はじめに
ナビタイムジャパンでオンプレからパブリッククラウドへのシステム移行をメインで行っているしみけんと申します。
弊社では、全文検索にSolrとElasticSearchを利用しています。ElasticSearchはAWSのマネージドサービスであるESSをメインで利用していますが、Solrに関しましては今年の5月まではEC2インスタンス固定台数で運用を行っていました。この記事では、そのような状態から、Solrをオートスケールできるように再構築したお話をさせていただければと思います。

オートスケールさせる動機
EC2インスタンスの固定台数での運用では、2つの課題が抱え込むことになりました。
- 突発的なアクセス増が比較的多く見られるが、起こった場合にスケールできないため輻輳のリスクが高かった
- 台風や雪などで公共交通機関の運行状況が変化した場合には、迂回ルートの検索などでアクセスが増えてしまう
- 台数を増やす際に決して小さくない運用コストが発生する
- インフラチームによるEC2インスタンス作成と検索チームによる手作業によって初期構築が行われていた
- GWなどアクセス増が見込まれるたびに台数増設を行う必要性があった
スケールさせる基盤の選択
現在、SolrはAWSのマネージドKubernetesであるEKSとGCPのマネージドKubernetesであるGKEの両方で利用しています。
最初はGKEの方から運用が始まりました。構築当時に自分はいなかったので、一部推測も入りますが、おそらくKubernetesの持つ下記の機能がSolrを運用する上でマッチしたのだと思います。
- initContainer
- Persistent Volume Claim
- labelベースのルーティング
AmazonECSの方が社内ではメインストリームでしたが、AmazonECSではなくGKE(というよりKubernetes)が初めてのSolrコンテナ事例となったのは、インデックスデータをどう扱うか、どのようにBlue/Green Deployを行うかについて適切なソリューションがあったからであるはずです。
GKEでの実績があったためKubernetesのリソースを再活用できるAmazonEKSというプラットフォーム選択がなされました。
インデックスデータをどう扱うか
Solrの肝となるのはインデックスデータだと思います。インデックスデータはコアによって容量が違いますので一概には言えませんが、GB単位の大きなデータとなることが多いです。通常EC2での運用では、masterの役割を果たすEC2インスタンスがコンバート処理を行い、インデックスデータをslaveに直接配置しています。配置した後に、tomcatのプロセスを起動させています。
オートスケールを行う上で、「どこからデータを持ってくるか」や「Solrの起動開始をどう制御するか」を考えなくてはいけません。
「どこからデータを持ってくるか」ですが、単純に考えればS3やGCSなどのオブジェクトストレージがまっさきに思い当たります。コンバータの処理もスッキリしそうです。しかしながら、先程も言及しましたように、弊社の運用しているインデックスデータの中にはサイズが非常に多くなるものもあり、ダウンロード時間と解凍時間が長くなりすぎてしまいます。ものによっては、展開までに15分かかってしまい、スケールが追いつきません。
弊社では、Facebook社製のZstandardを利用して、ダウンロードと解凍時間をおおよそ半分にすることが出来ました。展開速度は他の通常のアプリケーションに比べると遅いですが十分活用できるレベルとなりました。
「Solrの起動開始をどう制御するか」についての検討も必要です。ダウンロードが終わった後に、Solrのプロセスを起動させる必要性があります。コンテナオーケストレーションエンジンでは、デプロイの最小単位をTaskであったりpodと定義付けています。何のオプションも使わなければ、Task内(もしくはpod内)の各コンテナは非同期に起動を行います。
KubernetesのinitContainerを使うことによって、初期化処理をpodの起動時にまとめることが出来るようになります。勿論、solrのコンテナのエントリポイントをShellにして最初にダウンロードを走らせるでも良かったのですが、責務の切り分けが出来ないですし、イメージサイズも大きくなるのでなるべく避けるべきでしょう。GCPでの構築を始めた2017年当時のAmazonECSでは、このようなことは出来ませんでした。現在は、docker-composeでもおなじみのdepends_onオプションが追加され、同じような動きをさせることが出来ます。
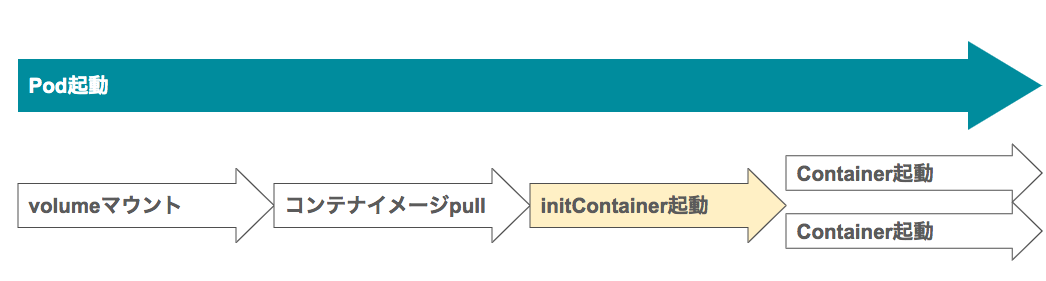
圧縮の部分で少し話が逸れましたが、当時はKubernetesを使うことでコンテナをデータダウンロードとアプリケーションで正しく分離できるためだったと言えます。
また、最終的には使用していないのですが、Persistent Volume Claim(以後PVC)も一つの大きな魅力だったと思います。インデックスデータのサイズに適したデータボリュームをインスタンスにアタッチする必要があります。インスタンスに複数pod/複数コアをスケジューリングする場合には、動的にボリュームのサイズを変更する必要があります。PVCもKubernetesの特徴的な機能になりますが、各podでどのサイズのボリュームが欲しいかを宣言してアタッチする機能となります。
おそらく当時PVCは扱うのが難しく、1インスタンスに1pod、コアごとにノードプールを作成することとなりました。
Blue/Green Deployをどう実現するか
EC2インスタンス固定台数でのデプロイ方法はBlue/Green Deployで、この部分の振る舞いは変えずにコンテナ化を図りました。
Kubernetesではラベルベースでルーティングが行われます。一方AmazonECSでは、Serviceと紐づくターゲットグループをどのALBのバックエンドにするかでルーティングを変更できるものと思います。両者とも比較的簡単にBlue/Green Deployが実行できますが、当時のECSではカナリーデプロイの実現や切替時の安全なコネクションドレイニングの観点では少しむずかしいのではという観点もあり(参考)、ラベルベースで比較的柔軟にデプロイできるKubernetesでコンテナ化を行ったのだと思います。
kubectlを使ったシェルスクリプトで以降はデプロイを行うことになりました。
技術的な理由としては、このようにGKEというプラットフォーム選択がなされたと思います。この他、新しい環境を1から作る上で検証などが非常にやりやすかったのが大きいとは思います。
運用の中で出てきた課題
可観測性の必要性
コンテナにすることで今までに起こらなかった(もしくは気づけなかった)異常に検知するようになりました。
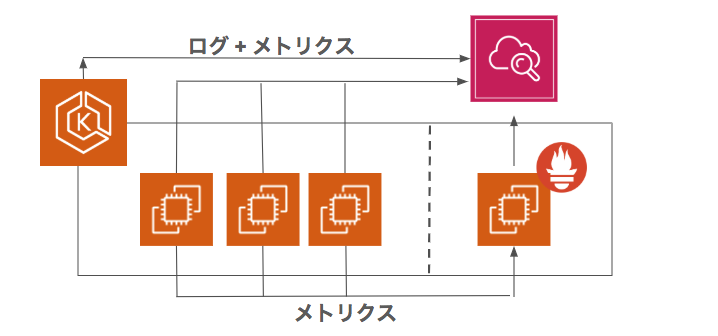
ですが、それらの事象が何を起因にして起こっているかの切り分けは難しくなりました。インスタンスとアプリケーションとの間に、コンテナを動かすレイヤーが入ってきたからです。インスタンスだけでなく、コンテナごとのメトリクスを取ることが必要になってきました。GCP/AWS環境でどちらもPrometheusとGrafanaの構成を入れていますが、更にELBのメトリクスも合わせて一覧したいという要望もあり、AWS環境ではContainer Insightを活用したダッシュボードを作成し監視を行っています。
デプロイ基盤の必要性
AWSでもSolrをスケールするように作りたいと去年の秋くらいから話題に上がるようになりました。AmazonECSで構築を行うか検討し始めていたところで、AmazonEKSの来日が決まりました(ヤァ!ヤァ!ヤァ!)のでEKSで構築をはじめました。
GCP環境でデプロイはシェルスクリプトを利用していますが、AWS環境で同じことをするのは管理しづらくなりますし、今後他のクラウドでKubernetes環境を運用することを考えると避けたい事態でした。また、現状シェルスクリプトのデプロイでは、どこで実行されているか知らない人が多く、エラーになっても追いづらい状況がありました。
マルチクラウドに対してデプロイ出来る共通基盤の必要性を感じていました。
下記の条件がデプロイツールにおいては必要であったため、ツール選択においてはSpinnakerを採用いたしました。
- クラウドプロバイダの違いが抽象化されていること(= マルチクラウドへのデプロイ可能)
- B to B 事業もあるため Continuous Deployment で共通化するのは難しい
- 豊富なデプロイメント戦略が取れること
- Helmを使用しない(Kustomizeで差分吸収する)
Spinnakerは主にマルチクラウドで運用している複数のKubernetesクラスタに対してデプロイをする際に使用されるCDツールです。Kubernetesでの操作、例えばルーティング設定の変更やpodのデプロイなどをStageとして提供し、そのStageを組み合わせてパイプラインを作っていくというツールです。
Spinnakerを採用することで、従来のシェルスクリプトのときよりも比較的変更が容易でテストが簡単になりました。切り替え前のウォーミングアップクエリの実行というのも実現できるようになりました。
まとめ
Kubernetes基盤に移すことで明確に変わったのは構築が簡単になったことだと思います。正確に計測は出来ていませんが、Solrを扱うチームやインフラの負荷が減っているように思います。
オートスケールできるように作ることで、もちろん高負荷になったときにも輻輳せずに済むというのは要素として大きいとは思います。それだけでなく、そのように作成することで仮に手動で増やさなくてはいけない場合にも、kubectl一つ打つだけでいいというのは、そうでないのかではかなり心情的にもかかるプレッシャーが変わってきます。いい意味でインフラレイヤの抽象化ができた事例なのではないかと思います。
※ コンテナ化出来た理由の一つとして、ナビタイムのSolrサーバのインデックスデータのサイズや更新頻度がマッチしたというのがあると思いますので、マネージドサービスが使える場合にはマネージドサービスを使うべきだと思います。