はじめに
経路探索エンジンの研究開発をしているM.Yです。
ナビタイムジャパンでは、2019/07/30、自転車NAVITIMEへ向けてGPUによる探索エンジンをリリースしました。リリース時点でP2インスタンスを利用していましたが、2019/09/20に、NDIVIA GPUの最新アーキテクチャであるTuringを採用したAWS EC2インスタンスG4がローンチされました。
そこで早速パフォーマンスを調べたのですが、他のGPU搭載EC2インスタンスに比べて圧倒的にコスパが良かったため、すぐにG4インスタンスへ切り替えました。その際に行った他のGPUインスタンスとの性能とコストの比較結果を紹介します。
G4インスタンスについて
NVIDIAの最新アーキテクチャであるTuringを採用したGPU、Tesla T4を搭載したEC2インスタンスです。2019年3月に開催されたGTC 20191にて、AWSからインスタンスの提供が発表され、2019年9月に利用可能になりました。
スペックと各インスタンスのオンデマンド料金は以下の表のとおりです。最新アーキテクチャにも関わらず、G4インスタンスのコストの安さが際立っています。
| アーキテクチャ | CUDAコア数 | デバイスメモリ | オンデマンド料金 | |
|---|---|---|---|---|
| p2.xlarge | Kepler | 2496 | 12GB | 1.542 $/hr |
| p3.2xlarge | Volta | 5120 | 16GB | 4.194 $/hr |
| g4dn.xlarge | Turing | 2560 | 16GB | 0.71 $/hr |
ベンチマーク
測定条件
GPUを利用した自転車ネットワーク探索エンジンで探索距離毎(6~1400km)にアーキテクチャの比較を行いました。
比較したのは上述した各アーキテクチャのインスタンスです。
測定結果
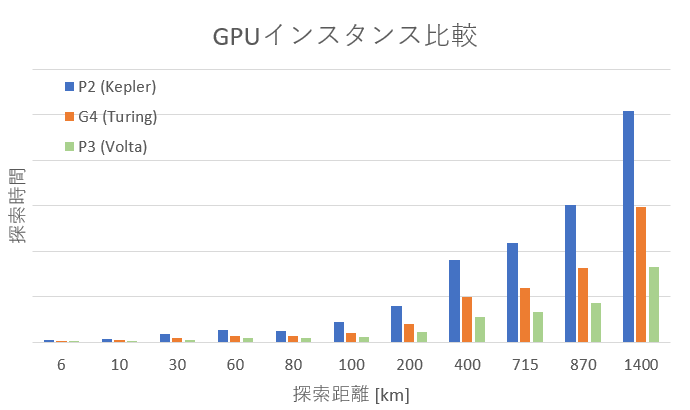
こちらが絶対値での比較です。
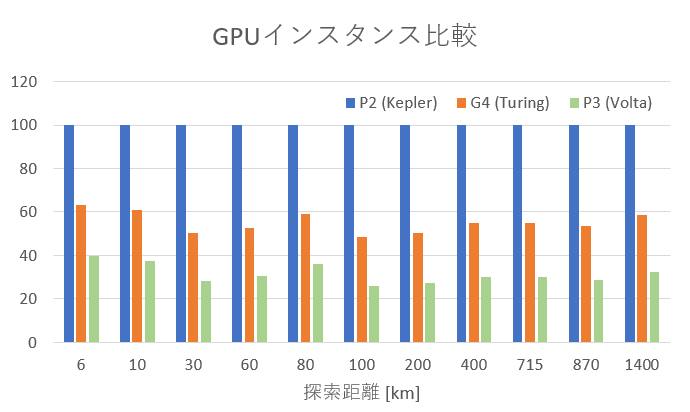
こちらがP2の探索時間を100としたときの各アーキテクチャの処理時間の比率です。
P3のパフォーマンスは凄まじく、P2と比較して平均3.17倍の高速化となりました。しかしコストがP2と比較すると2.71倍と相応のコストがかかります。
G4もP2とCUDAコア自体の数はほとんど変わらないにも関わらず、P2と比較して平均1.81倍の高速化ができています。しかもコストが0.46倍となります。
つまり、P3はコストをかけて速くしているのと等価ですが、G4はコストが安くなるのに速くなりました。
| アーキテクチャ | P2との速度差 | P2とのコスト差 | P2とのコストパフォーマンス | |
|---|---|---|---|---|
| p3.2xlarge | Volta | 3.17 | 2.71 | 1.17 |
| g4dn.xlarge | Turing | 1.81 | 0.46 | 3.93 |
まとめ
P2インスタンス使っている方はG4インスタンスの利用を積極的に検討しましょう。
今回の比較はGPGPUでのパフォーマンス比較でしたが、G4インスタンスでは前述したとおりTuringアーキテクチャであるTesla T4を利用しており、このGPUには機械学習計算に特化したプロセッサであるTensor Coreも搭載されているため、P2インスタンスと比較すると機械学習でのパフォーマンスも確実に上がっていると思いますので利用を検討する価値があると思います。
-
サンノゼで毎年開催されているNVIDIAのテクノロジーカンファレンス ↩