はじめに
これは,NTTコミュニケーションズ Advent Calendar 2018 2日目の記事です.関連記事は目次にまとめられています.(更新したら12/3になってました...)
⚠ 魅力的な飯テロ画像をご用意し,圧倒的な飯テロを狙った記事となっていますので,夜中に見る場合はご注意ください.
おまえだれ?!
普段の業務では,マルチモーダル深層学習や機械学習分析ツール開発などをメイン業務としていて,趣味はプロテインです.
学生時代,学部までは画像認識(モバイル+深層学習)をテーマに研究していまして,修士からは画像生成・画像変換を主に研究していました.**Neural Style TransferとかGenerative Adversarial Networks**の論文が出始めた頃ですね.大学院を卒業してからは,中々,GAN分野の動向を追っていないのですが,まだ流行ってたりするのかな?
(the-gan-zooに主要なGANに関する論文がまとめられています.自分が追っていた頃は300本くらいでしたが,2018/9時点で500超えてますね…恐ろしい...)
なにを書くの?
さて,久しぶりのQiitaで何を書こうかな?と色々と考えましたが,業務に関することだと色々と悩まないといけない事が多そうなヨカーンがぷんぷんしたので,Chainer Meetup #07 ~Chainer 3歳記念イベント~ (修士で行った研究内容)でLTした内容について書こうと思います.
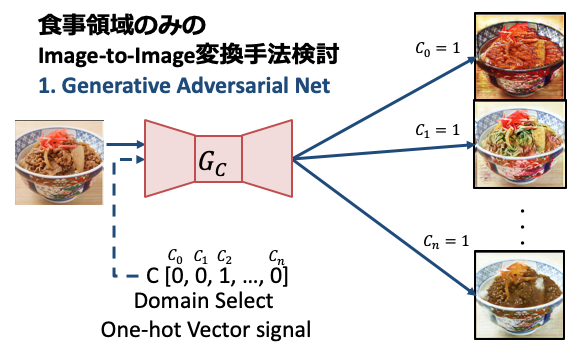
今回の記事で紹介することは以下の画像の通り.
**食事画像を入力として,その食事領域のみを別のカテゴリに上手く変換できないか?**です.
(@_Ryobotさんの論文紹介で知りましためんへらちゃんはフリーです!いつもありがとうございます.)

なんでこの記事書こうと思ったの?
ディープラーニングでラーメン二郎(全店舗)を識別してみたを見て,ラーメン二郎(全店舗)識別があるなら, ラーメン二郎変換 があっても許されるかと思いまして・・・


3 4行まとめ
- 深層学習を用いた食事画像を対象としたマルチドメイン変換
- コードと学習済みモデルとplaybook
- 変換結果と動画例
- 応用例1: メシマズ料理をあっという間に豪華な食事へ
やりたいこと
多様性が考慮される食事画像に対して生成モデルであるGANの手法を用いて,食事画像を任意の食事カテゴリに高いクオリティで変換することを目的とします.通常,GANの学習には顔画像や数字文字画像,最近では,ファッション画像などが用いられるのが通例ではありますが,本記事では,食事画像を変換対象とすることが新しいです.
手法
本記事で用いるStarGANの解説は以下の記事でも述べられていますので,ココでは簡単に関連研究についてまとめましょう.本記事で登場するGANは, pix2pix, CycleGAN, ACGAN, StarGAN の4種類(通称名を用います.)ですが, pix2pix -> CycleGAN + ACGAN -> StarGAN の流れで調べていくとスムーズに理解できます.
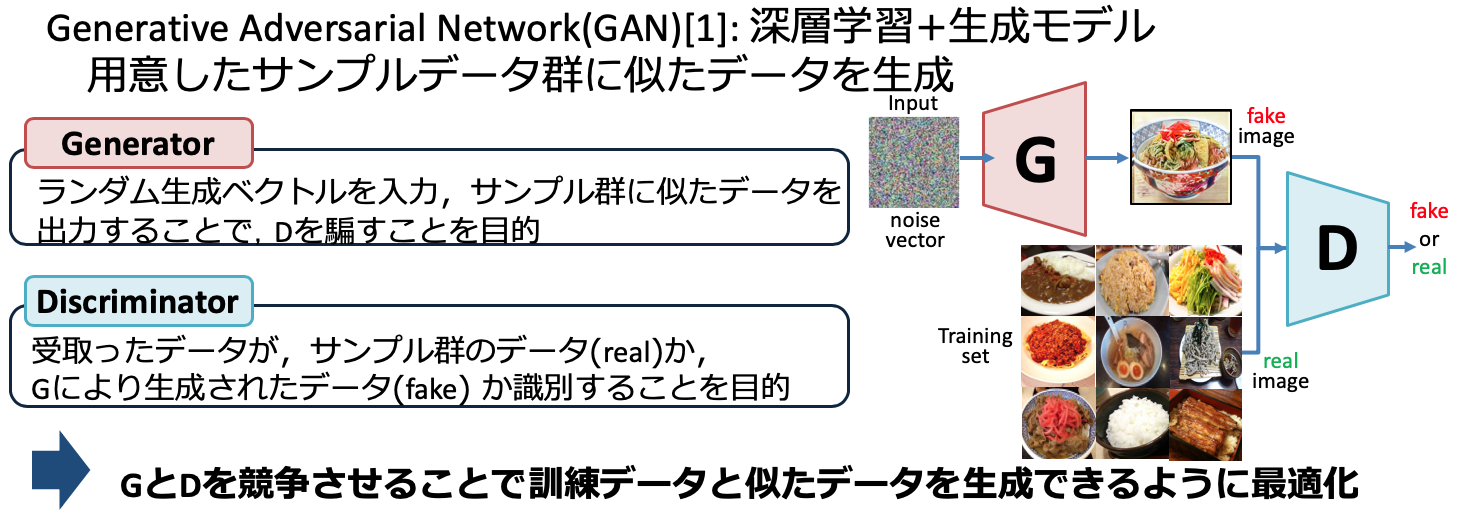
GAN
GANは一様分布や正規分布などからノイズベクトル $z$ をサンプリングするため,生成される画像のコントロールをすることができません.そこで,GANの構造に条件付き信号conditional vectorを付与することで,条件付き確立分布を学習するモデルに拡張したものがconditional GAN(cGAN)と呼ばれるものです. 一方で,cGANには入力画像を潜在表現に落とし込む機構(Encoder)が存在しないため,画像変換のようなタスクは行うことができません.
pix2pix
pix2pixはAdversarial LossとConvDeconvNetを組合せることで,画像のペア集合間の変換方法を学習することが可能となり,線画彩色や白黒画像のカラー化などの変換を学習させることが可能です.

pix2pixや後述するCycleGANと上記のconditional GANとで異なる点は,画像 $x$ をGeneratorの入力とする点が大きく異なる部分にあります.入力に用いていた乱数 $z$ は直接サンプリングする代わりにGeneratorの複数の層にDropoutという形でノイズを加えるように代替されています.pix2pixでは,cGANの損失関数に加えて,より本物らしい画像を生成するために,L1正則化項の追加とDiscriminatorのベース構造で提案されたPatchGANを組合せたものがpix2pixの損失関数として定義されています.入力には変換前と変換後の画像のペアを必要とし,(変換元画像,変換先画像) or (変換元画像,Generator が生成した画像) のいずれのペアであるかをDiscriminator に判断させるように学習させます.
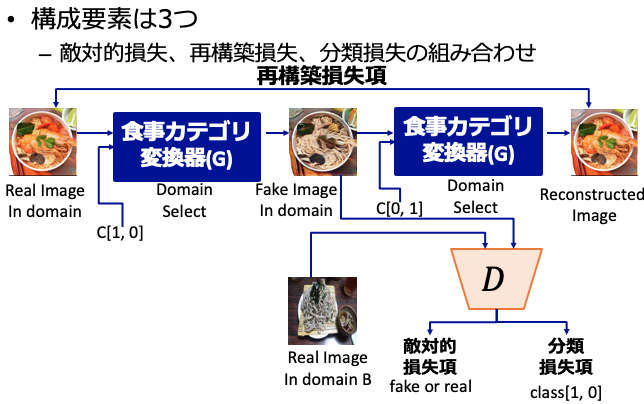
StarGAN
本手法は敵対的損失項(Adversarial Loss)に2つの損失項を組合せることで,共通する構造を保ちつつ,複数のドメインへと写像するGeneratorの学習を実現したものとなっています.
CycleGAN
 pix2pixでは,変換前と変換後の画像の1対1ペアを必要とする制限がありましたが,CycleGANではドメイン間の写像を学習できるように拡張することで,1対1に対応せずとも学習が行えるのが特徴です.画像集合を表すドメイン$X$とドメイン$Y$,写像$G: X\rightarrow Y$,その逆写像$F: Y\rightarrow X$を定義します.また,入力が$G$によって生成された偽物の$X$か元の$X$のデータかを判別する$D_{Y}$,入力が$Y$によって生成された偽物の$Y$か元の$Y$のデータかを判別する$D_{X}$をそれぞれ定義しましょう.CycleGANが提案している新たなロスは,再構築損失項(Cycle Consistency Loss)と呼ばれるもので,ドメイン$X$に属する$x$から生成された$\hat{Y}$を再度,ドメイン$X$に属する$\hat{x}$に戻しても元のドメイン$X$に一致するように制約をかけるものです.
この再構築損失項(Cycle Consistency Loss)を小さくすることは,$G(F(x))$により変換した結果がそれぞれ元のデータを再構築できるだけの情報を保持することを意味します.よって,学習に成功した場合は,$G(F(x))$とした場合,「ドメイン$X$とドメイン$Y$に共通する構造を保ったまま,一方のドメインに属するデータをもう一方のドメインのデータに変換する」写像関数が得られることになります.
pix2pixでは,変換前と変換後の画像の1対1ペアを必要とする制限がありましたが,CycleGANではドメイン間の写像を学習できるように拡張することで,1対1に対応せずとも学習が行えるのが特徴です.画像集合を表すドメイン$X$とドメイン$Y$,写像$G: X\rightarrow Y$,その逆写像$F: Y\rightarrow X$を定義します.また,入力が$G$によって生成された偽物の$X$か元の$X$のデータかを判別する$D_{Y}$,入力が$Y$によって生成された偽物の$Y$か元の$Y$のデータかを判別する$D_{X}$をそれぞれ定義しましょう.CycleGANが提案している新たなロスは,再構築損失項(Cycle Consistency Loss)と呼ばれるもので,ドメイン$X$に属する$x$から生成された$\hat{Y}$を再度,ドメイン$X$に属する$\hat{x}$に戻しても元のドメイン$X$に一致するように制約をかけるものです.
この再構築損失項(Cycle Consistency Loss)を小さくすることは,$G(F(x))$により変換した結果がそれぞれ元のデータを再構築できるだけの情報を保持することを意味します.よって,学習に成功した場合は,$G(F(x))$とした場合,「ドメイン$X$とドメイン$Y$に共通する構造を保ったまま,一方のドメインに属するデータをもう一方のドメインのデータに変換する」写像関数が得られることになります.
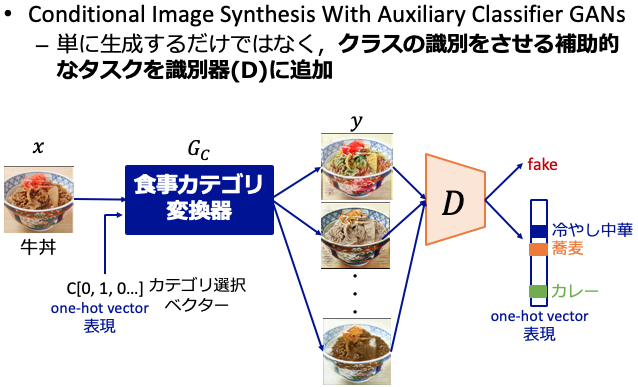
ACGAN
 複数のドメイン$X, Y, Z$を考えたとき,DiscriminatorはGeneratorから生成される偽物の画像が$X, Y, Z$のどのドメインに属するかの判断ができません.そこで,ACGANで提案されている分類損失項を用いることで,どのドメインに属するかも正しく判断できるように学習させることが可能となります.また,Generatorは単にDiscriminatorを欺くように画像を生成するだけでなく,Discriminatorの分類エラーを最小限に抑えるように偽物のサンプルを生成できるようになります.つまり,各ドメインのサンプルを生成できるように最適化されることを意味します.
複数のドメイン$X, Y, Z$を考えたとき,DiscriminatorはGeneratorから生成される偽物の画像が$X, Y, Z$のどのドメインに属するかの判断ができません.そこで,ACGANで提案されている分類損失項を用いることで,どのドメインに属するかも正しく判断できるように学習させることが可能となります.また,Generatorは単にDiscriminatorを欺くように画像を生成するだけでなく,Discriminatorの分類エラーを最小限に抑えるように偽物のサンプルを生成できるようになります.つまり,各ドメインのサンプルを生成できるように最適化されることを意味します.
損失関数
最終的な損失関数は,$L_{adv}$を学習の安定化のためにWGAN-GPで提案された損失項$L_{D}^{WGAN-GP}, L_{G}^{WGAN-GP}$に置き換えた3つの損失項の組合せで構成され,$L_{ccl}$のバイアス値$\lambda_{ccl}$と$L_{acl}^{real}, L_{acl}^{fake}$及び$L_{acl}$のバイアス値$\lambda_{acl}$を追加した式からなる損失関数が用いられます.

データセット
AIをDeep Learningで学習させるにはデータが重要ですね.本項では学習に用いたデータセットについてまとめます.
データ収集
StarGANはCycleGANとACGANの組み合わせで成り立っていることは,上記のリンクや画像を見るとわかると思います.つまり,
CycleGANで提案されている再構築損失項(Cycle Consistency Loss)が存在することで,「集合$X, Y$に共通する構造を保って」変換することが可能です.そのため,学習データに「共通する構造」がある方が変換が上手くいくと推測されますね.

よって今回は,「丼」という制約を設けて,「丼」の構造をもつ10個のカテゴリを選出してみました.その10カテゴリについて,高品質な食事画像の選別のために,Twitterからクロールした画像データの中から,食事画像を認識するシステムを用いて,各カテゴリ毎に認識精度が高い順にリランキングした結果を学習データとしました.10カテゴリで23万枚の画像を学習に用います.

なんで23万枚のデータセットにしたの?
世界中のセレブな人たちの顔を集めた顔画像データセットとして有名なLarge-scale CelebFaces Attributes(CelebA) Datasetの枚数が約23万枚ということに倣っています.

ラーメン画像は多種多様
この中で「ラーメン」のカテゴリに至ってはその種類の多様性が他のカテゴリと比べて高かったため,下図のような処理を行いました.なんでこんな事するかというと,例えば,「二郎系のラーメン」は基本的に「丼」からはみ出るほどの具材が乗っているため,他のラーメンと比べても差が大きかったりします.つまり,「共通する構造」が同カテゴリであるが,差が大きくなってしまい,学習が難しくなる恐れがあるからです.では,どうやって処理を行えばよいでしょうか?簡単にやるにはk-menasを使ってクラスタリングしてやれば良さそうです.
8万枚の「ラーメン」画像に対して,ImageNetで学習済みのVGG16を特徴抽出器として用い,224x224x3(150,528次元)をfc6層(4,096次元)まで特徴量を圧縮してk-meansによりk個のクラスタ(今回は,k=8に設定した)に分割を行います.想定していた通り,「二郎系ラーメン」が大部分を占めるクラスタを得られたため,そのクラスタを除外した画像を「ラーメン」カテゴリの画像とします.
(つまり,二郎系のラーメンはラーメンカテゴリには含まれないことになります.面白いですね!w)

食事カテゴリ変換器部分のネットワーク構成
食事カテゴリ変換器のGenerator部分はPerceptual Losses for Real-Time Style Transfer and Super-Resolution[Johnson+ ECCV-16]で提案されたConvDeconvNetの中間層にResidual Blockを何層も積層するFastStyleNetの構造を用いて256x256の画像にリサイズしたものを学習に用います.
また,DiscriminatorにはPatchGANを採用し,重みの更新頻度はDiscriminatorを5回更新した後にGeneratorを1回更新するよう学習します.尚,学習環境はNVIDIA Quadro P6000を利用しバッチサイズ32,最適化手法にはAdamを用いて20epoch繰り返しました.テスト時は512x512の画像を生成するようにして,高品質の画像生成を試みます.
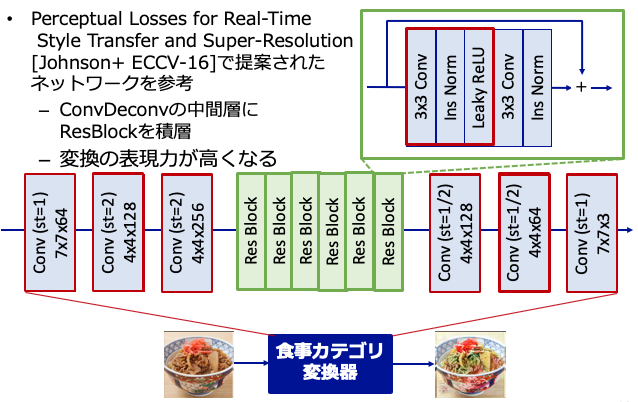
また,食事カテゴリ変換器のネットワークの各レイヤー詳細は下表のとおりです.


結果
実際の食事画像への適用例
以下に変換例を示します.他の変換例はコチラに載せてあります.左上の画像(Original Image)を様々な食事カテゴリに変換させてみました.


また,今年のECCV Workshopの1つにComputer Vision for Fashion, Art and Designといういい感じのワークショップがあったので,そのArtworks部門に投稿したりもしています.AcceptされたArt一覧はこちら.自分が投稿したArt作品はこちら.
アニメ映像中に登場する食事画像への適用例
また,下の画像は**ラーメン大好き小泉さん**のアニメ映像中に登場するラーメンの画像を使って,画像変換したものになっています.画像の最左列の1列がOriginal Imageで,その横に変換した結果の画像が並んでいます.実画像で学習してあるので,アニメ画像がより現実の食事に近く変換されているように見受けられます.(例えば,左から2列目など.)




こちらのアニメ版の結果に関しては, NeurIPS Workshop on Machine Learning for Creativity and Design (2018/12) に投稿し,上記の実食事画像の場合と同様にAcceptされています.自分が投稿したArt作品はこちら.
動画例
QiitaだとYoutubeの動画の埋め込みできないんですね...Twitterの埋め込み動画を使えばQiita内で再生できるっぽいですが,メンドイのでYoutubeへのリンクを貼ります.


考察
学習に用いるデータ数の変化による変換結果のクオリティへの影響
本実験では学習に用いるデータ数が23万枚と比べて小規模な場合,変換結果のクオリティがどのように変化するかの簡単な考察を行います.学習に用いるデータセットは3種類あり,合計のデータセット数が1万枚(Table 4.10), 10万枚(Table 4.11), FULL23万枚(Table 4.12)の場合,「牛丼」「カレー」「白飯」「冷やし中華」の4カテゴリについて,1カテゴリあたりの画像枚数,総画像枚数がどのようなクオリティを齎すか見てみましょう.
各条件により学習したモデルで変換した画像を総学習枚数が少ない順に左から並べたものを下図に示します.各カテゴリ千枚の比較的小規模なデータセットでも変換先ドメインの大域的特徴を捉えることには成功しているように見えますが,学習画像枚数が多いFULL23万枚版の変換結果を見ると,大域的特徴に加えて,局所的な特徴も捉えて変換できていることがわかります.
つまり,画像枚数が多ければ多いほど,大域的特徴に加えて局所的な特徴をもった細部の細かい部分まで正確に変換先のドメインに変換可能な写像関数の学習ができていることが見て取れますので,Deep Learningのデータ数は非常に重要ですね!!!


応用アプリ
HoloLensと組み合わせて質素な見た目の料理を豪華な食事へ?!
今回紹介した食事変換技術とMicrosoftのHoloLensを組み合わせて,大学の後輩くん(@nenoMake )と論文を書いたものがココに載せてあります.本技術を利用することで,例えば,病院食などの見た目を豪華にさせるというのはどうでしょうか?一般的な病院食(少なくとも,自分がヘルニアで入院していた2018年の1月頃の一般的な病院では)どうしても見た目が質素な食事になってしまいがちですが,HoloLens越しに病院食を見ることで,あたかも「ラーメン」を食べているかのように錯覚してしまうかもしれません!? 見た目だけでもいつも食べている食事にできれば,少しは気が紛れるかもしれませんね.笑
本論文はIEEE AIVR2018のワークショップで発表予定です.


おわりに
コードや例などはGithubでFood-Changer-GANで公開していますので,ぜひぜひ他の画像などでもお試しください.高品質食事画像23万枚で学習した奇跡の学習済みモデルもレポジトリに含めています.また,Google Colaboratoryを使った簡単なnotebook形式のデモも用意していますので,ポチポチして色々お試しあれ!!
(※ ここの下に明日の分の記事について書きます.※ )
参考文献
- S. Jiang and Y. Fu. "Fashion Style Generators", in Proc. of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017.
- J. Johnson, A. Alahi, and L.F. Fei "Perceptual Losses for Real-Time Style Transfer and Super-Resolution", in Proc. of European Conference on Computer Vision, 2016.
- Y. Matsuda, H. Hoashi, and K. Yanai "Recognition of Multiple-Food Images by Detecting Candidate Regions", in Proc. of IEEE International Conference on Multimedia and Expo, 2012.
- A. Odena, C. Olah, and J. Shlens "Conditional Image Synthesis With Auxiliary Classifier GANs", in Proc. of IEEE International Conference on Multimedia and Expo, 2012.
- K. Yanai and Y. Kawano "Twitter Food Image Mining and Analysis for One Hundred Kinds of Foods", in Proc. of Pacifit-Rim Conference on Multimedia (PCM), 2014.
- K. Yanai and R. Tanno "Conditional Fast Style Transfer Networks", in Proc. of ACM International Conference on Multimedia Retrieval, 2017.
- J. Y. Zhu, T. Park, P. Isola, and A. A. Efros "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", in Proc. of IEEE International Conference on Computer Vision, 2017.
- O. Ronneberger, P. Fischer, and T. Brox "U-Net: Convolutional Networks for Biomedical Image Segmentation", in Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2015.