http://scikit-learn.org/0.18/modules/outlier_detection.html を google 翻訳した
scikit-learn 0.18 ユーザーガイド 2. 教師なし学習 より
2.7. 新規性と外れ値の検出
多くのアプリケーションでは、新しい観測値が既存の観測値と同じ分布(inlier)に属しているのか、異なるもの(outlier)であるのかを判断できる必要があります。多くの場合、この機能は実際のデータセットを消去するために使用されます。 2つの重要な区別がなされなければならない:
-
新規性検出:
- トレーニングデータは外れ値によって汚染されていないため、新しい観測で異常を検出することに関心があります。
-
外れ値検出:
- 訓練データには異常値が含まれており、逸脱した観測値を無視して訓練データの中央モードに適合する必要があります。
scikit-learnプロジェクトは、新規性または外れ値の検出の両方に使用できる一連の機械学習ツールを提供します。この戦略は、データから教師なしで学習するオブジェクトで実装されます。
estimator.fit(X_train)
新しい観測値を、予測方法を使用して、 outlier または inlier としてソートすることができます。
estimator.predict(X_train)
inlier は 1 とラベル付けされ、 outlier は-1とラベル付けされる。
2.7.1. 新規性の検出
$p$ 個の特徴量によって記述された同じ分布でなる $n$ 個の観測のデータセットを考える。ここで、そのデータセットにもう1つの観測を追加することを検討してください。新しい観測は他の観測とはそれほど違うのですか? (すなわち、それは同じ分布から来るのだろうか)それとも逆に、他のものと似ているので、元の観測と区別できないのだろうか?これは、新規性検出ツールおよび方法によって対処される問題である。
一般に、それは、 $p$ 次元空間を埋め込むことでプロットされた、初期観測分布の輪郭を画定する、粗い、密接な境界を学習しようとしているところである。次に、さらなる観測がフロンティア区切り部分空間内にある場合、それらは最初の観測と同じ集団からのものとみなされる。さもなければ、彼らがフロンティアの外に横たわっているならば、私たちは、彼らが私たちの評価においてある程度の自信を持って異常であると言うことができます。
1クラスSVMは、Schölkopfらによって導入されました。その目的のために、 svm.OneClassSVM オブジェクトの Support Vector Machines モジュールで実装されています。フロンティアを定義するには、カーネルとスカラパラメータの選択が必要です。 RBFカーネルは通常、帯域幅パラメータを設定する正確な式やアルゴリズムは存在しませんが、選択されます。これはscikit-learn実装のデフォルトです。 One-Class SVMのマージンとも呼ばれる $\nu$ パラメータは、フロンティアの外に新しいが定期的な観測を見つける確率に相当します。
- 参考文献:
- 高次元分布のサポートの推定 Schölkopf、Bernhard、et al。 ニューラルコンピューティング13.7(2001):1443-1471。
- 例:
- svm.OneClassSVM オブジェクトによっていくつかのデータの周りで学んだフロンティアを視覚化するために、非線形カーネル(RBF)を持つ1クラスSVM を参照してください。
2.7.2. 外れ値検出
外れ値の検出は、通常の観測のコアをいくつかの汚染されたもの(「異常値」と呼ばれる)から分離するという目的で新規性の検出に似ています。しかし、外れ値の検出の場合、我々は、任意のツールを訓練するために使用することができる定期的な観測の集団を表すきれいなデータセットを有していない。
2.7.2.1. 楕円形の封筒を取り付ける
外れ値検出を実行する一般的な方法の1つは、通常のデータが既知の分布(例えば、データはガウス分布)から来ると仮定することである。この仮定から、我々は一般的にデータの「形状」を定義しようとし、外ずれ値をフィット形状から十分に離れた観測値として定義することができます。
scikit-learnはオブジェクトの共分散を提供します。楕円形のエンベロープは、データへの堅牢な共分散推定値に適合し、中央モード以外の点を無視して中央データポイントに楕円をフィットさせます。
例えば、 inlier データがガウス分布であると仮定すると、inlier 位置および共分散を堅牢な方法で(すなわち outlier の影響を受けずに)推定する。この見積もりから得られたマハラノビスの距離を用いて外来性の尺度を導出する。この戦略を以下に示します。
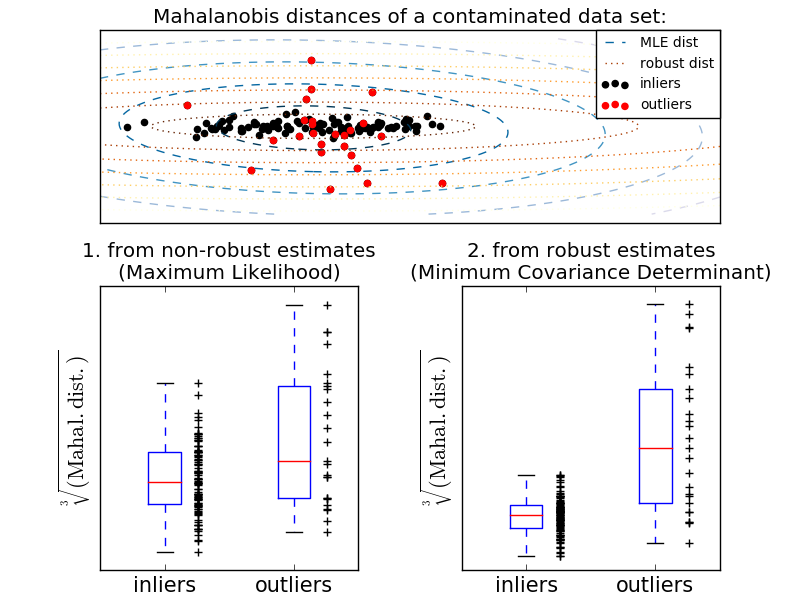
- 例:
- 観測の外れの程度を評価するために、標準( covariance.EmpiricalCovariance )またはロバストな推定( covariance.MinCovDet )の位置と共分散の使用の違いの説明には、ロバスト共分散推定とマハラノビス距離の関連性 を参照してください。
- 参考文献:
- [RD1999] Rousseeuw、P.J.、Van Driessen、K. "最小共分散行列式推定器の高速アルゴリズム" Technometrics 41(3)、212(1999)
2.7.2.2. アイソレーションフォレスト
高次元のデータセットで外れ値を検出する効率的な方法の1つは、ランダムフォレストを使用することです。 ensemble.IsolationForest は、ランダムに特徴を選択し、選択した特徴の最大値と最小値の間の分割値をランダムに選択することによって、観測値を「分離」します。
再帰的分割はツリー構造で表すことができるので、サンプルを分離するために必要な分割の数は、ルートノードから終端ノードまでのパス長に相当します。
このようなランダムツリーフォレスト上で平均化されたこのパスの長さは、正常性と判断機能の尺度です。
ランダム分割は、異常に対して顕著に短いパスを生成します。したがって、ランダムツリーフォレストが、特定のサンプルに対してより短いパス長を総称的に生成する場合、それらは異常である可能性が高い。
この戦略を以下に示します。
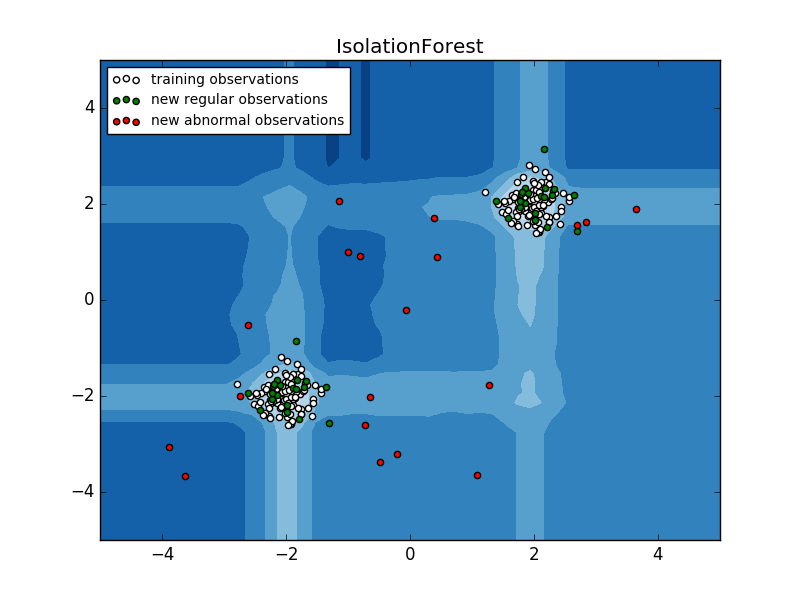
- 例:
- IsolationForestの使用例については、 IsolationForestの例 を参照してください。
- いくつかの方法による異常値検出 を参照してください。 ensemble.IsolationForest と svm.OneClassSVM (外れ値検出方法のように調整されています)と、 covariance.MinCovDet を使用した共分散ベースの外れ値検出を比較します。
- 参考文献:
- [LTZ2008] Liu、Fei Tony、Ting、Kai Ming、Zhou、Zhi-Hua。 "分離森林"データマイニング、2008. ICDM'08。第8回IEEE国際会議
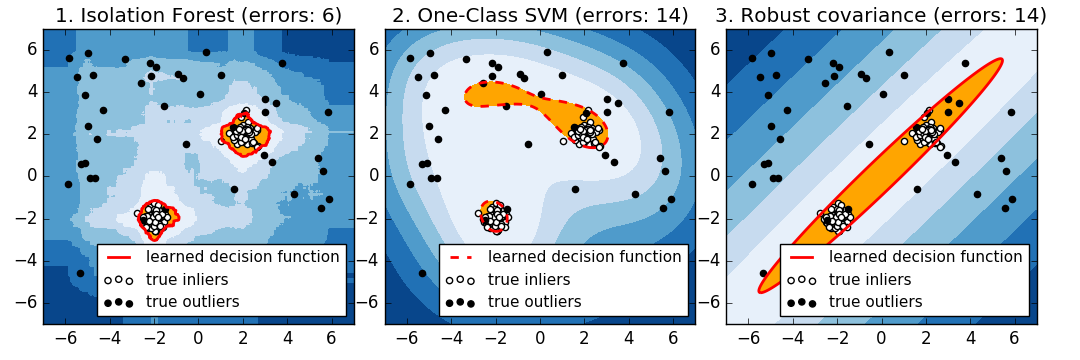
2.7.2.3. 1クラスSVM対楕円エンベロープ対アイソレーションフォレスト
厳密に言えば、1クラスSVMは外れ値検出方法ではなく、新規検出方法である:その訓練セットは、外れ値によって適合されるので、その訓練セットが汚染されるべきではない。つまり、高次元での外れ値の検出、または内在するデータの分布に関する仮定がないことは非常に困難であり、One-class SVMはこれらの状況で有用な結果をもたらします。
以下の例は、共分散のパフォーマンスがどのようにデータがより少なく、より少ないように劣化するかを示しています。
svm.OneClassSVM は、複数のモードとアンサンブルを持つデータでうまく機能します。 IsolationForest は、あらゆる場合にうまく機能します。
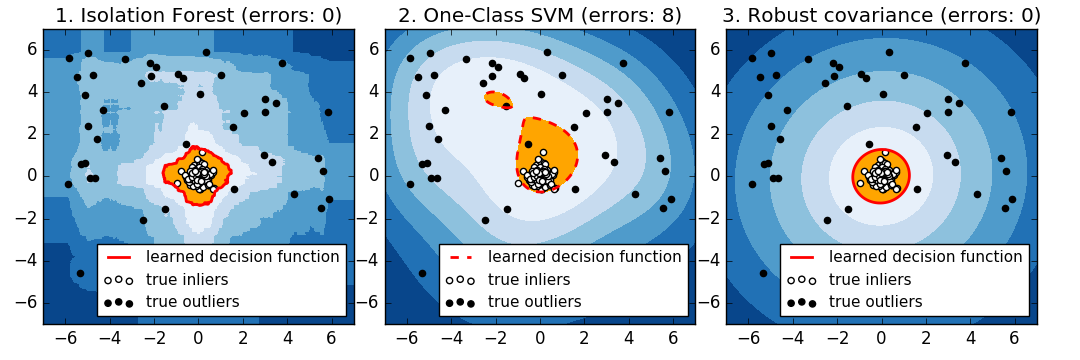
1クラスSVMアプローチと楕円エンベロープの比較
よく芯出しされた楕円形のinlierモードの場合、 svm.OneClassSVM はinlier集団の回転対称性の恩恵を受けることができません。加えて、トレーニングセットに存在する outlier に少しだけ適合します。反対に、共分散をフィッティングすることに基づく covariance.EllipticEnvelope は inlier 分布によく似た楕円を学習します。 ensemble.IsolationForest も同様に機能します。
inlier分布がバイモーダルになると、EllipticEnvelopeはinliersにうまく適合しません。 しかし、 covariance.EllipticEnvelope と svm.OneClassSVM の両方で、2つのモードを検出するのが難しく、 svm.OneClassSVM がオーバーライドする傾向があることがわかります。inliers のモデルがないため、一部のアウトライアがクラスタ化された領域がインライヤとして解釈されます。
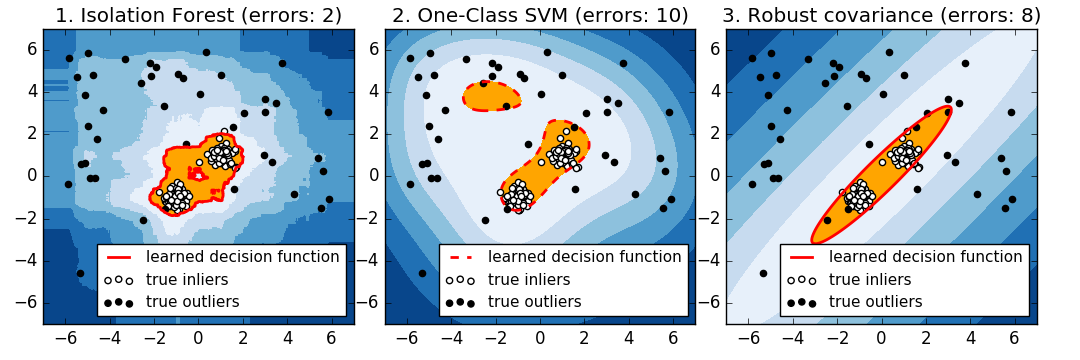
inlier分布が強くガウス分布でない場合、 svm.OneClassSVM は ensemble.IsolationForest と同様に妥当な近似値を復元できますが、 covariance.EllipticEnvelope は完全に失敗します。
- 例:
- IsolationForestの使用例については、 IsolationForestの例 を参照してください。
- いくつかの方法による異常値検出 を参照してください。 ensemble.IsolationForest と svm.OneClassSVM (外れ値検出方法のように調整されています)と、 covariance.MinCovDet を使用した共分散ベースの外れ値検出を比較します。
scikit-learn 0.18 ユーザーガイド 2. 教師なし学習 より
©2010 - 2016、scikit-learn developers(BSDライセンス)。