はじめに
Pythonを学んだので、AIを用いた画像分類のWebアプリを作ってみることにした。色々と試している中で、転移学習に使うモデルがどれほどの差があるのか興味が出たのでWebアプリ実装に使うモデル選びとして比較してみる。
お願い
初心者故に、コードに間違いや無駄、見づらさ等があると思われるが、温かい目で見てほしい。
目的
モデル以外の部分に同じコードを使い、転移学習に使うモデルの違いを探る。
題材としては犬猫分類を扱う。一番優秀だと判断したモデルで、Webアプリの実装をしてみようと思う。
実行環境
モデル比較検討・構築
- Windows11
- GoogleColab
- python3
webアプリ化
- コマンドプロンプト
- GitHub
- GitLFS
- Flask
- Render
画像の処理
まずは学習に使う画像の処理から行っていく。
#必要なモジュール等をインポートする
import os
import cv2
import numpy as np
import tensorflow as tf
import random
from tensorflow.keras.utils import to_categorical
#乱数を固定する
def fix_seed(seed):
# random
random.seed(seed)
# Numpy
np.random.seed(seed)
# Tensorflow
tf.random.set_seed(seed)
SEED = 42
fix_seed(SEED)
# 犬・猫それぞれのファイルを取得
path_dog = os.listdir("/content/drive/My Drive/pf/画像分類/animal/dog")
path_cat = os.listdir("/content/drive/My Drive/pf/画像分類/animal/cat")
# 犬・猫それぞれの画像を250*250にリサイズしてリストに格納する
img_dog = []
img_cat = []
for i in range(len(path_dog)):
img = cv2.imread('/content/drive/My Drive/pf/画像分類/animal/dog/' + path_dog[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (250,250))
img_dog.append(img)
for i in range(len(path_cat)):
img = cv2.imread('/content/drive/My Drive/pf/画像分類/animal/cat/' + path_cat[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (250,250))
img_cat.append(img)
# 犬猫の画像データのリスト2つに統合
X = np.array(img_dog + img_cat)
# 犬を0、猫を1として目的変数を設定
y = np.array([0]*len(img_dog) + [1]*len(img_cat))
# 画像データと正解ラベルがずれないようにして、順番をランダムに入れ替える
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 学習データとテストデータに分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にする
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
今回は犬猫各500枚、各512ピクセルの正方形で統一されたデータセットを Dog vs Catから探し出して使用している。
サイズは各250ピクセルにリサイズしている。各モデルを試したいということ、またもしどのモデルも上手くいかなかった場合リソースが残っていれば調整が可能であることを理由として挙げておく。更に各250ピクセルあれば、さほど低画質でもないと考えたからだ。
今回は1000枚の画像データの内8割を学習用データに、残りの2割をバリデーションデータに指定した。
使用モデル
今回試すモデルは以下の4つにした。
- VGG16
- VGG19
- EfficientNetB0
- EfficientNetV2S
まずVGG16だが、これは転移学習を学ぶにあたって序盤で触れるモデルだと思う。その上位にあたるのがVGG19。
続いてEfficientNetB0。これは性能が良く、リソース面も優秀だと評されるEfficientNetシリーズの中で一番小さなモデルだ。
EfficientNetV2Sは、そのEfficientNetB0の上位互換と言えばそうだが、違うと言えば違う。というのも、EfficientNetシリーズはB0からB7までであり、EfficientNetシリーズの上位互換がEfficientNetV2シリーズで、S,M,Lとサイズで表記されている。同じシリーズのようで違うシリーズらしい。
EfficientNetとEfficientNetV2シリーズの層の数は、バージョンによって違う・非公開にしている等の理由から不明であった。
モデルの基本形
各モデルの精度を比較するにあたって、モデルの部分だけを入れ替えれば良いようにコーディングをした。
# 必要なモジュール類をインポートする
from tensorflow.keras.layers import Dense, Dropout, Input, Flatten
#from tensorflow.keras.applications.vgg16 import VGG16 as Vgg16
#from tensorflow.keras.applications.vgg19 import VGG19 as Vgg19
#from tensorflow.keras.applications.efficientnet_v2 import EfficientNetV2S as Efv2s
#from tensorflow.keras.applications.efficientnet import EfficientNetB0 as Efb0
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
コメントアウトしている物が、今回使う各モデルである。実行毎にインポートされてリソースを割かれることを回避しつつ、都度入力するのが手間なので一気に記述し、使う時にコメントアウトを外すことにした。
# モデルを使う準備
# 重みはimagenetで学習済の重さ
# 転移学習を行うため、全結合層はFalseを指定
# 使用する画像は250*250でrgb三層ある画像
base_model = #モデル名
(weights='imagenet', include_top=False, input_shape=(250, 250, 3))
# オリジナルのモデルを構築する
# モデルはSequentialを使う
top_model = Sequential()
# オリジナルのモデルの入力層をbase_modelからの出力に対応させる
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
# 層を追加していく
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='sigmoid'))
# base_modelとtop_modelを結合する
model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
# n層まで(から)をbase_modelの重みで学習
for layer in model.layers[n:n]:
layer.trainable = #True or False
# コンパイルする
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# モデルに学習させる
history=model.fit(X_train, y_train,
batch_size=50,
epochs=10,validation_data=(X_test, y_test))
# モデルの性能評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
かなりベーシックな転移学習のモデルだと思う。
あとはインポートするモデルのコメントアウトを外し、Base_modelにモデルを定義すれば、モデルBase_modelが完成する。
全体のモデルを完成させるには、
for layer in model.layers[n:n]:
layer.trainable = #True or False
の部分を定義する必要がある。
[]の中身については、今回はBase_modelとtop_modelで区切れるようにした。
例えば、VGG16モデルでVGG16モデルの重みをモデル全体に適用したいときは[:-1]にして、layer.trainable = Falseにした。逆にtop_model部分では新たに重みを学習してもらおうとするならば、[-4:]で、layer.trainable = Trueとなる。
ユニット数とドロップアウトについては、今回はGoogleColabの自動生成をそのまま使った。batch_sizeについては、VGG16モデルの段階でいくつか入れてみて、今回は50を使うことにした。オプティマイザーについても基本的には同様だが、Adamを使ってみたところ精度が落ちたので、今回はSGDを使うことにした。
また、early_stopping = EarlyStopping(monitor='val_loss', patience=5)も検討した。何百何千エポック行うあるいは1エポックにとても時間がかかる場合は導入しただろう。
今回も最初はエポック数を100に指定し、EarlyStoppingを導入したが、早い段階でTest accuracyが上昇し、Test lossも減少していた(学習が収束している様子だった)ため使わなかった。
もしかしてfor文
上記を1回1回モデルを変更しながら実行していこうと思っていたのだが、ふと、変更しながら繰り返し行う=for文が使えるという可能性に気づき、コードを変更した。
# 必要なモジュール類をインポートする
from tensorflow.keras.layers import Dense, Dropout, Input, Flatten
from tensorflow.keras.applications.vgg16 import VGG16 as Vgg16
from tensorflow.keras.applications.vgg19 import VGG19 as Vgg19
from tensorflow.keras.applications.efficientnet_v2 import EfficientNetV2S as Efv2s
from tensorflow.keras.applications.efficientnet import EfficientNetB0 as Efb0
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# 完成したモデルを格納するリスト
models = []
# 学習履歴を格納するリスト
histories = []
# モデルの性能評価を格納するリスト
scores = []
# 各モデルを使う準備
# 使用モデルをリストに格納
base_models = [Vgg16, Vgg19, Efb0, Efv2s]
# 重みはimagenetで学習済の重さ
# 転移学習を行うため、全結合層はFalseを指定
# 使用する画像は250*250でrgb三層ある画像
for base_model in base_models:
base_model = base_model(weights='imagenet', include_top=False, input_shape=(250,250,3))
# オリジナルのモデルを構築する
# モデルはSequentialを使う
top_model = Sequential()
# オリジナルのモデルの入力層をbase_modelからの出力に対応させる
input_layer = Input(shape=base_model.output_shape[1:])
top_model.add(Flatten())
# 層を追加していく
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='sigmoid'))
# base_modelとtop_modelを結合する
model = Model(inputs=base_model.input, outputs=top_model(base_model.output))
models.append(model)
# 最後までbase_modelの重みで学習をさせる
for model in models:
for layer in model.layers[:-1]:
layer.trainable=False
# コンパイルする
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# モデルに学習させる
history=model.fit(X_train, y_train,
batch_size=50,
epochs=10,validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, verbose=1)
# 学習履歴をリストに保存
histories.append(history)
# モデルの性能評価をリストに保存
scores.append(score)
同じような要領で、比較用のグラフの描画も行った。コードについては割愛する。
各モデルの比較
layer.trainableによる差
通常、VGGシリーズはlayer.trainable=Trueとし、EfficientNetシリーズEfficientNetV2シリーズはlayer.trainable=Falseにするらしい。
これはそれぞれのモデルの性能や複雑さによるもので、VGGシリーズは優秀で転移学習によく用いられるものの、やりたいことに合わせた微調整をすることでより本領を発揮でき、逆にEfficientNetシリーズとEfficientNetV2シリーズは微調整をする必要もない(層の数も明かされていない等もあるだろうが)程に様々なことに対して対応ができるようだ。
私なりの理解なので、間違えているかもしれません
accuracyとloss
さて、各モデルをlayer.trainable=Trueとした場合と、layer.trainable=Falseとした場合、合計8パターンの予測精度と損失関数の比較は以下の通りだ。
layer.trainable=True(オリジナルの部分に限り)
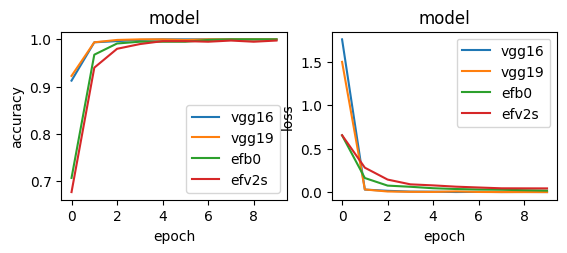
vgg16 Test loss: 0.0009509961819276214
vgg16 Test accuracy: 1.0
vgg19 Test loss: 0.005847594700753689
vgg19 Test accuracy: 1.0
efvb0 Test loss: 0.01203195471316576
efvb0 Test accuracy: 0.9950000047683716
efv2s Test loss: 0.02696034125983715
efv2s Test accuracy: 1.0
まず、全てのモデルで最終的にaccuracyは1.0に近い結果となった。1.0にわずかに届かなかったEfficientNetB0は、損失関数の改善はまだ見られていたため、epock数を増やすと変わったかもしれない。EfficientNetV2Sは1.0にはなっているものの、最後の最後にどうにか到達したような形だ。逆にVGGシリーズ2つは序盤から安定して1.0をキープしていた。
損失関数に関しては、VGGシリーズが優位に見える。途中経過も特に大きな懸念点は見当たらなかった。
layer.trainable=False
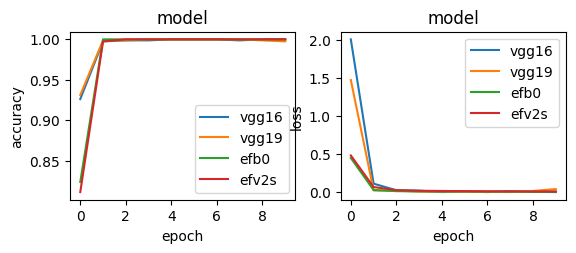
vgg16 Test loss: 1.0945828271546887e-10
vgg16 Test accuracy: 1.0
vgg19 Test loss: 0.009597592055797577
vgg19 Test accuracy: 1.0
efvb0 Test loss: 0.002815577434375882
efvb0 Test accuracy: 1.0
efv2s Test loss: 0.002981010125949979
efv2s Test accuracy: 1.0
まず、全てのモデルで最終的にaccuracyは1.0となった。ただ、グラフ終盤を見るとVGG19で過学習が起きていそうだ。
損失関数に関しても、VGG19で過学習が疑われる。また、微細すぎてグラフではわからないが、最終的な数値としてはかなり良い結果を出しているVGG16だが、微細な中でも不安定な変化がみられていた。
最後まで安定して学習していたのは、EfficientNetB0とEfficientNetV2Sの二つということになる。
上記を踏まえ、VGGシリーズにはTrueを、EfficientNet・EfficientNetV2シリーズにはFalseをというのは、確かにそうなのかもしれないと感じた。特に損失関数の違いがわかりやすいだろう。
データセット以外のデータへの対応は?
ところで、今回のデータセットは犬猫ともに似たような種類が多い印象を受けた。データセット内の犬猫全てをごちゃまぜにして、10mほど先から見たらどちらだかわからなくなるような物というような感覚だ。
色や模様が類似した犬猫を(ほぼ100%)分類できると考えられるわけだが、そもそもの犬なのか猫なのかという問題に対しては、様々な犬種や条件に対して答えられるのだろうか。
その検証のために、今回は犬と猫でネットの画像検索を行い、人力ながらもある程度無作為に10枚ずつの犬と猫の画像をテストデータとして選出した。作為的に行ったのは、複数匹が写っている物を含めたことだ。これは学習データにも含まれていたため、テストデータとしても入れておくべきだろうとの考えの下だ。
結果として、テストデータでも100%正解できたのは、layer.trainable = FalseのEfficientNetV2Sだけだったが、他のモデルが間違えている物を見ていると、なんとなく共通点が見えた。
まず犬と猫で言えば、犬の方が間違えやすい。何ならlayer.trainable=TrueのVGGシリーズは、猫は完璧に分類できていた。
更に間違えやすい傾向としては、左斜め45度程から撮影されたドーベルマンらしき犬が吠えている写真と、ポメラニアンの顔アップ画像の二つは高確率で誤判定をしていた。二つの共通点と言えば耳が立っているくらいなもので、何をもって間違えたのかはわからなかい。ただ、この二つすらクリアしたlayer.trainable = FalseのEfficientNetV2Sはより厳密に学習されていると考えられる。
Best Modelは?
今回の目的の、違いを探り、一番良いと判断したモデルでWebアプリを実装してみるということを果たすべく、一番良いモデルがどれなのかを判断していこうと思う。
比較項目
- accuracy
- loss
- テストデータに対する正答率
- モデルのサイズ
上記4点に絞って今回のBest Modelを決めたいと思う。
-
accuracy
まず、accuracyについては、layer.trainable=TrueのEfficientNetB0が若干劣っているものの、8種全てほぼほぼ1ある状態だ。逆にlayer.trainable=FalseのVGG19は1.0と出てはいるものの、終盤に落ち込みが見られ、過学習が疑われる。 -
loss(損失関数)
続いてloss、損失関数についてだが、数値だけを見れば、layer.trainable=FalseのVGG16が圧倒的だ。しかし前述の通り、微細ながらも不安定さが見られたため、数値だけで優秀だと決断するのは早計かもしれない。Trueの方が安定感があり、数値も2番目に良いので、VGG16で採用するとしたらlayer.trainable=Trueの方にしたいと私は思う。
そしてEfficientNetB0とEfficientNetV2Sについては、layer.trainable=Falseで安定して減少を続けていた所を評価したい。 -
テストデータに対する正答率
これに関してはlayer.trainable=FalseのEfficientNetV2Sで間違いない。様々な画像に対応できる可能性が考えられる。ただ、同EfficientNetB0も劣ってはいなかった。
VGGシリーズはというと、どうも犬に対する弱さを感じる結果となっていた。 -
モデルのサイズ
最後にモデルのサイズだが、これがどう影響するかというと、アプリケーション化する際の手間や進行速度、アプリケーション化した後の動作のスピードに関わってくる。大規模なモデルであれば、精度や対象等を増やし、より汎用性の高い良いアプリケーション開発に役立てることができるが、その分そのアプリを動かすことができる環境が限られてくる。
例えば、古いパソコンやスマホ、容量の少ないそれらでいわゆる重たいゲームや重たいアプリを使おうとしたとする。先に進まない・フリーズするなんてことが容易に考えられるだろう。
なので、ほぼ同等の性能を持っているのならば小さなモデルの方が様々な環境での動作が見込めるという点で、今回の場合はサイズの小さな物を優秀と評価したいと思う。
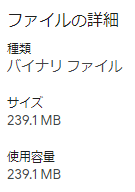
モデルのh5ファイルのサイズを見てみよう。
- EfficientNetV2S
- VGG19
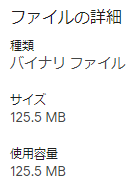
それぞれのお仲間の、大きい方のモデルで比較してみた。
ちなみにひとつの目安として覚えておいて損はないかもしれないのが、GitHubがストレートに受け付けてくれるファイルの限度は100Mb50Mbなので、それを超えるこれらはGitLFSを使用しなければならない。
Best Model発表
上記三点での比較検討の末、今回の条件下でのBest Modelを私なりに選んでみた。
結果……
最優秀賞
EfficientNetB0(layer.trainable=False)
では上記の結果とした理由を述べていきたい。
VGG16の損失関数の小ささが目立つが、EfficientNetB0(False)はVGG16に次いで3番目に小さい。そして安定した減少を続けている。VGG16の不安定さや、テストデータに対する正答率を比較すると、EfficientNetB0に軍配が上がった。
そしてテストデータに対する正答率も、なんだかんだ19/20で正解している。ただ、正答率を考えると20/20のEfficientNetV2Sではないかとなるだろう。ここで気にしたのが、モデルのサイズだ。ほぼほぼ同じ性能であれば、今後微調整する時や実装した時の実行速度や動作のスムーズさを優先したい。
ただ、商用であったり、医学的であったりする場合は、(もっと多くの調整や評価をすることは大前提として)EfficientNetV2Sを採用するのではないかとも思う。今回は個人の興味の範疇で、Webアプリ実装の練習を兼ねている物なので、動作の軽さを優先した。
まとめ
今回は、全く同じ条件下でどのモデルがどの項目でどのように優位に立つのかを検証した。
結果として今回、(私の基準では)EfficientNetB0だったわけだが、ユニット数や層の種類や数、その他チューニング次第ではVGG16が上回る可能性はある。VGGシリーズはファイルサイズの小ささとしては優位にある。モデルを構築している際のリソース的にも、実装した時の動作を検討してもVGGシリーズのコンパクトさは嬉しい。
ただ、簡単な題材でサクサクっと作ってみてこれだけの差が出るということは、複雑な課題になれば、転移学習におけるモデル選びがより重要になるということを示唆していると考えられる。更に良い悪いの指標は一つではなく、総合的に判断する必要がある。一般的に優秀とされている物、新しい物が良いとは限らないだろう。今回EfficientNetV2Sを選ばなかったことにも通ずる。
私以外の人ならEfficientNetB0を選ばなかったかもしれない。
転移学習といえばまずVGGシリーズと私は考えてしまうが、VGGシリーズ・EfficientNetシリーズ・EfficientNetV2シリーズに限らず、様々な候補を持てるだけの知識を得たいものだ。もっと言えば、転移学習ではなくイチから自分でモデルの構築を行って比較もしてみたい。
(ちなみにだが、EfficientNetV2相当のサイズのEfficientNetシリーズのモデルは、B2らしいので、この二つの比較もしてみたい。)
また、今回のテストデータは犬猫計20枚で行った結果で一応は95%の正答率を誇ったEfficientNetB0を元にしたWebアプリを実装する。20枚では95%の正答率だが、100枚1000枚と試したら、きっとどこかで間違えるだろう。
今回試したほぼ全てのモデルに言えることなのだが、過学習を起こしていないかどうかという懸念もある。accuracyが序盤から1.0を出している中で、実際にaccuracyが下がったもの、損失関数が不安定・途中で上がったもの等があるし、損失関数が低下し続けているからと言って、過学習が起きていないとも限らない。
95%という数字は、実装してみたら全く変わる可能性がある。そのギャップをいかに埋めていくかというのも難しそうだ。
今回の実験を元に学んだこと、単純にfor文を回すだけのようで、インデント下げを間違えると(実行できてしまうが)全くうまくいかなくなった等といった経験を元に、更にプログラミングに対する学びを深めていきたい。
このアプリを元にHTMLやCSSの工夫もしていきたいと思うし、実はまだWebアプリ化が完了しておらず、デプロイで引っかかている(ローカルでは動作確認済)のでそのあたりも学びを深め、実践で使えるようになりたい。