GCIデータサイエンティスト育成講座
「GCIデータサイエンティスト育成講座」は、東京大学(松尾研究室)が開講している"実践型のデータサイエンティスト育成講座およびDeep Learning講座"で、演習パートのコンテンツがJupyterNoteBook形式で公開(CC-BY-NC-ND)されています。
Chapter7は「Matplotlibを使ったデータ可視化」で、Chapter2で学んだ散布図、折れ線グラフ、ヒストグラムに加えて、棒グラフ、円グラフ、バブルチャート、ローソクチャートを学習していきます。
日本語で学べる貴重で素晴らしい教材を公開いただいていることへの「いいね!」ボタンの代わりに、解いてみた解答を載せてみます。間違っているところがあったらご指摘ください。
章末の総合問題がやけに難しかったです。そもそも問題の意図を理解できているのやら……。
Chapter7 Matplotlibを使ったデータ可視化
7.1 データの可視化
7.1.1 データ可視化の基礎
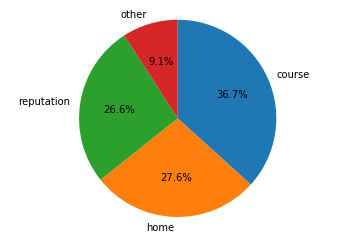
<練習問題 1>
以前扱った学生のデータ(student-mat.csv)を使って、学校を選んだ理由(reason)を円グラフ化して、それぞれの割合を出してください。
import matplotlib.pyplot as plt
student_data_math = pd.read_csv("student-mat.csv",sep=";")
allCount = len(student_data_math["reason"])
reasonCount = student_data_math["reason"].value_counts()
reasonRatio = reasonCount / allCount
plt.pie(reasonRatio.values, labels=reasonRatio.index, autopct='%1.1f%%', startangle=90, counterclock=False)
plt.axis('equal')
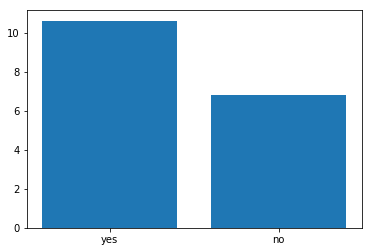
<練習問題 2>
上記と同じデータで、higher - 高い教育を受けたいかどうか(binary: yes or no)を軸にして、それぞれの数学の最終成績G3の平均値を棒グラフで表示してください。ここから何か推測できることはありますか?
import matplotlib.pyplot as plt
student_data_math = pd.read_csv("student-mat.csv",sep=";")
x = student_data_math["higher"].unique()
y = []
for x_ in x:
y.append(student_data_math["G3"][student_data_math["higher"] == x_].mean())
plt.bar(x, y)
**<練習問題 3>
上記と同じデータで、通学時間(traveltime)を軸にして、それぞれの数学の最終成績G3の平均値を横棒グラフで表示してください。何か推測できることはありますか?
import matplotlib.pyplot as plt
student_data_math = pd.read_csv("student-mat.csv",sep=";")
x = student_data_math["traveltime"].unique()
y = []
for x_ in x:
y.append(student_data_math["G3"][student_data_math["traveltime"] == x_].mean())
plt.barh(x,y)

7.1.2 応用:金融データの可視化
7.2 分析結果の見せ方を考えよう
7.2.1 資料作成のポイントについて
7.3 総合問題
7.3.1 時系列データ分析
ここでは、本章で身に付けたpandasやscipyなどを使って、時系列データついて扱っていきましょう。(1)(データの取得と確認)下記のサイトより、dow_jones_index.zipをダウンロードし、中にあるdow_jones_index.dataを使って、データを読み込み、はじめの5行を表示してください。またデータのそれぞれのカラム情報等を見て、nullなどがあるか確認してください。
https://archive.ics.uci.edu/ml/machine-learning-databases/00312/dow_jones_index.zip
# (1)
# import requests, zipfile
# from io import StringIO
# import io
# zip_file_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00312/dow_jones_index.zip"
# r = requests.get(zip_file_url, stream=True)
# z = zipfile.ZipFile(io.BytesIO(r.content))
# z.extractall()
data = pd.read_csv("dow_jones_index.data")
data[:5]

(2)(データの加工)カラムのopen、high、low、close等のデータは数字の前に$マークが付いているため、これを取り除いてください。また、日時をdate型で読み込んでいない場合は、date型に変換しましょう。
# (2)
data.open = data.open.str.strip("$").astype(float)
data.high = data.high.str.strip("$").astype(float)
data.low = data.low.str.strip("$").astype(float)
data.close = data.close.str.strip("$").astype(float)
data.date = pd.to_datetime(data.date)
data[:5]
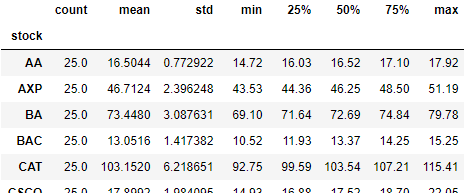
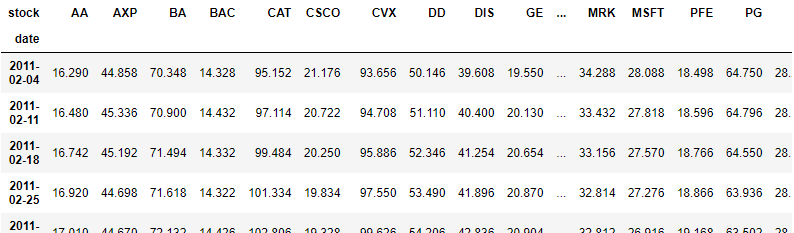
(3)カラムのcloseについて、各stockごとの要約統計量を算出してください。
# (3)
data.groupby("stock").close.describe()
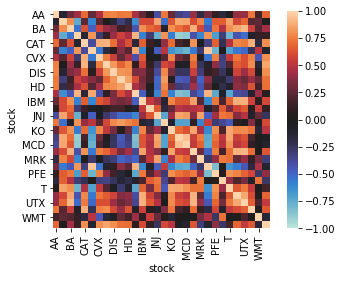
(4)カラムのcloseについて、各stockの相関を算出する相関行列を出してください。また、seabornのheatmapを使って、相関行列のヒートマップを描いてみましょう。(ヒント:pandasのcorr()を使います。)
# (4)
# 突然、設問が不親切に…。
# "stock"毎に"date(説明変数)"に対する"close(目的変数)"の値を見たとき、
# "close"の推移が相関する"stock"を探すという意味?
import seaborn as sns
pv = data.pivot(index="date", columns="stock", values="close")
cr = pv.corr()
sns.heatmap(cr, square=True, vmax=1, vmin=-1, center=0)
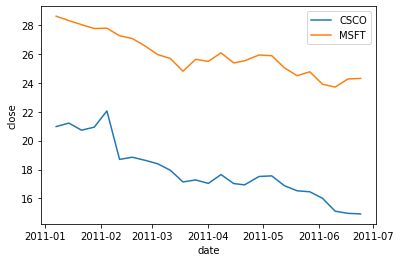
(5)(4)で算出した相関行列の中で一番相関係数が高いstockの組み合わせを抽出してください。さらに、その中でもっとも相関係数が高いペアを抜き出し、それぞれの時系列グラフを書いてください。
# (5)
# 相関係数が高い組み合わせの中の、さらに相関係数が高いペア…とは?
# 組み合わせ = ペア?
cr = data.pivot(index="date", columns="stock", values="close").corr()
cr[cr==cr[cr<1].max().max()]
# --
plt.plot(pv.index, pv.CSCO, label="CSCO")
plt.plot(pv.index, pv.MSFT, label="MSFT")
plt.xlabel("date")
plt.ylabel("close")
plt.legend()

(6) pandasのrollingとwindow関数(窓関数)を使って、上記で使った各stockごとに、closeの過去5期(5週間)移動平均時系列データを計算してください。
# (6)
pv.rolling(5).mean().dropna()
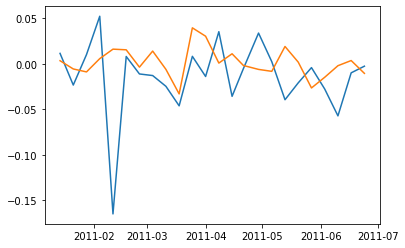
(7) pandasのshift()を使って、上記で使った各stockごとに、closeの前期(1週前)との比の対数時系列データを計算してください。さらに、この中で、一番ボラティリティ(標準偏差)が一番大きいstockと小さいstockを抜き出し、その対数変化率グラフを書いてください。
# (7)
pv_lgrt = np.log(pv/pv.shift()).dropna()
print(pv_lgrt.std()[pv_lgrt.std()==pv_lgrt.std().max()])
print(pv_lgrt.std()[pv_lgrt.std()==pv_lgrt.std().min()])
# --
plt.plot(pv_lgrt.index, pv_lgrt.CSCO)
plt.plot(pv_lgrt.index, pv_lgrt.KO)
> Max stock
> CSCO 0.041205
> dtype: float64
> Min stock
> KO 0.01623
> dtype: float64
7.3.2 マーケティング分析
次は、マーケティング分析でよく扱われる購買データです。一般ユーザーとは異なる法人の購買データですが、分析する軸は基本的に同じです。(1)下記のURLよりデータをpandasで読み込んでください(件数50万以上のデータで比較的大きいため、少し時間がかかります。)
"http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"
(ヒント)pd.ExcelFileを使って、シートを.parse('Online Retail')で指定してください。
また、今回の分析対象は、CustomerIDにデータが入っているレコードのみ対象にするため、そのための処理をしてください。さらに、カラムのInvoiceNoには数字の前にCがあるものはキャンセルのため、このデータを取り除いてください。他にもデータとして取り除く必要なものがあれば、適宜処理してください。以下、このデータをベースに分析していきます。
# (1)
import requests
import pandas as pd
# xlsx_file_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"
# r = requests.get(xlsx_file_url, stream=True)
# with open("Online%20Retail.xlsx", 'wb') as saveFile:
# saveFile.write(r.content)
book = pd.ExcelFile("Online%20Retail.xlsx")
data = book.parse("Online Retail")
# --
data_ = data.dropna(subset = ["CustomerID"])
mask = data_['InvoiceNo'].str.startswith('C', na=False)
data_ = data_[~mask]
data_.head()

(2)このデータのカラムには、購買日時や商品名、数量、回数、購買者のIDなどがあります。ここで、購買者(CustomerID)のユニーク数、バスケット数(InvoiceNoのユニーク数)、商品の種類(StockCodeベースとDescriptionベースのユニーク数)を求めてください。
# (2)
print("CustomerID unique:", data_["CustomerID"].nunique())
print("InvoiceNo unique:", data_["InvoiceNo"].nunique())
print("StockCode unique:", data_["StockCode"].nunique())
print("Description unique:", data_["Description"].nunique())
> CustomerID unique: 4339
> InvoiceNo unique: 18536
> StockCode unique: 3665
> Description unique: 3877
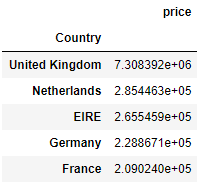
(3)このデータのカラムには、Countryがあります。このカラムを軸に、それぞれの国の購買合計金額(単位あたりの金額×数量の合計)を求め、降順にならべて、上位5つの国の結果を表示してください。
# (3)
data_["price"] = data_["Quantity"] * data_["UnitPrice"]
data_[["price", "Country"]].groupby("Country").sum().sort_values("price").iloc[-1:-6:-1]
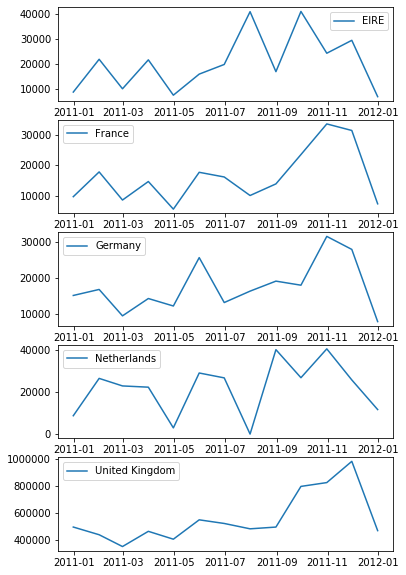
(4)上の上位5つの国について、それぞれの国の商品売り上げ(合計金額)の月別の時系列推移をグラフにしてください。ここで、グラフは分けて表示してください。
# (4)
top5countries = data_[["price", "Country"]].groupby("Country").sum().sort_values("price").iloc[-1:-6:-1].index.to_list()
data_top5countries = data_[data_["Country"].isin(top5countries)]
data_dict={}
i=0
f, axs = plt.subplots(5,1,figsize=(6,10))
for country, df in data_top5countries.groupby("Country"):
df.index = df.InvoiceDate
df_ = df.resample("M").sum()
axs[i].plot(df_.index, df_.price, label=country)
axs[i].legend(loc="best")
data_dict[country] = df
i+=1
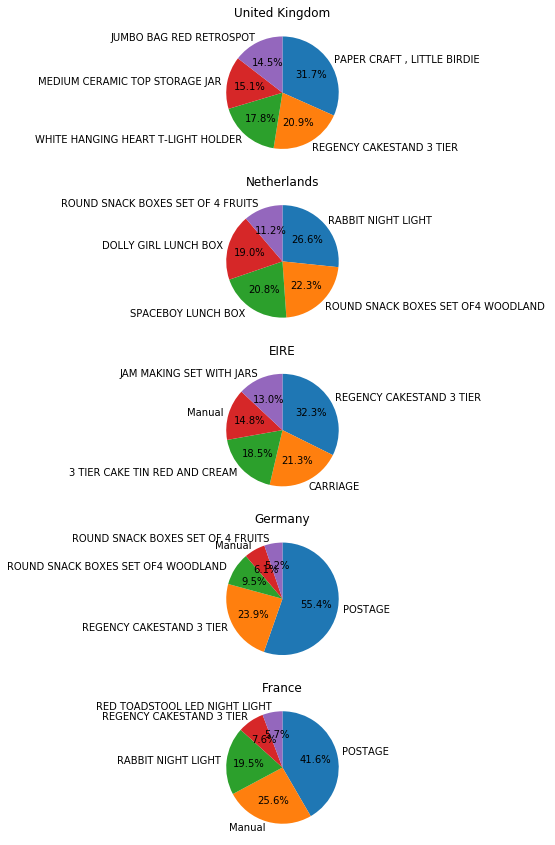
(5)上の上位5つの国について、それぞれの国における商品の売り上げTOP5の商品を抽出してください。また、それらを国ごとに円グラフにしてください。なお、商品は「Description」ベースで集計してください。
# (5)
i=0
f, axs = plt.subplots(5,1,figsize=(5,15))
for country in top5countries:
top5descriptionData = data_dict[country][["price", "Description"]].groupby("Description").sum().sort_values("price").iloc[-1:-6:-1]
print(country, "\n", top5descriptionData, "\n")
axs[i].pie(top5descriptionData["price"], labels=top5descriptionData.index.to_list(), autopct='%1.1f%%', startangle=90, counterclock=False)
axs[i].title.set_text(country)
i+=1
> United Kingdom
> price
> Description
> PAPER CRAFT , LITTLE BIRDIE 168469.60
> REGENCY CAKESTAND 3 TIER 110990.20
> WHITE HANGING HEART T-LIGHT HOLDER 94858.60
> MEDIUM CERAMIC TOP STORAGE JAR 80291.44
> JUMBO BAG RED RETROSPOT 77371.57
>
> Netherlands
> price
> Description
> RABBIT NIGHT LIGHT 9568.48
> ROUND SNACK BOXES SET OF4 WOODLAND 7991.40
> SPACEBOY LUNCH BOX 7485.60
> DOLLY GIRL LUNCH BOX 6828.60
> ROUND SNACK BOXES SET OF 4 FRUITS 4039.20
>
> EIRE
> price
> Description
> REGENCY CAKESTAND 3 TIER 7388.55
> CARRIAGE 4875.00
> 3 TIER CAKE TIN RED AND CREAM 4235.65
> Manual 3374.34
> JAM MAKING SET WITH JARS 2976.00
>
> Germany
> price
> Description
> POSTAGE 21001.00
> REGENCY CAKESTAND 3 TIER 9061.95
> ROUND SNACK BOXES SET OF4 WOODLAND 3598.95
> Manual 2296.25
> ROUND SNACK BOXES SET OF 4 FRUITS 1982.40
>
> France
> price
> Description
> POSTAGE 15454.00
> Manual 9492.37
> RABBIT NIGHT LIGHT 7234.24
> REGENCY CAKESTAND 3 TIER 2816.85
> RED TOADSTOOL LED NIGHT LIGHT 2130.15