はじめに
コロナ対策の一環として、テイクアウト営業に切り替えて営業している地域のお店がたくさんあります。ただ、どこでテイクアウト営業をしているか、周知が課題です。文京区でも、テイクアウト営業を模索しているお店が多く、区もこれを支援する活動を始めました。(出前・持ち帰り 可能店を一覧に 文京区などリスト作成 日経新聞4月3日 )
ただ、現時点では このリスト は PDF 形式でした。スマートフォンで見れるように してこそ価値があるはず。そこで PDF のデータをエクセルに抽出してみることにしました。
PDF のデータをエクセルに抽出
tabula-py を試したところ、十分なデータが抽出できました。成功事例を簡単にまとめておきます。
もちろん、元となる PDF の作り方や構造などに大きく左右されるでしょうから、個別の情報源に対して試行錯誤は必要になると思います。
環境
- Windows10 Pro ver 1909
- Anaconda python 3.7
- Java 1.8.0_241
ライブラリの導入
pandas と openpyxl (導入ずみでした)、そして tabula-py を anaconda で導入しました。
conda install -c conda-forge tabula-py
tabula-py の開発者は直接は windows での動作を確認していないようですが、今回は Java8 をインストールするだけで tabula が動作しました。
テーブルの取り込み
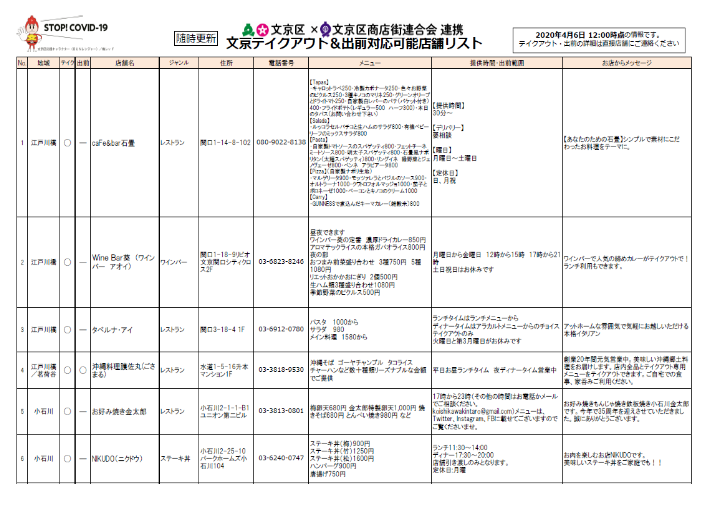
PDF のテーブルは、11コラム、当初は 13 ページのファイルでした。更新されて今後は長くなっていくことが想定されます。何度か tabula での読み込みを試行して、こんなことがわかりました。
- 各ページ4つずつあるテーブルの最後が欲しいデータ(だと tabular は認識する)
- 裏では、そこそこエラーメッセージも吐いているけれど、実用的なデータが取得できている
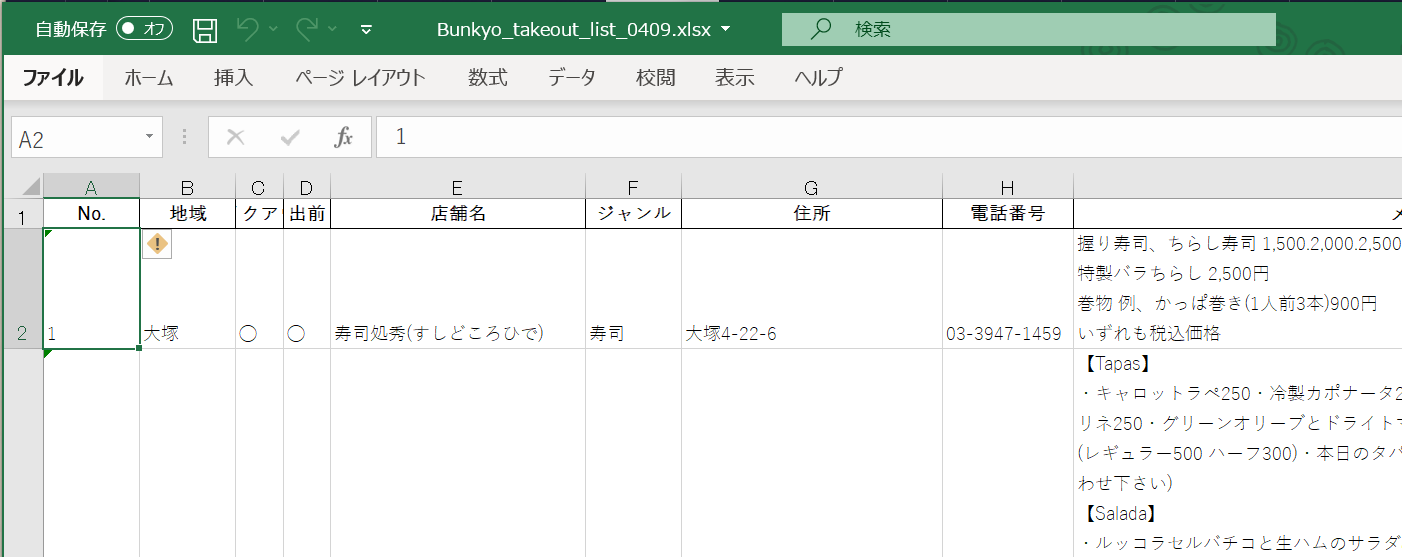
各ページのテーブルについているヘッダは、最初の1つだけをコピーして全部つなげて DataFrame を組み立てることにしました。
セル内改行は、明らかに不要なコラム(店名、住所)と、メニューなど、統一のとれていないセルがありました。統一の取れていないコラムに対しては、手を加えないで、必要ならエクセル上で対処することにします。(あるいは、対応しない、と割り切る)
以下は、tabula が table と認識するものが各ページに4個ずつあるときに動作するコード例です。(上記スクリーンショットのときには、各ページ3個でした。フォーマット変更にフレキシブルに対応することは重要です。)
import tabula
import pandas as pd
b_df_a = tabula.read_pdf('Bunkyo_list_0409.pdf', multiple_tables=True, lattice=True, pages='all')
BoxPerPage = 4 # table と認識するものが各ページに 4 個ずつあった。
tindex = range(BoxPerPage - 1, len(b_df_a)) # [3, 7, 11, ...]
btakeout_df = pd.concat([b_df_a[i] for i in tindex])
btakeout_df = btakeout_df.drop(index=0)
btakeout_df[4] = btakeout_df[4].str.replace('\r', '') # 店舗名
btakeout_df[6] = btakeout_df[6].str.replace('\r', '') # 住所
hd = b_df_a[BoxPerPage - 1].iloc[0]
btakeout_df.columns = hd.values
btakeout_df.to_excel('Bunkyo_takeout_list_0409b.xlsx', index=False)
これで .xlsx ファイルができます。
btakeout_df.head(3) として DataFrame を確認すると、改行が `\r' となっていますが、データは読めていそうです。データ件数なども確認しました。

そのあとのプロセス
- エクセルファイル上で、改行の調整など。
-
Google Drive にアップロードして、Spreadsheet に変換
-
Glide を使って、PWA サイトを作りました。
文京テイクアウト: bunkyotakeouts.glideapp.io/
作業メモ Part 1. として 区役所の PDF を半日でウェブアプリ化 を、Note に書きました。無料プランだと 500 レコードが上限です。 -
あとから気づきましたが、コロナ対策の地域情報サイトなどを Glide で作っている人が世界中にたくさんいる ようです。
-
PDF データの取り込みから、GlideApp の動作まで、初めてでも 3-4 時間でできました。ツボを押さえれば、小さなサイトは 1-2 時間で作れそうです。