GCIデータサイエンティスト育成講座
「GCIデータサイエンティスト育成講座」は、東京大学(松尾研究室)が開講している"実践型のデータサイエンティスト育成講座およびDeep Learning講座"で、演習パートのコンテンツがJupyterNoteBook形式で公開(CC-BY-NC-ND)されています。
Chapter6は「Pandasを使ったデータ加工処理」で、データ解析をするための強力かつ高速なデータ操作ライブラリの使い方を学習していきます。
日本語で学べる貴重で素晴らしい教材を公開いただいていることへの「いいね!」ボタンの代わりに、解いてみた解答を載せてみます。間違っているところがあったらご指摘ください。
Chapter6 Pandasを使ったデータ加工処理
6.1 Pandas
6.1.1 階層型インデックス
<練習問題 1>
次のデータに対して、Kyotoの列だけ抜き出してみましょう。
hier_data_frame1 = DataFrame(np.arange(12).reshape((3,4)) ,index = [['c','d','d'],[1,2,1]] ,columns = [['Kyoto','Nagoya','Hokkaido','Kyoto'] ,['Yellow','Yellow','Red','Blue']] ) hier_data_frame1.index.names =['key1','key2'] hier_data_frame1.columns.names =['city','color'] hier_data_frame1
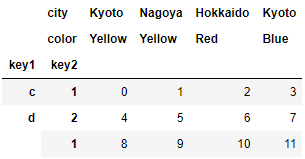
hier_data_frame1["Kyoto"]
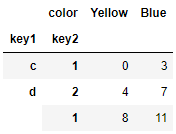
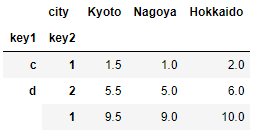
<練習問題 2>
練習問題1のデータに対して、cityをまとめて列同士の平均値を出してください。
hier_data_frame1.mean(level = "city", axis = 1)
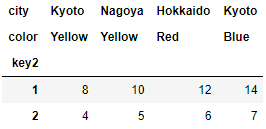
<練習問題 3>
練習問題1のデータに対して、key2ごとに行の合計値を算出してみましょう。
hier_data_frame1.sum(level = "key2")
6.1.2 データのマージ
<練習問題 1>
下記の2つのデータテーブルに対して、内部結合してみましょう。
pd.merge(attri_data_frame4, attri_data_frame5, how = "inner")
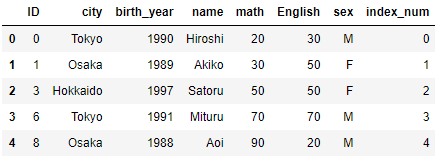
<練習問題 2>
attri_data_frame4をベースにattri_data_frame5のテーブルを外部結合してみましょう。
pd.merge(attri_data_frame4, attri_data_frame5, how = "outer")
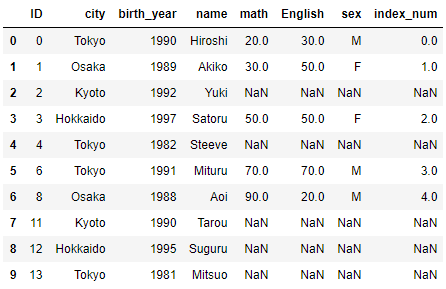
<練習問題 3>
attri_data_frame4に対して、以下のデータを縦結合してみましょう。
pd.concat([attri_data_frame4, attri_data_frame6])
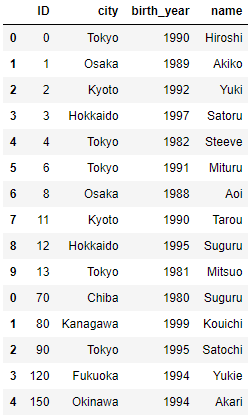
6.1.3 データの操作と変換
<練習問題 1>
以前の章で使用した「student-mat.csv」のデータを使います。ageを2倍にしたカラムを追加してみましょう。
student_data_math["2age"] = 2 * student_data_math["age"]
student_data_math[["age", "2age"]].head()
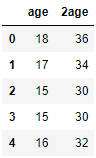
<練習問題 2>
上記と同じデータで、「absences」のカラムについて、以下の3つのビンに分けてそれぞれの人数を数えてみましょう。なお、cutのオプション設定で、デフォルトは右側が閉区間になっていますが、今回は0が入るためのright=Falseを追加してください。
# pd.cut(student_data_math.absences, absences_bins, right=False)
pd.value_counts(pd.cut(student_data_math.absences, absences_bins, right=False))
> [5, 100) 151
> [1, 5) 129
> [0, 1) 115
> Name: absences, dtype: int64
<練習問題 3>
上記と同じデータで、「absences」のカラムについて、qcutを用いて3つのビンに分けてみましょう。
# pd.qcut(student_data_math.absences, 3)
pd.value_counts(pd.qcut(student_data_math.absences, 3))
> (-0.001, 2.0] 183
> (6.0, 75.0] 115
> (2.0, 6.0] 97
> Name: absences, dtype: int64
6.1.4 データの集約とグループ演算
<練習問題 1>
先ほど使用した「student-mat.csv」を使って「student-mat.csv」を使って、pandasの集計処理してみましょう。まずは、schoolを軸にして、G1の平均点をそれぞれ求めてみましょう。
student_data_math = pd.read_csv("student-mat.csv",sep=";")
student_data_math.groupby("school")["G1"].mean()
> school
> GP 10.939828
> MS 10.673913
> Name: G1, dtype: float64
<練習問題 2>
次は、schoolと性別を軸にして、G1,G2,G3の平均点をそれぞれ求めてみましょう。
student_data_math.groupby(["school", "sex"])[["G1", "G2", "G3"]].mean()
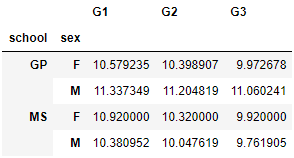
<練習問題 3>
次は、schoolと性別を軸にして、G1,G2,G3の最大値、最小値をまとめて算出してみましょう。
student_data_math.groupby(["school", "sex"])[["G1", "G2", "G3"]].agg(["max", "min"])
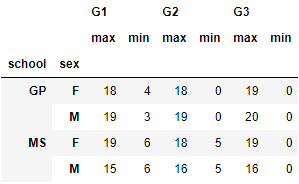
6.2 欠損データと異常値の取り扱いの基礎
6.2.1 欠損データの扱い方
<練習問題 1>
以下のデータに対して、1列でもNaNがある場合は削除し、その結果を表示してください。
sample_data_frame2.dropna()
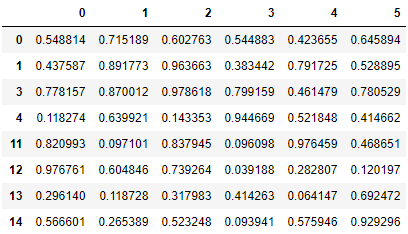
<練習問題 2>
上記で準備したデータに対して、NaNを0で埋めてください。
sample_data_frame2.fillna(0)
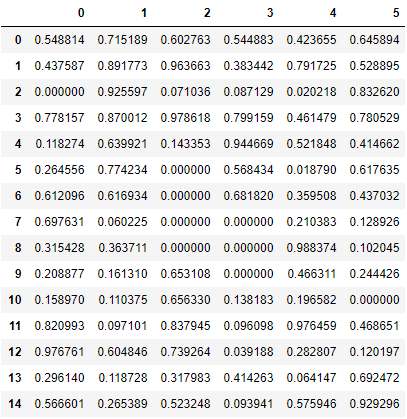
<練習問題 3>
上記で準備したデータに対して、NaNをそれぞれの列の平均値で埋めてください。
sample_data_frame2.fillna(sample_data_frame2.mean())
6.2.2 異常データの扱い方
6.3 総合問題
6.3.1 総合問題1
以前使用した「student-mat.csv」を使って、以下の問いに答えてください。(1) 上記のデータに対して、年齢×性別でG1の平均点を算出し、縦軸が年齢、横軸が性別となるような表(テーブル)を作成しましょう。
(2) (1)で表示した結果テーブルについて、NAになっている行(レコード)を全て削除した結果を表示しましょう。
student_data_math = pd.read_csv("student-mat.csv",sep=";")
# (1)
print("(1)")
print(student_data_math.groupby(["age", "sex"])["G1"].mean().unstack())
# (2)
print("\n(2)")
print(student_data_math.groupby(["age", "sex"])["G1"].mean().unstack().dropna())
> (1)
> sex F M
> age
> 15 10.052632 12.250000
> 16 10.203704 11.740000
> 17 11.103448 10.600000
> 18 10.883721 10.538462
> 19 10.642857 9.700000
> 20 15.000000 13.000000
> 21 NaN 10.000000
> 22 NaN 6.000000
>
> (2)
> sex F M
> age
> 15 10.052632 12.250000
> 16 10.203704 11.740000
> 17 11.103448 10.600000
> 18 10.883721 10.538462
> 19 10.642857 9.700000
> 20 15.000000 13.000000