やったこと
OpenAI 対応のドキュメント検索のためのシンプルな Web アプリケーション。このリポジトリは、ドキュメントから埋め込みベクトルを作成するために Azure OpenAI Service を使用します。ユーザーの質問に答えるために、最も関連性の高いドキュメントを取得し、GPT-3 を使用して質問に一致する回答を抽出します。
MS公式?のサンプルをそのままやってみただけ。
アーキテクチャ
上記のGitHubのやつを書き直しただけです。

文章のベクトル化(Embedding)
ここがちょっと馴染みないところかなっと思います。
ChatGPTにしろ、何にしろ、LLMは学習や検索の内部表現として、文章や単語を「ベクトル」に変換しています。
AzureOpenAIでは text-embedding-ada-002 などが内部表現への変換用モデルとして用意されています。
Azure OpenAI Service モデル - Azure OpenAI | Microsoft Learn
概念図としてはこんな感じです

環境構築
事前準備
- AzureOpenAIのリソースを作っておく
- 申請フォームが英語で辛いですが頑張りましょう
- ちゃんと書けば、最近は比較的早く承認されるようです
- text-davinci-003、text-embedding-ada-002をデプロイしておく
- Azure Translatorのリソースを作っておく
- Azure Form Recognizerのリソースを作っておく
Translator、Form Recognizerのリソースは使わなくてもいいが、テンプレートで参照必須になっているので作っておく
ARMデプロイ

ぽちっとな~。
1個めの方を使うと、Azure Cache for Redis Enterpriseで月1000ドルくらい請求されるので注意。
本番稼働させるならそれでよいと思いますが、
個人開発者やお試しでは、おとなしくRedisStackを使いましょう。(機能はおなじ)
パラメータ
基本、そのままでもいいのですが
多少いじったところ
- Hosting Plan Sku: デフォがB3ですが、お試しならF1かB1で十分
- Redisコンテナのリソース(テンプレート修正)
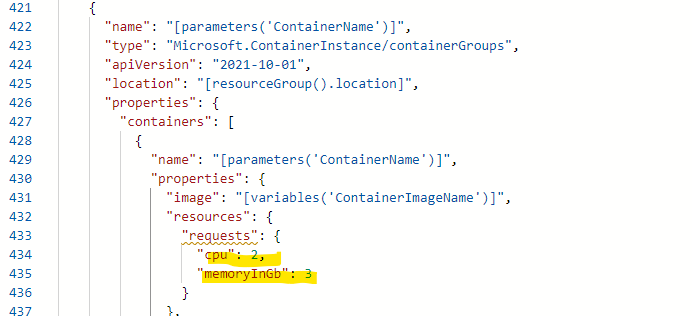
ミニマムだと足りない気がしたので、気持ち増やした。
確認
テンプレートで作られたwebAppから確認。
エラーになってたらなんとかする。
(だいたいパラメータ関連)
ナレッジを覚えさせる
アップロード
テンプレートから作られたストレージのdocumentフォルダに、教えたいナレッジを放り込む。
当たり障りのないところ、ということで直近のNHK News Webの記事を放り込みました。
実際には社内のマニュアルとか、QAドキュメントとかを放り込むとよいかと。
埋め込み
テンプレートで作られたwebAppからポチポチっとな。
裏側でバッチ処理のキューが走るので10分くらい待つ。

どんな感じのデータになるのか
doc:embeddings:ff4d1e9c448d57211a90e9ad34fcedfac0333072,
20230512_k10014065001000.html.txt,
[https://xxxxxx.blob.core.windows.net/documents/20230512_k10014065001000.html.txt]
(https://xxxxxx.blob.core.windows.net/documents/20230512_k10014065001000.html.txt_SAS_TOKEN_PLACEHOLDER_),
て7.4倍高かったという研究結果が報告されています。日本国内の対応はサル痘(エムポックス)は感染症法上、狂犬病などと同じ「4類感染症」に指定され、診断した医師は患者の発生を保健所に届ける必要があります。サル痘(エムポックス)のウイルスは、水疱に含まれている液体などから新型コロナウイルスと同じようにPCR検査で調べることができます。厚生労働省は、国立感染症研究所のほか、すべての都道府県の地方衛生研究所で実施できる体制を整備し、自治体に対して感染が疑われる患者がいれば速やかに報告するよう求めています。そして、感染が確認された場合は、全国に58か所ある感染症の指定医療機関な,
"{'source': '[https://xxxxxx.blob.core.windows.net/documents/20230512_k10014065001000.html.txt](https://xxxxxx.blob.core.windows.net/documents/20230512_k10014065001000.html.txt_SAS_TOKEN_PLACEHOLDER_)', 'chunk': 16, 'key': 'doc:embeddings:ff4d1e9c448d57211a90e9ad34fcedfac0333072', 'filename': '20230512_k10014065001000.html.txt'}"
裏側で記事を適当な長さにぶった切って(トークン数の制限に収めるため)、
メタデータを付与して、Redisに突っ込んでくれる。
Redisを直で見るとcontent_vectorにベクトル表現を持ってる
結果
ChatGPTについて
埋め込みなし

埋め込みあり

広島サミット
埋め込みなし
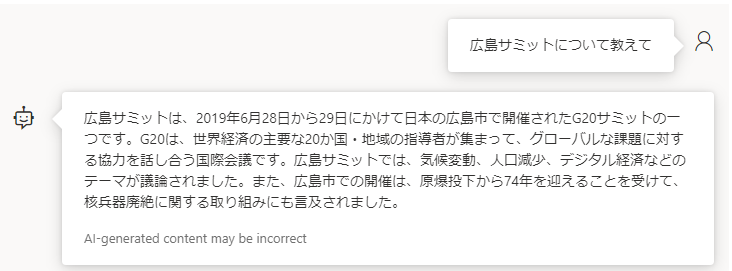
埋め込みあり

ウクライナ情勢
埋め込みなし

埋め込みあり
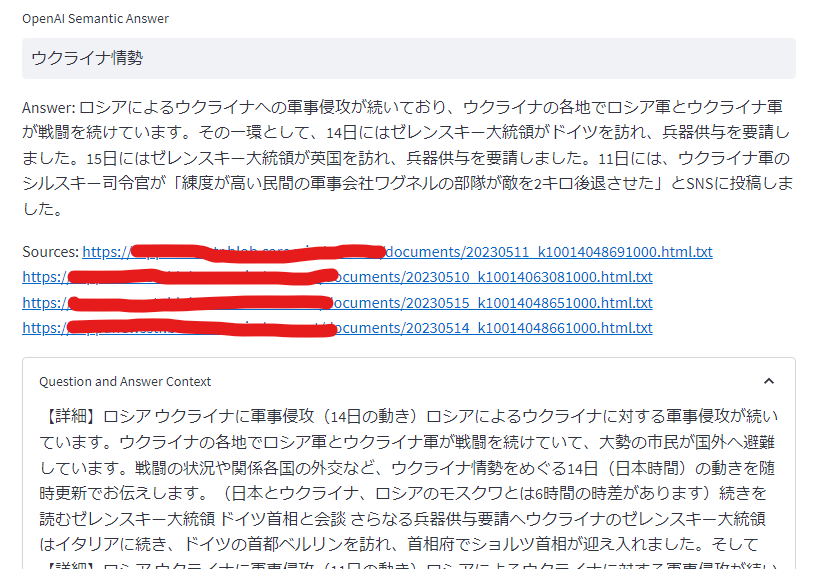
NHKニュースを埋め込んだことで、直近の情報や、国内情勢についての情報が得られるようになりました。
また、出典や原文を合わせて参照できるのもいい感じ。
複数のナレッジを組み合わせたり、通常の回答と組み合わせて要約させたりすると、よりいい感じになるかと。
ポイント
- OpenAIのモデルは、ベースモデルの名前でデプロイする
- 変えると、エンコーダの引き当てでエラーになる
- 一番の沼ポイントだった。。。
- 埋め込みをする前にテキストを前処理する
- 今回はクローリングしてきたテキストを雑に食わせただけだが、多少の前処理をすれば改善が期待できる
- 逆に言えば雑に食わせても↑くらいにはなる
- 内部的にはLangChainとか使ってるぽい
- OSSの他モデルへの展開も容易そうですね!
活用シーン
社内ナレッジにChatGPT使ってなんかできないの???は現在頻出ネタと思われますが、
ガチでFine-tuningするとなると、最低でも数万円&数十時間は覚悟する必要があり、
テキストの事前処理やLLM・機械学習に関する基礎知識も必要になり、
正直ハードルが高いのが現状かと思います。
それに対してのすぐに使えるソリューション回答として、最適ではないかと!
構築は基本ポチポチしたりコピペしたりするだけ。
ナレッジの追加であれば、ファイルアップロードしてボタン押すだけなので、非ITの人にも触ってもらいやすいのもグッド。
裏側を解読するなりAPIだけ取り出すなりして、SlackBotにするとか、可能性は無限大。
ちなみに、NHKのニュース1ヶ月ぶん、700件くらい(テキスト量としては1.5MB)で構築して
1日1,000円以下くらいでできました。
初期状態ではコストの半分がRedisのコンテナ、半分がAzure OpenAI利用料といったところです。
現場からは以上です。