はじめに
NTT Com アドベントカレンダー 2021 8 日目の記事です。
はじめまして!NTT Com イノベーションセンター所属の @negi111111 です。普段の業務では、AIモデルをノンコーディングで作成可能なデータ分析ツール「Node-AI」の開発や各要素技術に関する研究開発、また、社内AI勉強会コミュニティの運営などを行っています。
本記事では、AWS Re:Invent2021(11 月 29 日~ 12 月 3 日オンライン開催)で発表されたビジネスアナリスト向けノーコード機械学習機能「SageMaker Canvas」についてまとめます。
(今回紹介するサービスは普段の業務領域に非常に親しい分野でもあり、自分としても興味関心があったこと。また、先日発表されたということで、話題としてもホッとだと思ったため本ネタを書くに至りました。)
概要
- AWS Re:Invent2021 で発表された新サービス「SageMaker Canvas」についてまとめます
- 実際に「SageMaker Canvas」を使用した所感についてまとめます
- 今回はあまりネットに例が無かった「時系列予測」にフォーカスします
- 「時系列予測」については「Amazon Forecast」を内部で利用しているようです
- 他のタスクは「Amazon SageMaker Autopilot」
- 実行する際に遭遇したエラー等についてもまとめます
- 自前で用意したデータを利用しようとすると結構エラーに引っかかった。。。
- ひととおり触ってみて理解するのに利用した各種参照情報をまとめました
- テキストにリンクさせています
色々書きましたが、画像を見れば何となく雰囲気がわかるはず
キーワード
AWS Re:Invent, Amazon SageMaker, SageMaker Studio, SageMaker Canvas, Amazon Forecast, no code, machine learning, Time Series Forecasting, ノーコード, 時系列予測, アプリケーション
Amazon SageMaker Canvas とは
Amazon Web Services ブログによると以下のような記載があり、ノーコードで機械学習の機能を提供する新サービスです。(英語版のAWS News Blogでは本サービスの音声による紹介もあります ⇢Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capability for Business Analysts)
また、公式の動画も用意されているので、雰囲気を掴むのには良いかもしれません。
https://www.youtube.com/embed/Sy3GDQT6Lnk
ビジネスアナリストがコードを書いたり、ML の専門知識なしに、ML モデルを構築して正確な予測を生成できる、新しいビジュアルでコードを使用しない機能です(引用元: https://aws.amazon.com/sagemaker/canvas/)
ビジネスアナリスト向けを謳っていますが、SageMaker Canvas 上で分析したワークフローをSageMaker Studio(機械学習用統合開発環境)用に Export できる等の機能も備えており、大枠は SageMaker Canvas、細かい分析等は SageMaker Studioを利用するなど、柔軟に取捨選択ができそうで、エンジニアにとっても嬉しい機能を備えています。
勿論、母体は Amazon SageMaker であるので、これまで必要だった API を理解してコーディングする手間がノーコードで恩恵を預かれるのは嬉しいですね。
SageMaker Canvas は Amazon SageMaker と同じテクノロジーを活用して、データのクリーニングと結合、内部での数百のモデルの作成、もっともパフォーマンスの高いモデルの選択、新しい個別予測またはバッチ予測の生成を自動的に行います。バイナリ分類、複数クラス分類、数値回帰、時系列予測など、複数の問題タイプをサポート(引用元: https://aws.amazon.com/sagemaker/canvas/)
また、内部ではAmazon SageMaker Autopilot(AutoML)やAmazon Forecast(時系列予測)が動いていると推測します。ノーコードで AWS が提供する AutoML を利用できるのは非常に強力に感じました。
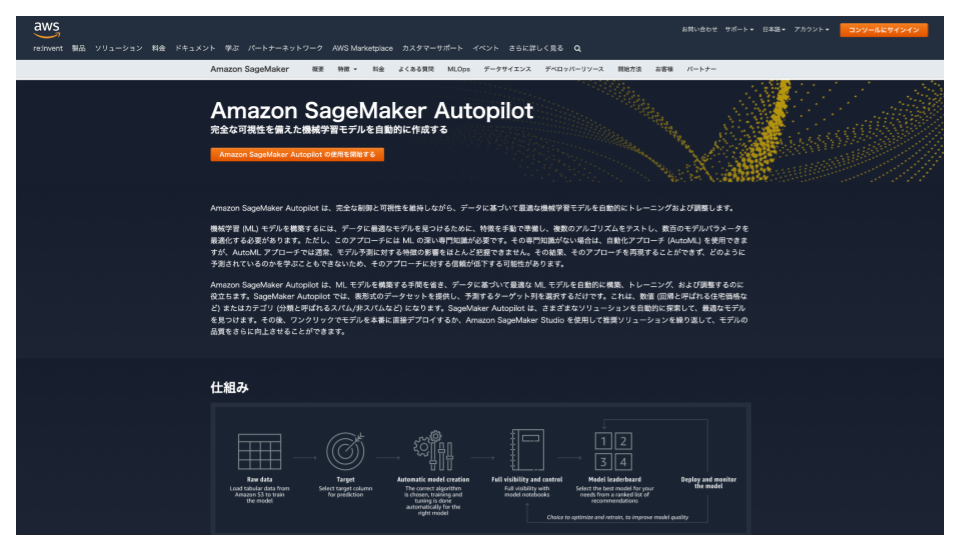
そんな SageMaker Canvas ですが、今回は「時系列予測」にフォーカスして、利用するまでに必要な設定や遭遇したエラーについてまとめてみました。また、利用した際に感じた所感についてもまとめたので、今後の参考になると嬉しいです。
SageMaker Canvas による時系列予測
基本は公式のドキュメントのGetting started with using Amazon SageMaker Canvasなどを参照しながら進めていきます。尚、使用可能なリージョンは限られているので注意してください。(※ 現在使用可能なリージョンは、AWS News Blogによると、US East (N. Virginia), US West (Oregon), Europe (Frankfurt), and Europe (Ireland) の 4 リージョンとなっています。)
※ 基本は公式のマニュアルベースに進めていけば問題ないですが、行間を埋めるような形で記載しています。
実行ロールの作成とポリシーの追加
事前準備には、マニュアルのPrerequisites for setting up Amazon SageMaker Canvasを参照しながら進めていきます。
SageMaker Canvas を利用するには、SageMaker の実行ロールを作成する必要があるので、準備しておきましょう。 すでに作成済みのロールがある場合は、そのロールを使用すれば良いですが、ない場合はアプリケーションの誘導にしたがって作成しましょう。
- (SageMaker を利用するために実行ロールを作成)
- 詳細はこちら
- SageMaker 実行ロール自体もアプリケーションの誘導に従えば基本は大丈夫です。
基本的な事前設定はここまでですが、「時系列予測」を行うためには IAM ロールに以下のポリシーを追加する必要があります。(※ 上手く設定されていない場合、エラー一覧にあるようなInsufficient permissionsがモデルの学習時に表示されるはずです。)
- 上記で作成したロールに対して、
AmazonForecastFullAccessポリシーを追加- 詳細はこちら
-
"Service"の部分が追記されているので、コピペしてください
時系列予測に関してはAmazon Forecastを内部で利用してることがわかりますね。
実行ロール設定と利用可能なリージョンを選択していれば「アプリケーションを起動」から「Canvas」が選択できるようになります。(※ 使用可能なリージョン以外だと表示されません)

上記の「Canvas」をクリックして下記のような画面が表示されれば前準備終了です。(※ 尚、ロードに時間がかかる場合もあったので気長に待ちましょう)
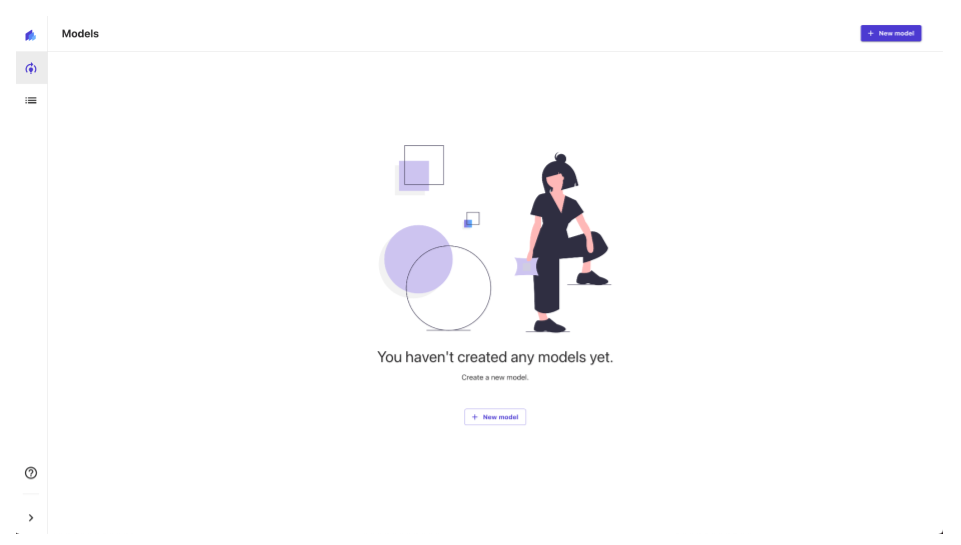
非常にシンプルですね。サイドバーには(一番上のアイコンを除いて)上からモデルとデータセットの 2 つしかありません。
また、左下の「?」マークを押すと、SageMaker Canvas の使い方が ↓ のようにモーダル表示され、これからの分析フロー概要を見ることができます。
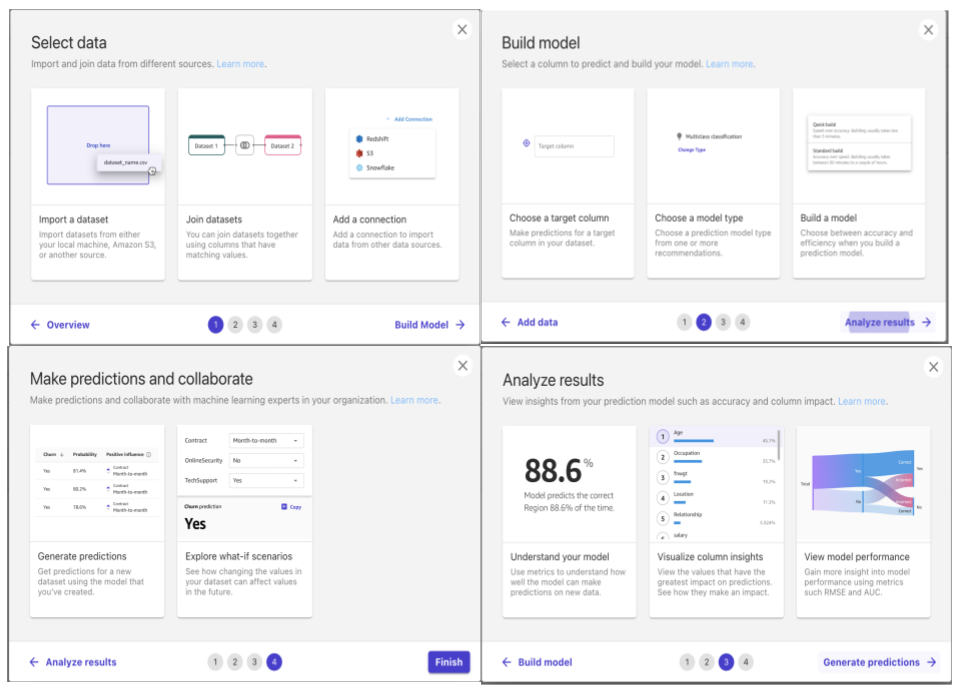
この後は、公式のチュートリアルの通りにすすめて行くのですが、SageMaker Canvas 自体のマニュアルにはどんなデータを与えればいいかのサンプルは載っていないので、ちょっと迷いポイントかなと思いました。
内部の実態は、Amazon SageMaker Autopilot(AutoML)やAmazon Forecast(時系列予測)と推測するので、それらのチュートリアルからデータを引っ張ってきて、SageMaker Canvas 上で扱うのが良さそうに感じました。
ただ、今回は上記で用いられているサンプルデータは利用せず、あえて自前でデータを用意することにしました。
自前で用意したデータを学習に喰わせるまでのハードルは地味に高そう(とくに時系列データに関しては難儀しそう)に感じたのと、後学のためにもトライアンドエラーの結果はなるべく残したほうが良いと感じたので、遭遇したエラー文もなるべく記載するようにしました。
今回用意したデータは UCI レポジトリにある Beijing PM2.5 Data Data Setを利用することにします。詳細はリンク先を見ていただくとして、カラム例だけ記載しておきます。
(引用元: https://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data)
pm2.5: PM2.5 concentration (ug/m^3)
DEWP: Dew Point
TEMP: Temperature
PRES: Pressure (hPa)
cbwd: Combined wind direction
Iws: Cumulated wind speed (m/s)
Is: Cumulated hours of snow
Ir: Cumulated hours of rain
データアップロードまで
データのアップロードにはStep 2: Import and manage dataを参照しながら進めていきます。
右上の「Import」ボタンからデータのアップロードを行うことができるようで、デフォルトで以下の 4 つの方法が利用できます。
- ローカルファイルからアップロード
- S3
- Snowflake
- Redshift
S3 については参照可能な S3 バケット一覧から利用したいオブジェクトをアップロードすることができ、また、Snowflake と Redshift についてはAdd connectionから選択することができる仕様にです。
一方で、手段 1 のローカルファイルからアップロードするためには、事前に、SageMaker Canvas が作成した S3 バケットに CORS ポリシーを追加する必要があるようで、公式ドキュメントによると、SageMaker Canvas への初回アクセス時に自動で作成される仕様とのこと。
When one of your users first accesses Amazon SageMaker Canvas, Amazon SageMaker creates an S3 bucket with a name that uses the following pattern:
sagemaker-*AWS-Region**AWS-account-id*.(引用元:https://www.notion.so/2021-1f483bca389a4cf88b57ccbc3be63eb4#b0cdf951a70e45bf917a10622f214190)
自分の環境で確認すると、 sagemaker-us-east-1-<AWS-account-id> として作成されていることが確認できました。SageMaker Canvas 上からアップロードしたファイルは、すべてここに格納される仕様のようです。(本題の CORS ポリシーの付与の詳細は公式ドキュメントを参照すると良さそう。)
アップロードしたデータは一覧に表示され、Status 部分にマウスをホバーすると、アップロードしたデータを表形式で参照できるようです。

また、アップロードしたデータ同士は「Join data」を用いて結合したりもできます。(専用のビューが存在して、結合したいデータを一覧から Drag and drop して結合する UI が提供されています。)詳細はこちら
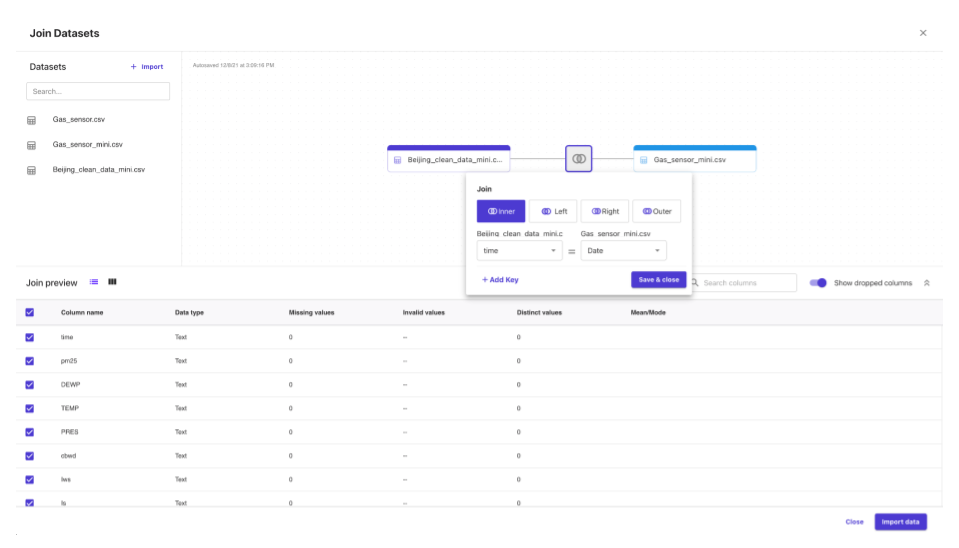
データアップロードまでは、とくに詰まることは無かったので次に進んでみます。
データ探索から学習、評価まで
アップロードしたデータを用いて学習するにはStep 3: Build a modelを参照しながら進めていきます。
**データ選択(Select data)⇢ モデル学習(Build model)⇢ 結果分析(Analyze results)⇢ 結果取得(Generate predictions)**のステップを踏むのですが、基本は数クリックすれば学習から結果の取得プロセスまで進んでいきます。
データを選択して画面左上にある「Select a column to predict」において予測するカラムを選択すると、SageMaker Canvas が自動的に「Model type」のレコメンドをしてくれる仕様のようです。
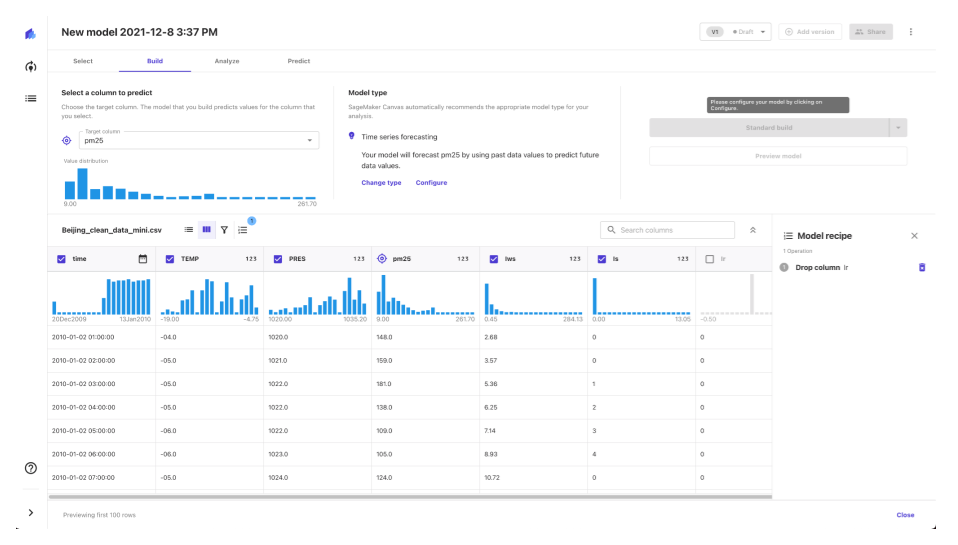
上記の画面だと今回利用したい「Time series forecasting」として適切にレコメンドされていますが、場合によってはレコメンドが思ったものと違ったりする場合が多々合ったので、その場合はどうすればいいのか疑問でした。(※ レコメンドされた Model type 以外は基本、グレーアウトされてしまうのと、自動判定なので、どうすればいいのだろう?)
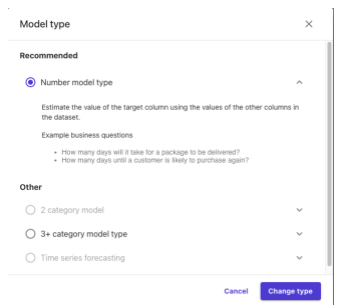
また、各データの分布も参照することはできますが、何らかの処理を追加する等はできない仕様のようです。また、無効なカラム(定数値など)は自動的に外したり、欠損値等がある場合はアラート(例: モデルの精度に影響を及ぼします等)を出してくれる「Model recipe」機能があるようです。
ただ基本は AutoML の立ち位置をとっているので、ユーザ側が SageMaker Canvas 上でデータの中身を操作する等、直接データに介入するような操作はほぼ無く、必要な前処理と学習が自動的に行われます(カラム選択やデータの結合のみ)
While Amazon SageMaker Canvas is building the model, it automatically adds missing values for datasets that don't have time series data. SageMaker Canvas uses the values in your dataset to perform a mathematical approximation for the missing values. For the highest model accuracy, we recommend adding in the missing data if you can find it.(引用元: https://docs.aws.amazon.com/sagemaker/latest/dg/canvas-build-model.html)
カラムの選択や学習する「Model type」を設定し終えたら、「Build」ボタンを押せば下記の画面に遷移します。終わるまで待ちぼうけです。
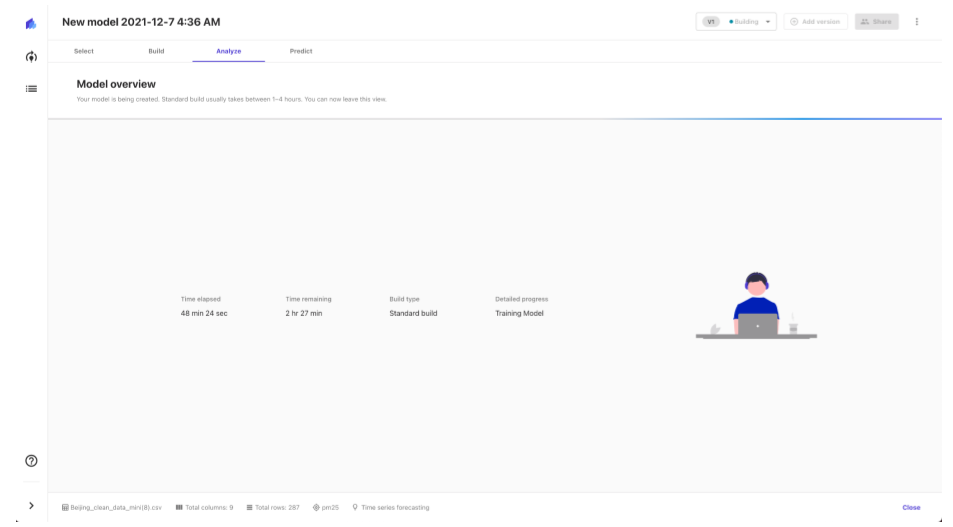
途中で学習を止める機能等は提供されておらず、また、削除等もできないように見えるので、結構注意が必要かもしれません。
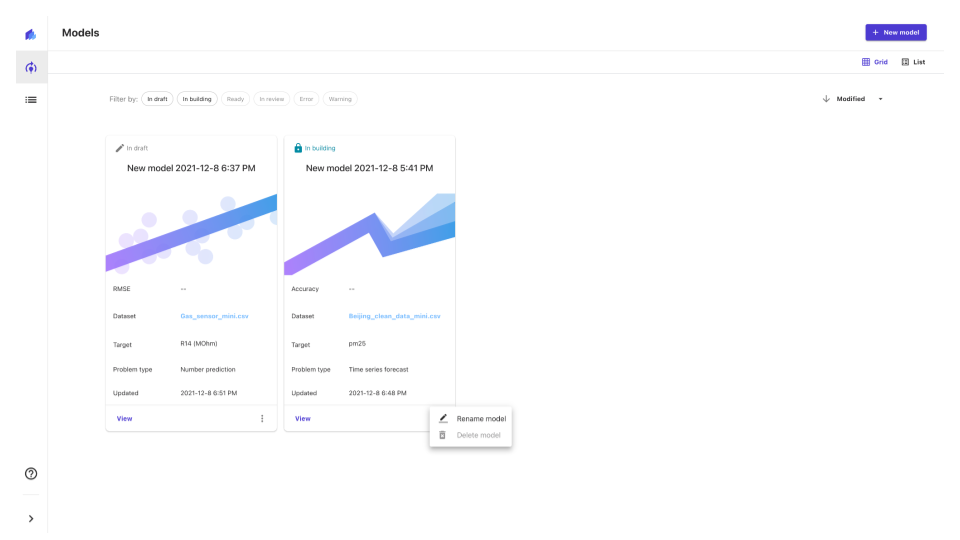
学習が終われば次は評価のステップに入りますが、これ以降はとくに操作上で詰まることは無かったので詳細についてはマニュアルのStep 4: Evaluate your modelの参照に委ねます。
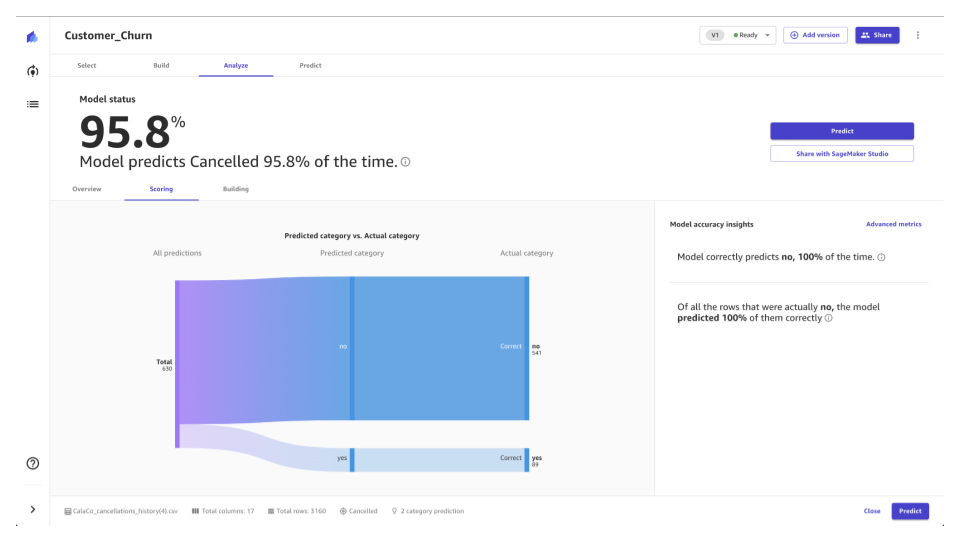
評価の部分は良い感じの画像は見繕え無かったので、公式サンプルから引用します。(画像はModel Scoringから引用)特徴量重要度や予想理解については、Amazon SageMaker Clarifyなどが利用されていると推測します。
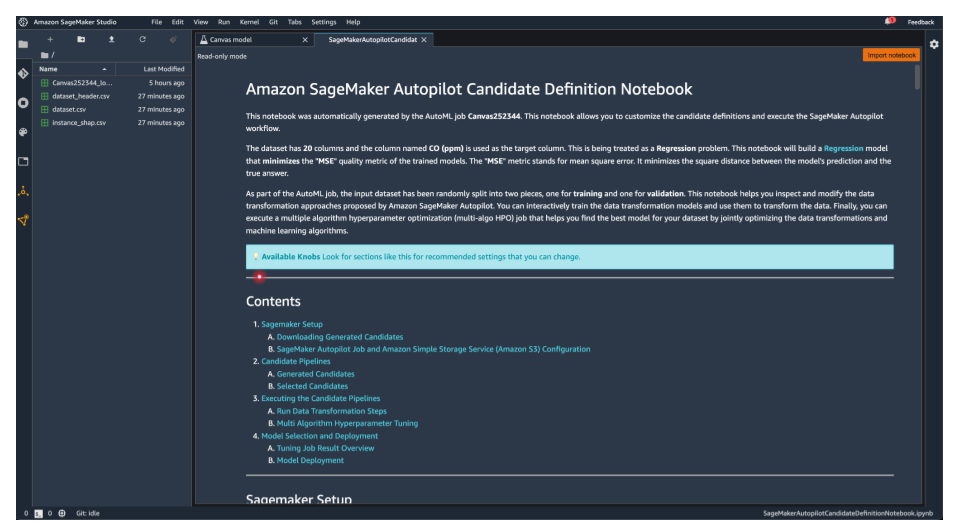
学習した Canvas(SageMaker Canvas におけるワークフローの 1 単位)をSageMaker Studio(機械学習用統合開発環境)に Export してみると、AutoML が算出した分析パイプラインを IDE 上で参照することもできるので、大枠はビジネスアナリストが担当し、以降はデータサイエンティスト等が分析を進めるといった分担がスムーズに進むと感じました。(shap 値も csv として吐き出されてるのがわかります。)
以降は実際に触ってみて感じた所感について触れます。
良いと思った点
- UI/UX
-
シンプルな UI
- 大枠のユーザ導線は「分析に必要なデータを準備」⇢「モデルを作成する」であり、SageMaker Canvas のサイドバー上のアイコン 2 つがそれに相当する。
- 「モデルを作成する」部分は後述する Simple 4Steps のワークフローに相当する。
- データ選択)Select data)⇢2. モデル学習(Build model)⇢3. 結果分析(Analyze results)⇢4. 結果取得(Generate predictions)の分析フローをタブで切り替えるような UI は、各ステップ毎の役割が明確で、初学者的には迷わないで済みそう。
- 大枠のユーザ導線は「分析に必要なデータを準備」⇢「モデルを作成する」であり、SageMaker Canvas のサイドバー上のアイコン 2 つがそれに相当する。
-
分析ワークフローの提示
- 利用までの分析ワークフローは以下の画像の様に、Simple 4Steps としてユーザにシナリオを提示するのはイメージが湧きやすい様に感じた。
-
シンプルな UI
- サービス
-
SageMaker シリーズの正当進化としての「SageMaker Canvas」
- SageMaker を母体とした各種 ML サービスとの連携およびその他の AWS サービス連携はポータビリティが高すぎる
- AWS の基盤という偉大さ。土台がしっかりしているからこそ、痒いところはいったん目を瞑ってまでも検証したくなるサービス
-
あくまでも「ビジネスアナリスト向け」であること
- 研究者・開発者などコードを主体とする場合 ⇢SageMaker Studio、ノーコード主体 ⇢SageMaker Canvas として責務の棲み分け
- 一方、土台は SageMaker なので連携できるのは強み
-
SageMaker シリーズの正当進化としての「SageMaker Canvas」
- 機能
-
各サービスが提供する API を直接叩かなくても恩恵を享受できる「ノーコード」の威力と AWS 基盤上での実行、スケール性
- API を理解せずとも実行できるのは非常にありがたい
- ただ、内部的 Amazon Forecast など大きなサービスが動いているので、各種リファレンス参照は理解には必須(当たり前ですが、、)
-
必要そうな機能はバッサリカットされているのも好印象
- 選択したデータに合わせて、自動で Model type(バイナリ分類、複数クラス分類、数値回帰、時系列予測など)が選択される
- データに寄っては有りえない Model type の場合はそもそも選択の余地がない
- 選択したデータに合わせて、自動で Model type(バイナリ分類、複数クラス分類、数値回帰、時系列予測など)が選択される
-
各サービスが提供する API を直接叩かなくても恩恵を享受できる「ノーコード」の威力と AWS 基盤上での実行、スケール性
疑問な点は要所要所に思ったことは書いたので省略します。
結論
一言で言えば、「SageMaker Autopilot や Forecast、Clarify などの恩恵をデータさえ用意すれば数クリックで利用できるようになるスゲーやつ。細かい分析は Studio 用に Export してデータサイエンティストと役割分担可能。」
SageMaker が持つ多様な分析機能を数クリックで AWS 基板上で実行できるのはやはり非常に強力ですね。
一方で、(当たり前ですが)各種 SageMaker の機能はひととおり参照しておくと SageMaker Canvas の理解がはかどるので、Forecast 等のリファレンスは必須だと思いました。
また、SageMaker Canvas 自体は発表されてから一週間程しか経っていないのでブログなどのドキュメントは少ないですが、Autopilot や Forecast などに関するブログ記事は多いので、案外スムーズに理解できると思いました。
ノーコードの次は一体何が・・・来年の Re:Invent は是非、オフラインで現地で楽しみたいですね!
(結構長くなってしまいましたが、最後まで目を通して頂きありがとうございました。)
遭遇したエラー一覧
結構出るかな?と思ったのですが、まとめたら思ったより無かった。
Insufficient permissions for building timeseries forecasting models, please refer https://docs.aws.amazon.com/sagemaker/latest/dg/canvas-set-up-forecast.html
-
AmazonForecastFullAccessの設定が上手く設定されていない場合に表示されます
An error occurred (InvalidInputException) when calling the CreateDataset operation: Field name Is should not contains a reserved word
- データのカラム内に予約語を含んでいるとエラーになるみたいです
- 今回の場合だと、カラム内部の
lsやTEMPがエラーとして検出されてしまいました
- 今回の場合だと、カラム内部の
The predictive accuracy of the model might be lower for datasets with fewer than 500 rows
-
時系列予測ではない場合は、最低でも 500 行以上のデータが必要みたいです。
-
一方、時系列の場合は、学習に利用するデータは 250 行以上、また、2 カラム以上のデータでないとエラーになるようです。
-
タイムスタンプのデータ形式問題
- 2010-1-13 は NG。2010-01-13 である必要があるなど。