Webスクレイピングとは
スクレイピング(Scraping)とは、Webサイトから任意の情報を検索し抽出する技術のことです。
また、Web上のデータの取得だけではなく、構造も解析できます。
Webスクレイピングをする前に
スクレイピングを行う前に、確認するべき点や、作業中に気を付ける必要がある点がいくつかかありますので説明します。
1)APIが存在するかどうか
APIを提供しているサービスがあればそちらを使い、データを取得しましょう。
それでも、データが不十分だったりなどの問題があるのであればスクレイピングを検討します。
2)取得後のデータの用途に関して
取得後のデータを使う場合には、注意が必要です。
取得先のデータは自分以外の著作物にあたり、著作権法に抵触しないように考慮する必要があるためです。
私的利用のための複製(第30条)
http://www.houko.com/00/01/S45/048.HTM#030
情報解析のための複製等(第47条の7)
http://www.houko.com/00/01/S45/048.HTM#047-6
また、特に問題となる3つの権利として以下が挙げられます。
- 複製権:
製権は、著作権に含まれる権利のひとつで、著作権法第21条で規定されています。(第21条「著作者は、その著作物を複製する権利を専有する。」)
複製とは、作品を複写したり、録画・録音したり、印刷や写真にしたり、模写(書き写し)したりすること、そしてスキャナーなどにより電子的に読み取ること、また保管することなどを言います。
引用先: https://www.jrrc.or.jp/guide/outline.html
- 翻案権:
翻訳権・翻案権は、著作権法第二十七条に規定されている著作財産権です。第二十七条では「著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案する権利を専有する」(『社団法人著作権情報センター』 http://www.cric.or.jp/db/article/a1.html#021より)と明記されています。反対に見ると、これらを著作者の許諾なしに行うと、著作権の侵害になるということです。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/honyaku_honan.html
- 公衆送信権:
公衆送信権は、著作権法第二十三条において規定される著作財産権です。この第二十三条では「著作者は、その著作物について、公衆送信(自動公衆送信の場合にあっては、送信可能化を含む。)を行う権利を占有する。」「著作者は、公衆送信されるその著作物を受信装置を用いて公に伝達する権利を占有する。」と明記されています。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/kousyusoushin.html
また上記を注意しながら、実際にスクレピングを行う際に、書いたコードによってサーバに負荷がかからないようにしましょう。
過度なアクセスはサーバに負担をかけてしまい攻撃だとみなされてしまい、最悪の場合一定期間サービスを利用できなくなってしまう可能性があります。
さらには、システムにアクセス障害が発生し、利用者の一人が逮捕された事件もありますので、常識の範囲内での使用してください。
https://ja.wikipedia.org/wiki/岡崎市立中央図書館事件
以上を踏まえた上で、次に進んでいきましょう。
HTML基礎
Webスクレイピングを実践する際にHTMLの基礎を知っておくと便利です。
なぜかというと、HTMLで使われるタグ(<html>や<div>、<p>)を指定してデータを取得するからです。
ちょっと例をあげてみましょう。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<p>neet-AIのリンクはこちら</p>
<a href="https://neet-ai.com">neet-AI</a>
</div>
</body>
</html>
上記のコードをブラウザ上で見ると
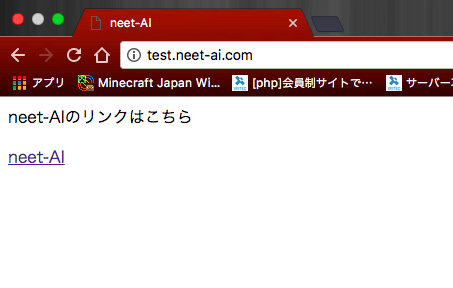
このようなページがでてきます。
このページ上で使われているHTMLタグについて解説していきましょう。
HTMLタグ一覧
| タグ名 | 説明 |
|---|---|
| <html></html> | これはHTMLのコードですよと明示するタグ |
| <head></head> | ページの基本的情報(文字コードやページタイトル)を表します。 |
| <title></title> | ページタイトルを表します。 |
| <body></body> | ページの本体を表します。 |
| <div></div> | タグ自身には意味はありませんが、これで1コンテンツと表すときによく使われます。 |
| <p></p> | このタグで囲まれた文はこれで1段落と表します。 |
| <a></a> | 他ページへのリンクを表します。 |
上記で説明したタグ以外にも種類はたくさんあります。どのようなタグかきになる場合にはその都度調べてみましょう。
Webスクレイピング基礎
HTMLのタグについて理解できたので、さっそくスクレイピングをしてみましょう。
Webスクレイピングの基本的手順
1.Webページを取得する
2.プログラムで、指定したタグを検索し抽出する(スクレイピング)
3.スクレイピングして得たデータを整形し保存or表示する
以上の手順がスクレイピングの基本手順です。
使用するライブラリ
PythonでWebスクレイピングする場合にはさまざまなライブラリを使っていきます。
・Requests
Webページを取得する際に使います。
・BeautifulSoup4
取得したWebページを解析し、タグの検索、データの整形をします。
上記のライブラリを使ってWebスクレイピングをしていきます。
Pythonでスクレイピングする準備
スクレイピングをする前にPythonでWebページのHTMLをとってくる必要があります。
import requests
response = requests.get('http://test.neet-ai.com')
print(response.text)
各行の説明をしていきましょう。
response = requests.get('http://test.neet-ai.com')
この行ではhttp://test.neet-ai.comからHTMLをとってきてます。
とってきたHTMLはresponse変数に入ります。
print(response.text)
responseという変数はtextをつけないとBeautifulSoupで使えません。
ページのタイトルをスクレイピング
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com')
soup = BeautifulSoup(response.text,'lxml')
title = soup.title.string
print(title)
百聞は一見にしかずでプログラムをみていきましょう。
4行目までは先ほどの「Pythonでスクレイピングする準備」と変わりありません。
5行目からがスクレイピングのプログラムとなりますので各行を解説していきましょう。
soup = BeautifulSoup(response.text,'lxml')
ここではsoupという変数を用意し、取ってきたHTMLデータをスクレイピングできる形にしています。
カッコ内の'lxml'というのは 「lxmlというツールでresponse.textを変換するよ」 という意味です。
title = soup.title.string
取ってきたHTMLデータを変換できたら、BeautifulSoupの決まった型で指定してあげれば指定のデータを抽出することができます。
このプログラムを順を追って解説していきましょう。
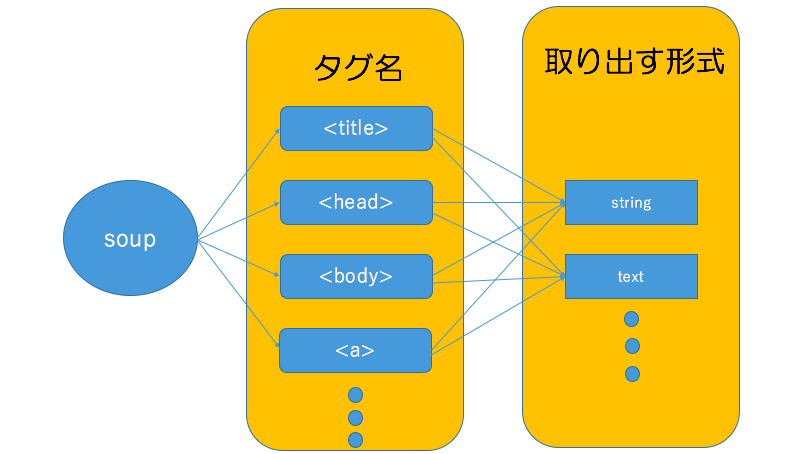
soup変数の中からtitleというタグを探し、titleタグ内の文字列をstring形式で出力するという感じです。
ここはちょっとプログラム的に理解しにくいので直感的に理解した方がいいかもしれません。
このままでは理解しにくいので以下のような感じでイメージしていただければ幸いです。
さらに詳しい形式などはここで紹介すると時間が足りないので下記URLをご参考にしてください。
このプログラムを実行することによって以下の結果が出れば成功です。
neet-AI
リンク先をスクレイピング
まずはじめに、HTMLでリンクを表すには<a></a>タグが使われます。
この場合は、aタグ内のURLを取得したいので、string形式は使えません。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com')
soup = BeautifulSoup(response.text,'lxml')
link = soup.a.get('href')
print(link)
get()という関数を使うことによってリンクが貼ってあるhrefを取得することができます。
get()関数はこの先頻繁に使う上に、便利なのでぜひ覚えておきましょう。
複数のリンク先をスクレイピング
これまで参照していたページはaタグが1つのみでした。
ではaタグが複数あるページではどうスクレイピングすればよいのでしょう?
まずはじめにaタグが複数あるページで以前のプログラムを実行してみましょう。
ページを取得する行のURLを変えましょう。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index2.html')
soup = BeautifulSoup(response.text,'lxml')
link = soup.a.get('href')
print(link)
実行してみると、neet-AIのリンクしか表示されませんね。
これは、soup.a.get('href')で最初に見つかったaタグしか抽出していないからです。
全てのaタグを抽出したい場合には以下のようになります。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index2.html')
soup = BeautifulSoup(response.text,'lxml')
links = soup.findAll('a')
for link in links:
print(link.get('href'))
各行を解説していきましょう。
links = soup.findAll('a')
ここで全てのaタグを抽出し、一度linksというリストに入れています。
for link in links:
print(link.get('href'))
リスト型なので、forで回してあげると1個ずつ操作が可能になります。
操作が可能になったlink変数にget()関数を使ってあげることによって各URLを取得することができます。
この一度全てのタグを取得し、操作できるようにforで回す手法も今後よく使うので覚えておきましょう。
スクレイピングからのスクレイピング
簡単に行ってしまえば、
ページ内のURLスクレイピング→取得したURL先をrequests→再びスクレイピング
といった感じです。
Pythonの基本文法さえ押さえていればこれは簡単です。
それでは、https://test.neet-ai.com/index3.htmlからスクレイピングでURLを取得し、URLであるhttps://test.neet-ai.com/index4.htmlをスクレイピングしTwitterリンクとfacebookリンクを取得してみましょう。
import requests
from bs4 import BeautifulSoup
# スクレイピング1回目
response = requests.get('http://test.neet-ai.com/index3.html')
soup = BeautifulSoup(response.text,'lxml')
link = soup.a.get('href')
# スクレイピング2回目
response = requests.get(link)
soup = BeautifulSoup(response.text,'lxml')
sns = soup.findAll('a')
twitter = sns[0].get('href')
facebook = sns[1].get('href')
print(twitter)
print(facebook)
複数回のリクエスト、スクレイピングをすることによってサイトやページを跨いでスクレイピングをすることができます。
idまたはclassを指定したスクレイピング
これまでは、タグにidやclassは記載されていませんでした。
しかし、一般的なサイトではWebデザインをしやすいようにまたはプログラムの可読性を高めるためにタグにidやclassを設定します。
idやclassが設定されたからといって、スクレイピングが格段と難しくなるわけではありません。
逆に「この内容だけをスクレイピングしたい!」と言った場面で楽になるかもしれません。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<a id="neet-ai" href="https://neet-ai.com">neet-AI</a>
<a id="twitter" href="https://twitter.com/neetAI_official">Twitter</a>
<a id="facebook" href="https://www.facebook.com/Neet-AI-1116273381774200/">Facebook</a>
</div>
</body>
</html>
例えば上記のようなサイトがあるとします。
aのタグをみてもらえればわかりますが、全てにidが付与されています。
この時にtwitterのURLを取得したいといった場合にはこう記述することができます。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index5.html')
soup = BeautifulSoup(response.text,'lxml')
twitter = soup.find('a',id='twitter').get('href')
print(twitter)
findの2番目にid名を指定してやると簡単に取ることができます。
次はclassにしてみます。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<a class="neet-ai" href="https://neet-ai.com">neet-AI</a>
<a class="twitter" href="https://twitter.com/neetAI_official">Twitter</a>
<a class="facebook" href="https://www.facebook.com/Neet-AI-1116273381774200/">Facebook</a>
</div>
</body>
</html>
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index6.html')
soup = BeautifulSoup(response.text,'lxml')
twitter = soup.find('a',class_='twitter').get('href')
print(twitter)
ここで注意してほしいのは、**classではなく、class_**です。
pythonではあらかじめ予約語(言語仕様上特別な意味を持った語)としてclassが登録されているからです。
これを回避するために、BeautifulSoupライブラリ作成者はアンダーバーをつけたのでしょう。
Webスクレイピング応用
これまでのWebスクレイピング基礎は、こちらがWebスクレイピングをしやすいように設計したHTMLページです。
しかし、一般のWebサイトではスクレイピングするために設計はされていないので、とても複雑な構造になっている場合があります。
とても複雑になっているゆえにスクレイピング以外にもWebページの特性などのスクレイピング以外の知識が必要となってきます。
応用編では複雑なサイトもコツを掴めばある程度はスクレイピングできるようになるので、応用編でノウハウを培っていきましょう。
その都度デバッグ
スクレイピングする際に、URLをスクレイピングしてURL先をまたスクレイピングするという場面が多々現れます。
この場合には一気にプログラムを組もうとしないで、1つのスクレピングプログラムができたらその都度デバッグしていきましょう。デバッグしてURLが全部表示されるのであれば、またその先のスクレイピングプログラムを作っていく感じです。これはプログラミング全般に言えることかもしれませんね。
Webページの通信特性を使う
この手法はかなり重宝します。
niftyニュースを例に取って説明していきます。
例えばITカテゴリでページ送りできるページがあります。
実際に下の2番目を押してページ送りしてみましょう。
再びURLをみて見ると、
https://news.nifty.com/technology/2
となります。
それでは次に3ページ目に移動してみましょう。
3ページ目ではこのようなURLです。
https://news.nifty.com/technology/3
サーバサイドの開発をしたことがある方ならわかると思いますが大抵、ページ送りのページを作る際には
URL末尾やパラメータにページ数を入れて、ページを更新していきます。
この仕組みを利用すれば、URLの数字を入れ替えるだけでページ送りをすることができます。
試しに末尾を好きな数字に変えてみてください。その数字に飛べると思います。(限界はありますが)
それでは試しにプログラム上で1ページ目から10ページ目までの検索結果をスクレイピングするプログラムを作ってみましょう。
import requests
from bs4 import BeautifulSoup
for page in range(1,11):
r = requests.get("https://news.nifty.com/technology/"+str(page))
r.encoding = r.apparent_encoding
print(r.text)
このようになります。
検索結果や連番になっているURLをスクレイピングする際はこの手法が便利です。
限界を知る
先ほどの「Webページの通信特性を使う」でURLを弄ってスクレイピングしていたと思いますが、限界を知らずにスクレイピングしてしまうと、限界を超えた結果はNoneや404のデータになってしまいます。これを防ぐためにあらかじめ、手動でページの限界を知っておき、プログラムに組み込んでおきましょう。
Webスクレイピング実践
基礎とコツを掴んだところので、実際にWebサイトで自動的に大量のデータをスクレイピングしてみましょう。
課題:気象庁のサイトから過去の気象データを2000年1月1日から2003年12月31日まで取ってきてみましょう。
http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=2000&month=06&day=1&view=a2
SampleOutput
>python ●●●●.py
29
1013.8
1018.2
1012.5
19:27
--
--
--
--
--
8.1
13.8
16:24
2.6
07:16
4.9
46
28
16:24
30
1013.6
1018.0
1013.2
00:05
--
--
--
--
--
9.0
13.1
12:16
5.3
02:51
4.6
41
27
21:50
サンプルプログラム
スクレイピングというのは、目的のデータが取って来れればいいのです。
なのでプログラムは全員が同じになる必要はありません。
ここでは、私が作成したプログラムを掲載していおきます。
import requests
from bs4 import BeautifulSoup
# URLで年と月ごとの設定ができるので%sで指定した英数字を埋め込めるようにします。
base_url = "http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=44&block_no=47662&year=%s&month=%s&day=1&view=a2"
# for文で2000年~2003年までの3回を回します。
for year in range(2000,2004):
#入れ子のforで1月~12月の12回を回します。
for month in range(1,13):
#for文で2000年1月...2月...3月と回せるので埋め込んで行きます。
r = requests.get(base_url%(year,month))
r.encoding = r.apparent_encoding
#対象である表をスクレイピングしていきます。
soup = BeautifulSoup(r.text,'lxml')
rows = soup.findAll('tr',class_='mtx')
i = 1
#表の最初の1〜3行目はカラム情報なのでスライスしていまいます。
rows = rows[4:]
#for文で1日〜最終日までの1行を取得します。
for row in rows:
data = row.findAll('td')
#1行の中には様々なデータがあるので全部取り出してあげます。
for d in data:
print(d.text)
print("")
寄付していただければ幸いです!
仮想通貨
BTC 18c58m54Lf5AKFqSqhEDU548heoTcUJZk
ETH 0x291d860d920c68fb5387d8949a138ee95c8d3f03
ZEC t1KtTRKy9w1Sv5zqi3MYnxZ3zugo54G4gXn
REP 0x291d860d920c68fb5387d8949a138ee95c8d3f03