概要
ChatGPTとかBingChatとかのタイピングぬるぬる出てくるのカッコいいので、自分でも実装してみたメモ。
多分、ChatGPTでもそのまま動きます。(APIが完全に一緒なので)
why?
世の中的情報はそれなりにあるのですが、コマンドプロンプトベースだったり、Jupyterベースだったり、Next.jsベースだったりで
完全一致!って案件がなかったのでまとめ。
ついでに結構真面目にTypeScript書きました。
(が、コンパイル前のvue-tscで謎のバグにはまった、、、)
構成
- Node.js
- Vue.js (Vue3 + TypeScript + Composition API)
- Azure OpenAI
実装
型定義
JSONオブジェクトそのままなのはキモチワルイなーってことで、ちょっとだけ真面目に書いた。
しかしキモチワルイくらいにコード補完が効く。。
みんなChatGPTのコード書いてるんですね!!!
型定義ファイルはどう分けるのが正解なのかまだわかってないので、とりあえず使うところの近傍にって感じ。
export type ChatMessege = {
role?: "system" | "user" | "assistant";
content?: string;
};
export type ChatCompletionMessageChunk = {
id: string;
object: string;
created: number;
model: string;
choices: [
{
delta: {
role?: "system" | "user" | "assistant";
content?: string;
};
indexe: number;
finish_reason: "stop" | "max_tokens" | "timeout";
}
];
};
API呼び出し
export async function* streamChatCompletion(
input: ChatMessege[],
token: String
) {
const req = JSON.stringify({
model: openAIConfig.model,
temperature: openAIConfig.temperature,
messages: input,
stream: true, // streamオプションを付ける
});
try {
const api_endpoint = openAIConfig.endpoint;
const completion = await fetch(api_endpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: "Bearer " + token,
},
body: req,
});
if (!completion.ok || !completion.body) throw new Error();
const reader = completion.body?.getReader();
if (completion.status !== 200 || !reader) {
console.error(completion);
throw new Error("Request failed");
}
try {
const decoder = new TextDecoder("utf-8");
let done = false;
let buffer = "";
while (!done) {
const { done: readDone, value } = await reader.read();
if (readDone) {
done = readDone;
reader.releaseLock();
} else {
buffer += decoder.decode(value, { stream: true });
while (true) {
const newlineIndex = buffer.indexOf("\n");
if (newlineIndex === -1) break;
const line = buffer.slice(0, newlineIndex);
buffer = buffer.slice(newlineIndex + 1);
if (line.includes("[DONE]")) {
done = true;
break;
}
// レスポンス
if (line.startsWith("data:")) {
const chunk = JSON.parse(
line.slice(5)
) as ChatCompletionMessageChunk;
yield chunk;
}
}
}
}
} catch (error) {
console.error(error);
} finally {
reader.releaseLock();
}
} catch (error) {
console.error(error);
return null;
}
}
ほぼほぼコピペとリファクタしただけなんだけども、ざっくり
ストリームオプションつけて
const req = JSON.stringify({
model: openAIConfig.model,
temperature: openAIConfig.temperature,
messages: input,
stream: true, // streamオプションを付ける
});
fetchしたあとにawaitしないでリーダーを取り付け
const reader = completion.body?.getReader();
リーダーのループ
while (!done) {
const { done: readDone, value } = await reader.read();
それからバッファにdecode
buffer += decoder.decode(value, { stream: true });
chunkも毎回送られてくるわけでもなく、1回に数行来ることもある、、気がする。
ので一応ループ(改行区切りで取り出し)
while (true) {
const newlineIndex = buffer.indexOf("\n");
if (newlineIndex === -1) break;
const line = buffer.slice(0, newlineIndex);
buffer = buffer.slice(newlineIndex + 1);
[DONE]が来たらおしまい
if (line.includes("[DONE]")) {
done = true;
break;
}
それ以外なら返答なので、JSON.parseで事前定義したtypeに変換してyield
// レスポンス
if (line.startsWith("data:")) {
const chunk = JSON.parse(
line.slice(5)
) as ChatCompletionMessageChunk;
yield chunk;
}
画面
正直、ここが一番ハマった。。
Composition APIのreactiiveとかrefの挙動がまだよくわかってないので、、、![]()
とりあえず戦略としては
- 過去ログは配列管理する(チャットログを文脈として渡したいので)
- ストリームの出力は別変数に一旦入れて表示する
- 全部取得したら過去ログに突っ込む
呼び出し部。
makePromptは表示用に持ってるメッセージからAPIに渡す部分を引っこ抜くだけなので省略
<script lang="ts" setup>
import { reactive, onMounted, inject } from "vue";
import { streamChatCompletion } from "@/api_call";
import type { AuthPluginType } from "@/plugins";
import type { ChatMessege } from "@/api_call";
// ユーザ入力と過去ログを扱う用
const message = reactive({
input: "",
logs: [],
});
// ストリーム出力を表示する用
const prompt = reactive({
content: "",
loading: false,
color: "bg-light-blue-lighten-5",
});
//
const getChatCompletion = async () => {
// 最新の入力をログに突っ込む
message.logs.push({
id: message.logs.length + 1,
color: user_color,
icon: "mdi-chat-question-outline",
message: {
role: "user",
content: message.input,
} as ChatMessege,
});
message.input = "";
//API呼び出し
const generator = streamChatCompletion(makePrompt(), auth.accessToken());
// 順次生成の回答を表示
prompt.loading = true;
for await (let chunk of generator) {
if (chunk.choices[0].delta.content != null) {
prompt.content = prompt.content + chunk.choices[0].delta.content;
}
}
prompt.loading = false;
// 最後まで受信したらログに追加
let resChat = {
id: message.logs.length + 1,
color: ai_color,
icon: "mdi-robot",
message: {
role: "assistant",
content: prompt.content,
} as ChatMessege,
};
prompt.content = "";
message.logs.push(resChat);
};
</script>
画面表示
受信中の表示は、v-listに入れたかったけどむりぽかったのでv-cardで間に合わせました。
<!-- メインのログ表示 -->
<v-list>
<v-list-item v-for="item in message.logs" :key="item.id">
<template v-slot:prepend>
<v-avatar>
<v-icon :icon="item.icon" size="x-large"></v-icon>
</v-avatar>
</template>
<v-card :text="item.message.content" :color="item.color"></v-card>
</v-list-item>
</v-list>
<!-- メッセージ受信中だけ表示するカード -->
<v-card v-show="prompt.loading" flat class="px-4">
<div class="d-flex flex-no-wrap">
<v-avatar>
<v-icon icon="mdi-loading mdi-spin" size="x-large"></v-icon>
</v-avatar>
<v-card-text :class="prompt.color">{{
prompt.content
}}</v-card-text>
</div>
</v-card>
感触
やっぱり全部生成してから取るよりは体感早いですね。
全部帰ってくるのにかかる時間は、、、正直そんなに変わらない気がする。
GPT-4-32Kだと返答トークンも多くなるはずなので、利点が見えるかも?
ざっくり2~3回くらいに分けて帰ってくる感があるので、内部的には数十文字くらい作ったら再推論とかしてんのかなぁって思いますね。
回答中
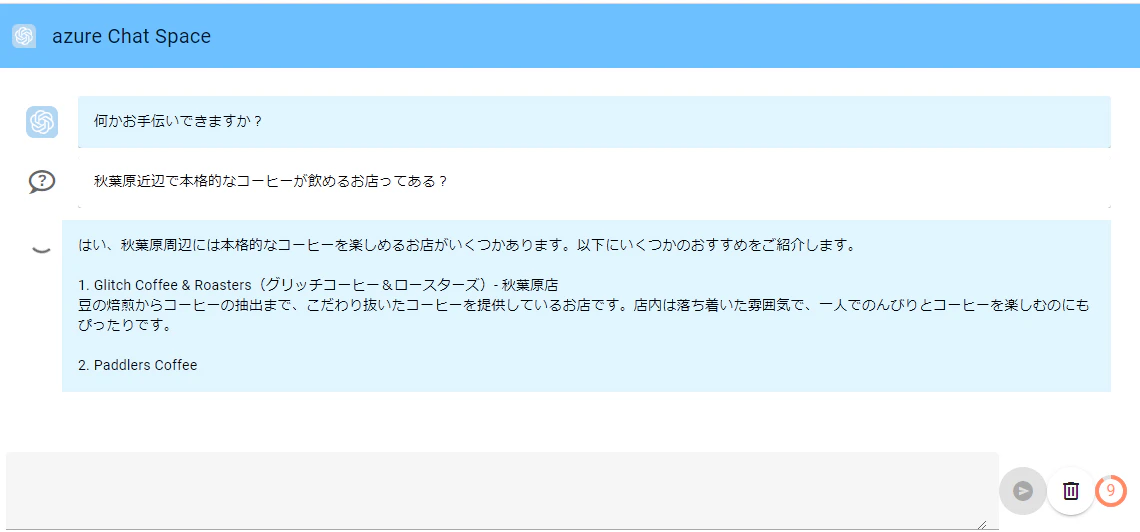
最終的な回答。

ちなみに上記回答の店舗はどれも秋葉原店は無かったです![]()