AWS re:Invent 2019で新たに発表された**「DeepComposer」**のワークショップに参加し、実機を触ってきました。
現地でAWS様に「書きます!」と宣言し、記事内容見ていただきOK貰いましたので、その模様を紹介したいと思います。

はじめに: サービスはPreviewなので触り倒した話は書けない
サービス自体がPreviewということもあり、規約上、サービスの評価に関する内容は載せられませんので、公式に出ている資料をベースにして、DeepComposerとはこんな感じだよという、ワークショップの報告のような形になりますので、予めご了承いただければと思います。
ちなみに、Previewは以下から申し込めます。
https://pages.awscloud.com/AWSDeepComposerPreview.html
DeepComposerとは?
AWSが提供する、人々がAIを学ぶための新しいガジェットで、Generative AI algorithmsを学ぶことに特化し、機械学習による自動編曲にテーマを置いています。
Generative Adversarial Networks (GAN) というモデルに基づく生成物は、実在しないものでありながら、現実との区別がつかないほどの精度になるそうです。
つまりDeepComposerで作曲した楽曲も、少し聴いただけではAIによるものか人手によるものかどうかが分からない、ということでしょうか。
何ともすごい時代がやってきたものです。

詳しくは、以下のサイトにも紹介されています。
AWS DeepComposer – Compose Music with Generative Machine Learning Model
DeepComposer Workshop
今回のワークショップは、そのDeepComposerの実機を触って、試すことができるものです。
アジェンダは以下の内容でした。
- ML on AWS (10 miniutes)
- Introdution to ML and Generative AI (20 minutes)
- Lab 1- Music composition with AWS DeepComposer models (35 minutes)
- Lab 2- Training models with AWS DeepComposer (55 minutes)
ここでは、3.と4.のLabの模様に絞って紹介していきます。
Lab 1: Music composition with AWS DeepComposer models
DeepComposerの使い方、目指すところを理解するための導入ワークショップでした。
最初に、DeepComposerとPCを接続します。

次に、AWSのDeepComposerのマネジメントコンソールを開きます。
ここで「Compose music」を押すと、サンプルの音楽(きらきら星)の音源が表示されます。
ここで再生ボタンを押すと、ピアノの音源が流れます。
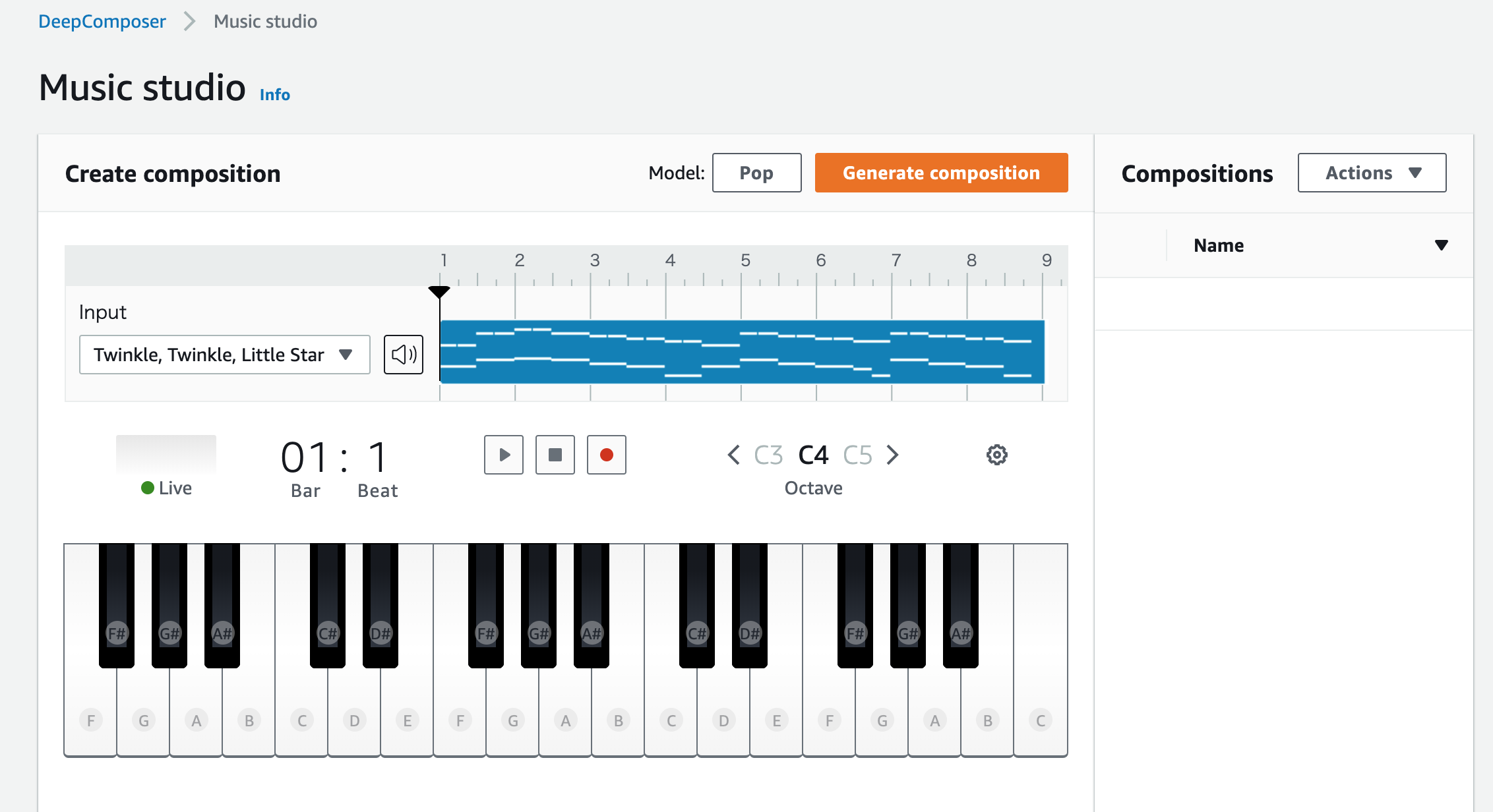
この音源に対して編曲していきます。
標準で用意されているモデルの中から「Pop」を選び、「Generate Composition」を押します。
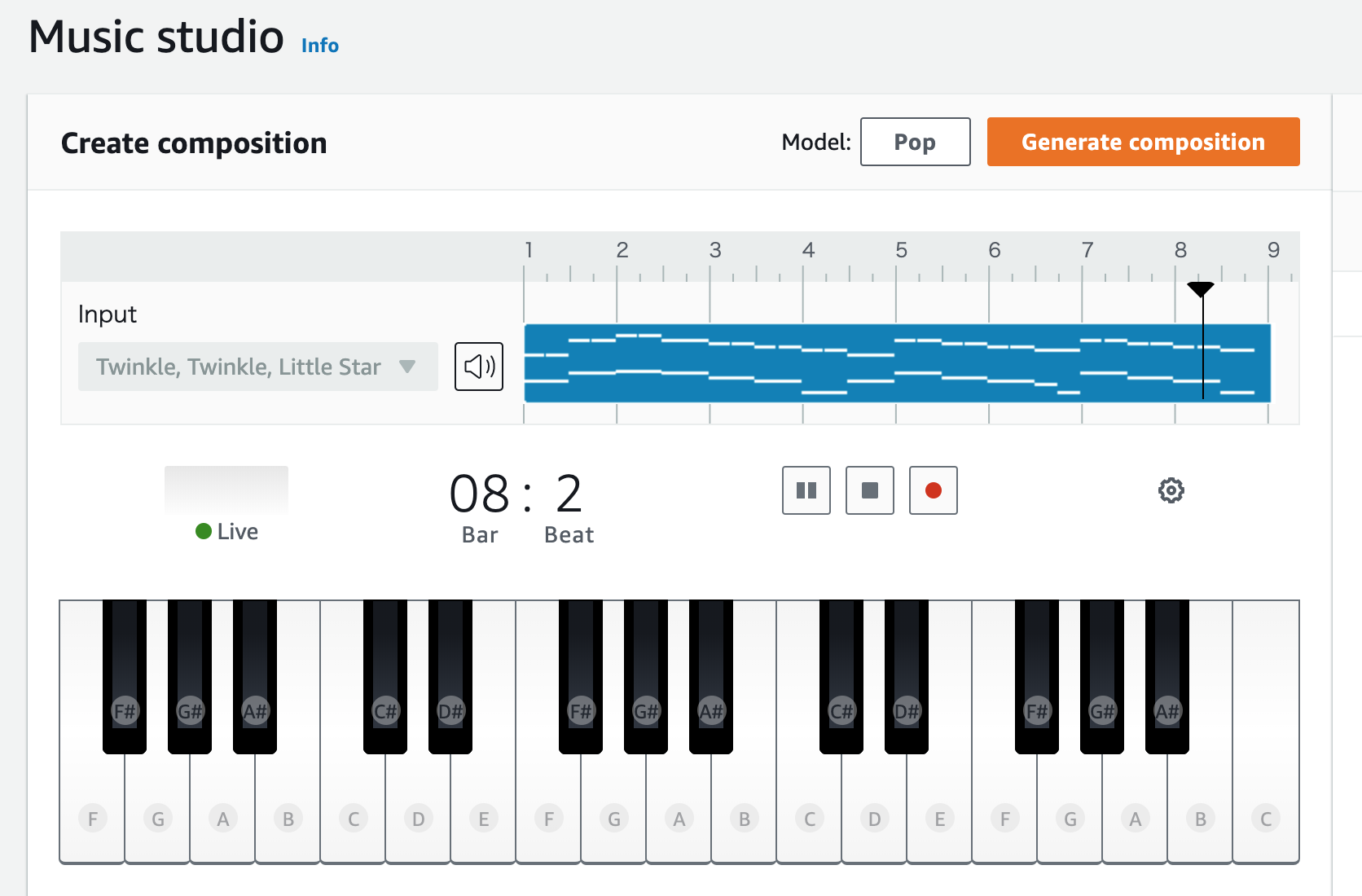
すると、なんと一瞬でPop風のきらきら星が生成されます。
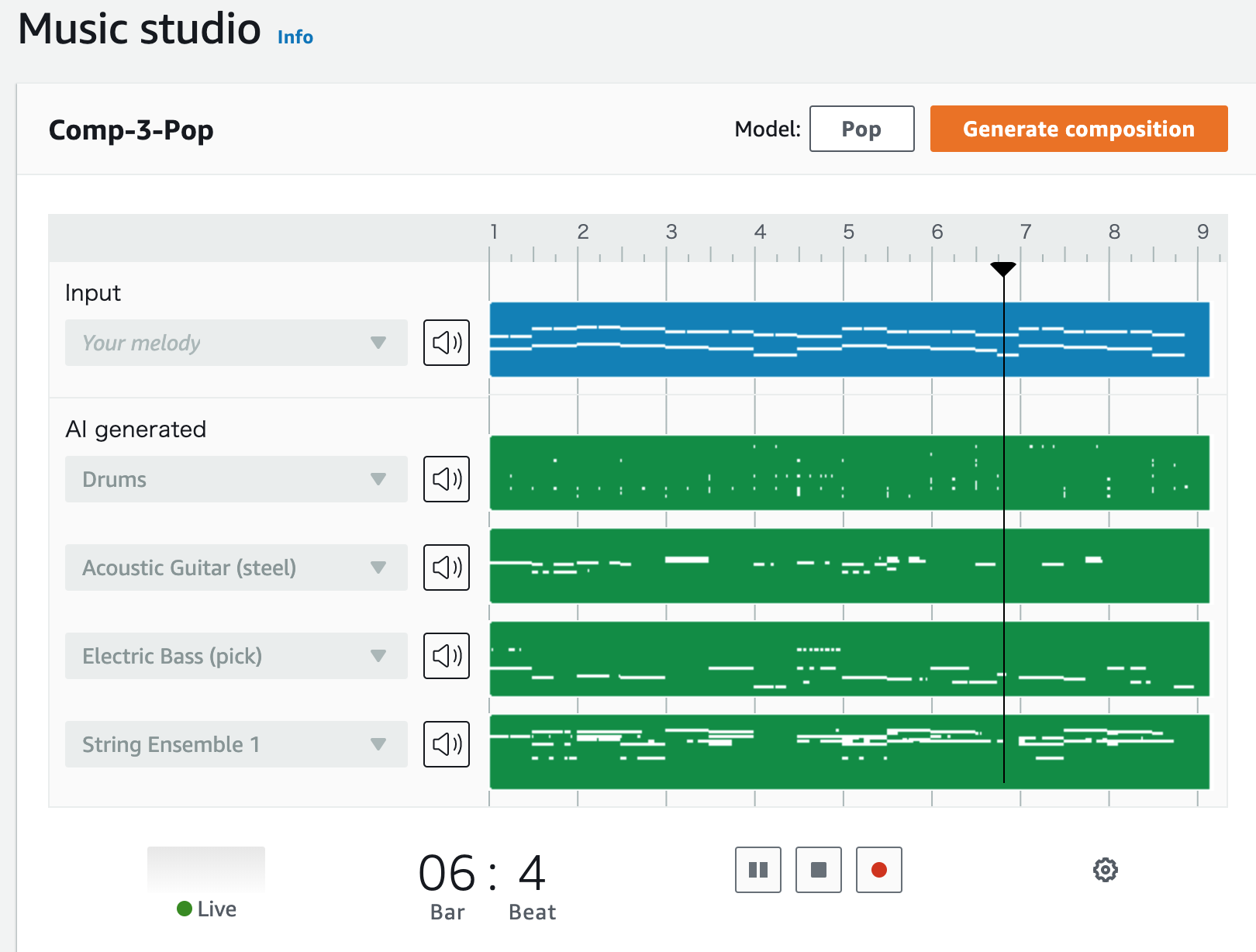
次に、PCに接続したDeepComposerで、AWSが用意した『メリーさんのひつじ』の楽譜に基づいて打ち込みます。
手順の通り、モデルを「Jazz」に変えてみます。
最後に「Generate Composition」を押すと、ジャズ風の『メリーさんのひつじ』が出来上がります。
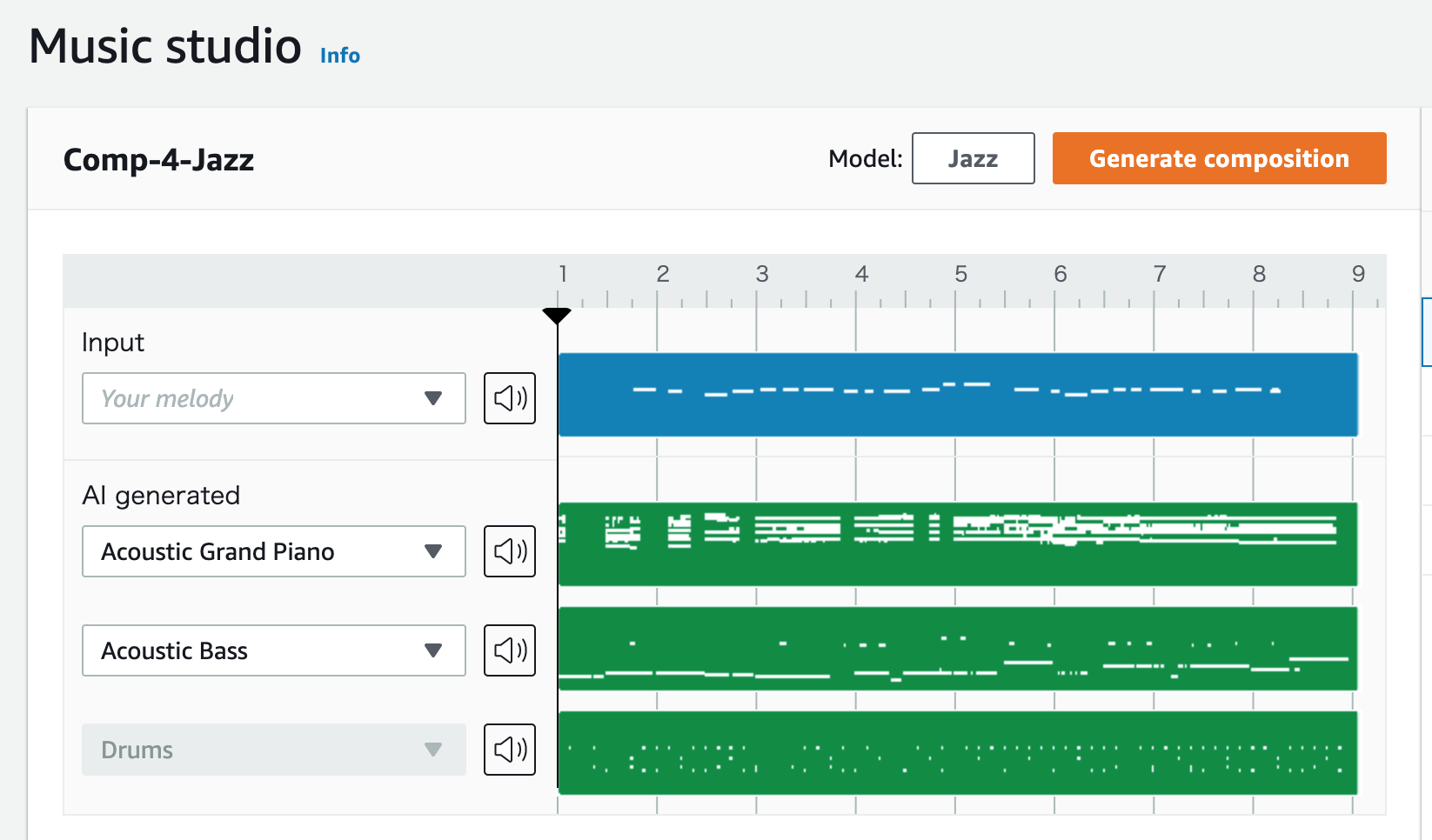
このように、既存のサンプル音源に加え、DeepComposerで打ち込んだ音源に対して、アレンジすることができます。
マネジメントコンソールでサンプルを扱うことで、DeepComposerが何を学ぶことを目指したサービスでありガジェットなのかということは理解できると思います。
Lab 1の資料や手順は、以下に上がっています。
Lab 1: Compose music with DeepComposer models
Lab 2: Training models with AWS DeepComposer
Generative Adversarial Networks(GAN)を使用して音楽を生成する方法を学ぶLabでした。
私がこの分野にあまり精通しておらず恐縮ですが、理解できた範囲でまとめてみます。
SageMakerのコンソールにアクセスして、ワークショップ用のノートブックインスタンスで、Jupyterを開くと、カスタムのGANモデルをゼロから作成するための手順とコードが含まれたノートブックが開き、このノートブックを使って学習を進めていきます。
このノートブックで、バッハをインスパイアした機械学習モデルをトレーニングし、トレーニングしたモデルがメロディに伴奏を追加するまでを学びました。
例えば、ユーザーが『きらきら星』などの曲のピアノ音源を1つ作ったとしたら、GANモデルはその音源に3つの他のピアノ音源を追加して、音楽をよりバッハにインスパイアさせるというものです。
トレーニングが進めば進むほど、よりバッハらしくなる (本人と区別がつかないほどに) ということのようです。
ワークショップではサンプル音源が用意され、音源をピアノロールとして扱い、x軸に時間、y軸にピッチを持つ、2次元表現として扱いました。
解説によれば、これは画像を機械学習で扱う時の考え方と同じであり、音楽にも応用できるのだと言います。
このようにデータを扱った後、ワークショップで予め用意されたモデル(GAN)に基づいて学習していきます。
GANはGeneraterとCitricという2つの要素で構成され、それぞれの損失関数に基づいてトレーニングをしていきます。
損失関数については、AWSにより公開された資料を参照してください。
Loss Functions for GAN architecture
ワークショップの内容はGitHubで公開されていますので、こちらを参考にしてみると良さそうです。
Lab 2- Train a custom GAN model
また、このLab 2を理解するにあたっては、基礎知識としてGANをちゃんと理解する必要性を感じました。
英語はそこそこ聞き取れましたが、難しかったです。
感想
DeepComposer自体の利用は、サンプルモデルを使う範囲であれば非常に簡単ですが、本格的にやるにはLab 2の内容を理解して独自にモデルを作り込むことになります。
そのためには、Lab 2の内容とGANを復唱できるくらいに頭に叩き込まないといけないと感じました。
また、ワークショップに取り組んで、この成果物は人が作ったのか、それとも機械的に作られたのか? と問われた時には、もはや問われた側は区別ができない、つまり人間の成果物とAIの成果物の区別ができない時代が来るということが、いよいよ現実に迫ってきたと感じました。
DeepComposerの題材で言えば、過去の作曲家を再現するモデルが共有されて、誰でも簡単に使えるようになる時代がやってくるのではと感じました。
そこには倫理的な問題もある気がしますが、ますます人間とAIの差が縮まっていることを感じました。
余談
今回の研修内での理解度確認のため、講師が「Kahoot!」というサービスを使われていました。
こちらも面白かったので共有します。
「Kahoot!」
https://kahoot.com/
参加者全員に同時に4択クイズを出して、結果を集計して、正誤と回答速度でランキング付けするサービスのようです。
UIが面白く、社内研修でどんどん使っていきたいサービスに感じました。
以上となります。