はじめに / 概要
こんにちは! ナビタイムジャパンの検索周りを担当している taito です!
NAVITIME JAPAN Advent Calendar 2019 の18日目は、
OpenNLP を用いたワードの種別推定の記事になります。
利用までに必要だったこと、実際に使ってみてどうだったか
サンプルを交えて紹介します。
OpenNLP とは
OpenNLP とは Apache が提供しているオープンソースで、
教師あり機械学習を用いて自然言語処理(NLP)を行うためのツールキットです。
ライセンスは Apache License, Version 2.0 のため、商用利用もできます。
固有値表現抽出、文書分類、言語判別などが主な機能となります。
また、Java で書かれているため、Kotlin でも問題なく利用できます。
なぜ種別推定が必要?
ナビタイムジャパンのサービスでは、検索されうる地点がたくさんあり、
その地点には様々な種別があります。
より良い検索 UX を提供するために、ユーザが入力した検索文字列の種別を知る必要がありました。
利用までに必要だったこと
ここから、具体的にどのようなステップで OpenNLP を利用したのかお話します。
どの機能を使うかの選定
今回は短めな文字列から種別を推定する必要があったため、
複数の単語から推定する文書分類はあまり期待をしていませんでした。
それに比べ言語推定は、出現する文字から特徴を掴んでカテゴライズするため、
そのまま種別推定にも利用できるのではないか と考えました。
加えて、判定の結果として特定の言語である可能性を出力してくれます。
そのため、種別推定というシーンでも「Aでもあるし、Bの可能性もありそう」という
曖昧な状態を返却できることも嬉しい点でした。
とりあえず OpenNLP の言語推定のサンプルをそのまま流用して様子を観察したところ、
チューニングなしでも十分実用可能な精度を出してくれたため、
OpenNLP の言語判別を応用して種別推定を行うことに決定しました。
学習データを揃える
機械学習の一つである教師あり学習では、
大量の学習データから生成(training)された学習モデルを利用します。
幸運なことに、ユーザの入力データと、どの種別を選択されたかについてのログがあるため、
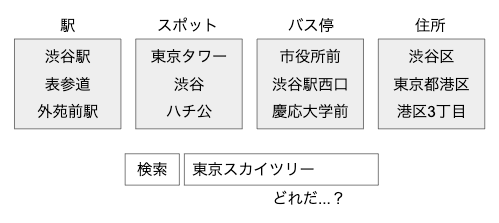
そのログを整形し tsv形式 に変形します。1
station 渋谷駅
station 表参道
station 外苑前駅
spot 東京タワー
spot 渋谷
spot ハチ公
bus_stop 市役所前
bus_stop 渋谷駅西口
bus_stop 慶応大学前
address 渋谷区
address 東京都港区
address 港区3丁目
...
学習モデルを作成する
学習モデルは、 OpenNLP が提供している LanguageDetectorTrainer を
そのまま利用して作成してしまいましょう。
Mac環境で OpenNLP を利用する場合、Homebrew が便利です。
$ brew install apache-opennlp
$ which opennlp
/usr/local/bin/opennlp
$ opennlp
OpenNLP 1.9.1. Usage: opennlp TOOL
install が完了した環境で、実際にモデルを作成してみましょう。
モデルの作成
(teacher.tsv 1600000行, MacBook Pro 2.3GHz Intel Core i5 メモリ16 GB)
$ wc -l teacher.tsv
1600000 teacher.tsv
$ opennlp LanguageDetectorTrainer -model path/to/model.bin -data path/to/teacher.tsv
...
Writing language detector model ... done (2.332s)
Wrote language detector model to
path: ./model.bin
Execution time: 125.129 seconds
以上です。学習データの量に比例して学習にかかる時間が決まります。
モデルの利用方法
さて、ついに作成したモデルを使って推定結果を見てみます。
プロジェクト管理ツールに maven を利用している場合、
pom.xml に以下のように追加します。
バージョンの部分は MavenDependency を参照してください。
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.9.1</version>
</dependency>
そして、適当な場所でモデル生成時には含まれていない「東京スカイツリー」を推定してみると…
import opennlp.tools.langdetect.Language
import opennlp.tools.langdetect.LanguageDetectorME
import opennlp.tools.langdetect.LanguageDetectorModel
import java.io.FileInputStream
import java.io.IOException
val text = "東京スカイツリー"
val results: Array<Language> = try {
FileInputStream("path/to/model.bin").use { file ->
val model = LanguageDetectorModel(file)
val detector = LanguageDetectorME(model)
detector.predictLanguages(text)
}
} catch (e: IOException) {
emptyArray()
}
results.forEach { println(it) }
spot (0.7995760814164472)
station (0.1367080087255519)
bus_stop (0.04684532282711341)
address (0.016870587030887403)
「東京スカイツリー」がきちんと spot として判別できています!
他にも色々試してみました
=================
text:渋谷
station (0.7674298331947947)
address (0.21220421734145017)
spot (0.01904468725990854)
bus_stop (0.0013212622038465932)
=================
text:渋谷区役所
spot (0.843890991967402)
bus_stop (0.15584606552773855)
address (2.629416136429711E-4)
station (8.912165800512555E-10)
=================
text:渋谷区
address (0.9999741710225473)
spot (2.4374499495322535E-5)
bus_stop (1.4534812104653355E-6)
station (9.967469235272814E-10)
いい感じに推定できています!
実際に使ってみて
推定器の特性を理解する
あくまで LanguageDetector なことを忘れないでください。
「数字や記号の情報が落ちる」などの、言語推定特有の癖もありますので、
そのような部分は推定器と仲良くなり、特性を知る必要があります。
推定器「だけ」にこだわらない
チューニングをしていくと、推定器の気持ちがわかるようになり、だんだん可愛く見えてきます。
「あともう少し… あともう少し…」 が口癖になります。
しかし、この推定結果だけを用いて結果を出すことにこだわると苦しむことになるため、
スコアを 参考 に推定するシステムがちょうどよいかもしれません。
モデル側が状態を持つということ
モデル側が推定タイプの状態をもつことを意識する必要があります。
つまり、モデルを更新すると返却する推定種別も変化するため、
そのタイミングで実装側が意図しない種別が返却されることがあります。
そのため、モデルのバージョン管理はしっかりと行う必要があります。
環境構築はお早めに
ログを整形し、モデルを作成し、推定スコアを出し、チューニングして、を繰り返す作業は
高コストになること間違いなしですので、長い戦いになる見通しが立ち次第、
早めにチューニング環境を整えることをおすすめいたします。
まとめ
OpenNLP の言語推定を利用してワードの種別推定を行った結果、
想定よりも遥かに良い推定結果が得ることができました!
参考にしたページ
Apache OpenNLP https://opennlp.apache.org/
Apache OpenNLP Developer Documentation
-
OpenNLP のデリミタはタブ文字 ↩