受け取る際のタイムアウト
implicit val timeout = Timeout(1000.milliseconds)
// ユーザーの一覧を問い合わせ
userRegistryActor ? GetUsers // => Future[Seq[User])
? でメッセージを送信すると、その応答としてユーザーの一覧 Future[Seq[User]] 1 が得られます。
ユーザーの一覧の問い合わせは非同期で行われるため、タイムアウトを設定する必要があります。Akka では Timeout を使ってそのタイムアウトを表現します。
さて、いきなりですがここでネットワークに障害が発生し、アプリケーションとDBとの接続が失われてしまうとどうなるでしょうか?もちろん、DBにクエリを投げる際に例外が発生します。
/** メッセージを受信した際の振る舞いを定義するメソッド */
override def receive: Receive = {
case GetUsers =>
// SELECT * FROM users;
sender() ! users.list // JdbcSQLException!!
// ...
このように例外が発生すると、このアクターは再起動します。もう少し具体的に言うと、このアクターのインスタンスが破棄され、新しいインスタンスに置き換えられます。このように、何か問題が起きたときにコンポーネントを新しいものに取り替えるパターンを Let It Crash(クラッシュするならさせておけ)と言います。
インスタンスが破棄されるとメッセージの送り先がわからなくなるのでは?と不安になりますが、安心してください。Akkaでは ActorRef というオブジェクトを介して実際のアクターにメッセージを送信します。アクターが作り替えられると ActorRef が指すアクターのインスタンスも自動的に切り替えられるため、メッセージを送信する側は何も気にする必要がありません。
val system: ActorSystem = ActorSystem()
val userRegistryActor: ActorRef =
system.actorOf(UserRegistrySupervisor.props, UserRegistrySupervisor.name)
implicit val timeout = Timeout(1000.milliseconds)
userRegistryActor ? GetUsers // => Future(Success(Seq(user1, user2)))
// ネットワークに障害発生!!(DBとの接続が切断)
userRegistryActor ? GetUsers // => Future(Failure(AskTimeoutException))
// 例外によりアクターが再起動
// ネットワークが回復
userRegistryActor ? GetUsers // => Future(Success(Seq(user1, user2)))
2番目の Getusers の問い合わせの直前でネットワークに障害が起きると、アクターの内部で例外が発生しアクターが再起動します(ここでは処理が中断するためアクターが応答を返せずタイムタウトになります)。しかし、メッセージを送る側は同じ ActorRef を使って新しいアクターにメッセージを送ることができます。再起動した時点でDBとの接続を新たに開始できる状態になっているため、ネットワークが回復していたら再びユーザーの一覧が再び取得できるようになっているでしょう。つまり、メッセージを送る側は稀に処理がタイムタウトになることさえ気にしていれば良いのです。
- アクターが自動で再起動し状態がリセットされる
- メッセージを送る側はアクターが再起動することを気にしなくてよい
という仕組みによって、障害からの回復が容易に行えるようになっています。
アクターの状態がアプリケーションにとって重要なものであれば、データベースに状態を2永続化する仕組みが用意されているため、それを利用します。自動で状態が復元されるため、メッセージを送る側はやはりアクターが再起動することを気にしなくて良いのです。
障害のハンドリングを含めたカプセル化により保守性が高くなる
ところで、アクターで起きた例外(障害)は誰がハンドリングするのでしょうか?メソッド呼び出しのプログラミングスタイルでは、コールスタックのどこかで try-catch を使って例外がハンドリングされます。
try {
userRegistry.getUsers()
} catch {
case e: JdbcSQLException =>
// ...
}
アクターの場合は「親アクター」という存在によって例外がハンドリングされます。親アクターはスーパーバイザー(Supervisor)とも呼ばれます。ActorSystem#actorOf を用いるとデフォルトの親アクターが居るため、その配下にアクターが生成されます。
val system: ActorSystem = ActorSystem()
val userRegistryActor: ActorRef =
system.actorOf(UserRegistrySupervisor.props, UserRegistrySupervisor.name)
// ↑ デフォルトの親アクターの配下にアクターが生成される
システム全体でアクターの親子関係を俯瞰すると、まるで会社組織のようにツリー構造になります。
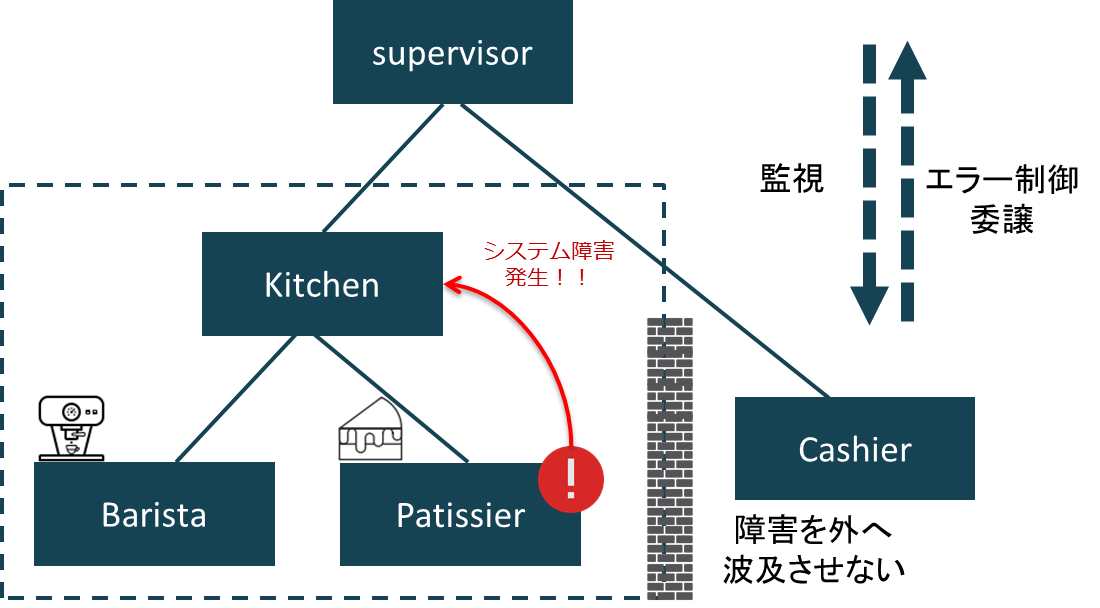
リアクティブシステムを実現するツールキットAkka その2 | Think IT(シンクイット)
例外のハンドリング方法は親アクターが決定します。デフォルトではほとんどの例外で子アクターを再起動するような戦略になっています。もちろん、独自に親アクターを作り、この戦略を決めることもできます。
class UserRegistrySupervisor extends Actor with ActorLogging {
override def supervisorStrategy: SupervisorStrategy =
OneForOneStrategy() {
case e: JdbcSQLException if e.getErrorCode == TABLE_OR_VIEW_NOT_FOUND_1 =>
log.error("データベースのデータが壊れています!!!")
Stop
case e: JdbcSQLException if e.getErrorCode == CONNECTION_BROKEN_1 =>
log.warning("データベースとの接続が切断されました")
Restart
case _: Exception => Escalate
}
// ...
テーブルが見つけられなくなってしまった(TABLE_OR_VIEW_NOT_FOUND_1)場合はアプリケーションで対処しようが無いのでアクターを無期限に停止(Stop)する。DBとの接続が切れた(CONNECTION_BROKEN_1)場合は再起動してネットワークの回復を待つ(Restart)というふうに例外の種類に基いて対処方法が決められます3。このように、アクターを用いると例外のハンドリングはメッセージを送る側ではなく、送った先で行われます。
メッセージを送る側は障害に対処する必要がないため、DBアクセスに関する事柄は障害に対する対処も含めてメッセージを送ったアクター側にカプセル化できます。障害のハンドリングを行うコードがあちこちに散らばらなくなるため、コードの保守性が高くなります。
このように、Akka のアクターモジュールを用いることで、障害に見舞われても安全に回復できるシステムを保守性を保ちながら構築できます。
まとめ
安定性のパターン大全の一部を Akka で実現する方法をご紹介しました。
Akka にはこの他にも、サーバーが過負荷にならないように背圧(Back Pressure)をサポートした Akka Stream というストリーム処理のモジュールや、ステートフルなアプリケーションであっても複数のサーバーに分散して安定性を保つことができるクラスタリングのモジュールを提供しています。
このように、Akka は多くの機能を提供しているためこの記事で紹介しきることはできませんが、Akka の機能を基本から網羅的に学ぶことができる本が出版されました。全ての解説にサンプルコードが付いているため、実際にコードを触りながら学ぶことができます。ぜひ、手にとって読んでみてください!

Akka実践バイブル
アクターモデルによる並行・分散システムの実現
参考資料
- 安定性のパターン大全 (とその実装) - Qiita
- Release It! Second Edition: Design and Deploy Production-Ready Software by Michael Nygard | The Pragmatic Bookshelf
- Documentation | Akka
- Akka実践バイブル アクターモデルによる並行・分散システムの実現