はじめに
Google NewsのRSSから提供される記事リンクには、直接のニュースソースURLとは異なるGoogle独自のエンコード形式が付与されています。
内部にはBase64文字列や特定パラメータが埋め込まれており、プログラムを介してオリジナル記事に直接アクセスするうえで障壁となることが少なくありません。
たとえば、ニュースの一次ソースへのリンクを取得して分析やレコメンドに活用したいとき、エンコードされた形式のままでは正確なリンク先が分からず、スクレイピングなどの解析がうまく機能しないという問題が生じます。
本記事では、こうした問題を解決するために、Google NewsのエンコードされたURLを解体し、元の記事URLを復元する技術的アプローチをご紹介します。
また、AWS Lambdaとの組み合わせにより、このデコード処理をサーバレスでスケーラブルかつ柔軟に運用し、他サービスと組み合わせて応用する点にも注目します。
なお、本記事に掲載しているコードは、オープンソースとして公開されている SSujitX/google-news-url-decoder の新バージョンをベースに、一部独自の拡張・調整を施したものです。
素晴らしいコードを公開してくださったオリジナルの作者(Sujit 氏)に、深く感謝を申し上げます。
オリジナルのリポジトリには、さらに詳しい実装例や更新履歴などが掲載されておりますので、合わせてご参照いただければ幸いです。
本記事の中でも、オリジナルのコードで実装された機能の有用性やその背景について、推測を入れながら考察しています。
Web上の記事やファイルを取得 (スクレイピング) する際は、引用元の著作者の権利を侵害したり、規約に抵触しないようにご注意ください。
<参考> https://pig-data.jp/blog_news/blog/scraping-crawling/scrapinglaw/
背景と目的
今回のコードは、Google Newsが提供するいわゆる “加工済みURL” を分析して取得した Base64文字列、署名、タイムスタンプを用い、Google側の内部APIにPOSTリクエストを送り、元のニュース記事に直接アクセスできるリンクを生成するプロセスを自動化したものです。
オリジナルのコードを参考に、AWS Lambda上で動作するように改変しています。
AWSのサーバレス環境におけるニュースの集約やスクレイピング、生成AIによる分析など、さまざまなユースケースを想定しています。
コードの解説
オリジナルのコードを参考にして、Lambda関数として動くように改変したコードを解説していきます。
GoogleDecoder クラスの全体像
このデコーダの中心的存在が GoogleDecoder クラスです。
初期化処理では、プロキシの設定およびデバッグモードの管理を行っています。
下記がクラスとコンストラクタのコード例です。
import json
import time
import logging
import re
from urllib.parse import quote, urlparse
import urllib.request
import urllib.error
# モジュールレベルのロガー設定
logger = logging.getLogger(__name__)
class GoogleDecoder:
def __init__(self, proxy=None, debug=False):
"""
GoogleDecoder クラスの初期化
Parameters:
proxy (str, optional): リクエストで使用するプロキシ。例: "http://user:pass@host:port"
debug (bool, optional): デバッグモードを有効にするかどうか。
"""
self.proxy = proxy
self.proxies = {"http": proxy, "https": proxy} if proxy else None
self.debug = debug
if self.debug:
logger.setLevel(logging.DEBUG)
else:
logger.setLevel(logging.INFO)
logger.debug(f"GoogleDecoder 初期化完了。proxy: {proxy}, debug: {debug}")
def _build_opener(self):
"""
プロキシ設定がある場合は ProxyHandler を用いて opener を構築する。
"""
if self.proxies:
proxy_handler = urllib.request.ProxyHandler(self.proxies)
opener = urllib.request.build_opener(proxy_handler)
else:
opener = urllib.request.build_opener()
return opener
コンストラクタの中で行うデバッグフラグとロガーの制御は、運用時のログの冗長度を適切に調整するための工夫です。
プロキシ設定が必要な場合も _build_opener を使えば、容易にカスタマイズされた通信が可能です。
get_base64_str
Google Newsの記事リンクは、たとえば https://news.google.com/articles/xxxxxxxxxx のように、ホスト名が news.google.com であることに加え、パスの一部に articles や read といった識別子が含まれ、その末尾に特定のBase64文字列が付与される構造になっています。
このBase64部分を正しく見つけ出せないと、後続のデコード手続きが成り立たなくなるため、get_base64_str では urlparse を用いてURL全体を分解し、ドメインやパスの要素を精査したうえで、想定された形式であれば末尾のBase64文字列を抽出しています。
また、Google News独自の形式が挿入されている以上、もしURLが想定と異なるパターンであれば正確なBase64文字列は存在せず、デコード処理を行おうにも誤ったリクエストを投げることになるため、早い段階でエラーを返す設計が必要です。
抽出されるBase64文字列は、のちほどGoogle News内部のエンドポイントと連携し、元記事URLの復元に使われる必須パラメータです。
つまり、適切にこの文字列を取り出さない限り、デコード全体の手順が成立しません。
こうしたURLの構造を正しく理解し、文字列の抽出処理を確実に行うことこそが、Google Newsのエンコードを解読する第一歩となります。
def get_base64_str(self, source_url):
try:
logger.debug(f"get_base64_str: 処理開始。source_url: {source_url}")
parsed_url = urlparse(source_url)
path = parsed_url.path.split("/")
logger.debug(f"get_base64_str: URL パス分割結果: {path}")
if (
parsed_url.hostname == "news.google.com"
and len(path) > 1
and path[-2] in ["articles", "read"]
):
base64_str = path[-1]
logger.debug(f"get_base64_str: 抽出された Base64 文字列: {base64_str}")
return {"status": True, "base64_str": base64_str}
message = "Invalid Google News URL format."
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("get_base64_str 内でエラーが発生")
return {"status": False, "message": f"Error in get_base64_str: {str(e)}"}
なお、この段階で判定に合致しないURLの場合には処理を打ち切るため、以降のステップにおいて想定外のエラーが起きにくい作りになっています。
get_decoding_params
取得したBase64文字列だけでは、Google Newsの内部APIにアクセスする際に不可欠な情報が不足しています。
署名(signature)とタイムスタンプ(timestamp)は、認証や復元のために必要なパラメータです。
Google NewsのURLからオリジナルのニュース記事のURLを取得する際、get_decoding_params メソッドは、必要な signature と timestamp を取得する役割を果たします。
このメソッドは、まず https://news.google.com/articles/{base64_str} という形式のURLにアクセスし、該当するデータ属性を持つ要素を探します。
もしこの方法で必要な情報が取得できない場合、フォールバックとしてhttps://news.google.com/rss/articles/{base64_str} というRSSフィードのURLにアクセスし、同様のデータ属性を持つ要素を探します。
このようなフォールバックが実装されている理由は、Google Newsのエンドポイントが記事の種類によって異なる可能性があるためと考えられます。
より広範なケースに対応し、安定的に signature と timestamp を取得することを可能とする工夫と言えます。
なお、オリジナルのコードでは selectolax ライブラリを使用していますが、Lambda関数で実行するため、標準ライブラリの re を用いてHTMLから必要な属性(data-n-a-sg, data-n-a-ts)を抽出するように改変しています。
def get_decoding_params(self, base64_str):
try:
url = f"https://news.google.com/articles/{base64_str}"
logger.debug(f"get_decoding_params: articles URL を試行: {url}")
req = urllib.request.Request(url)
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
text = response.read().decode("utf-8")
logger.debug("get_decoding_params: articles URL からのレスポンス取得成功")
signature_match = re.search(r'data-n-a-sg="([^"]+)"', text)
timestamp_match = re.search(r'data-n-a-ts="([^"]+)"', text)
if not signature_match or not timestamp_match:
message = "Failed to extract data attributes from Google News with the articles URL."
logger.error(message)
return {"status": False, "message": message}
signature = signature_match.group(1)
timestamp = timestamp_match.group(1)
logger.debug(f"get_decoding_params: 取得した signature: {signature}, timestamp: {timestamp}")
return {
"status": True,
"signature": signature,
"timestamp": timestamp,
"base64_str": base64_str,
}
except (urllib.error.HTTPError, urllib.error.URLError) as req_err:
logger.warning(f"get_decoding_params: articles URL でエラーが発生: {req_err}")
# fallback: RSS URL を試す
try:
url = f"https://news.google.com/rss/articles/{base64_str}"
logger.debug(f"get_decoding_params: fallback RSS URL を試行: {url}")
req = urllib.request.Request(url)
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
text = response.read().decode("utf-8")
logger.debug("get_decoding_params: RSS URL からのレスポンス取得成功")
signature_match = re.search(r'data-n-a-sg="([^"]+)"', text)
timestamp_match = re.search(r'data-n-a-ts="([^"]+)"', text)
if not signature_match or not timestamp_match:
message = "Failed to extract data attributes from Google News with the RSS URL."
logger.error(message)
return {"status": False, "message": message}
signature = signature_match.group(1)
timestamp = timestamp_match.group(1)
logger.debug(f"get_decoding_params: fallback で取得した signature: {signature}, timestamp: {timestamp}")
return {
"status": True,
"signature": signature,
"timestamp": timestamp,
"base64_str": base64_str,
}
except (urllib.error.HTTPError, urllib.error.URLError) as rss_err:
message = f"Request error in get_decoding_params with RSS URL: {str(rss_err)}"
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("get_decoding_params 内で予期しないエラーが発生")
return {"status": False, "message": f"Unexpected error in get_decoding_params: {str(e)}"}
最終的に取得したこれらの値は、後続のデコード処理で使用されます。
このプロセスにより、Google Newsの特殊なURL形式から元のニュース記事のURLを復元することが可能となります。
decode_url
こちらがデコード処理の核となるメソッドです。
signature と timestamp、そしてBase64文字列を組み合わせて、内部APIに対してJSONデータをPOSTし、レスポンスから元のURLを取り出します。
Google News のエンコード済みURLは、実際には news.google.com 上で動的に解析されており、ユーザがアクセスすると、特定のパラメータ(signature、timestamp、Base64文字列)を参照して元のニュース記事URLへリダイレクトされます。
このメソッドでは、それと同じ手続きをプログラム側から直接呼び出すことで、オリジナルのURLを取り出しています。
まず、signature(署名)と timestamp(タイムスタンプ)、そしてパス部分から抽出したBase64文字列を組み合わせ、payload というJSON形式のリクエストボディを生成します。
実際の送信内容は f.req= というキーでパッケージ化された文字列となり、quote(json.dumps([[payload]])) のように二重リスト構造を持つJSONをURLエンコードしつつ、POSTボディへセットしています。
なお、オリジナルのコードでは requests ライブラリを使用していますが、Lambda関数で実行するために、標準である urllib.request を使用するように改変しています。
DotsSplashUi エンドポイントは、Google Newsの内部機構で様々な操作を一括で処理する役割を持つと考えられ、今回のデコード処理もその一機能と考えられます。
POST後のレスポンスで複数のJSONブロックが文字列として返ってくるため、コードでは split("\n\n") で文字列を分割し、さらに json.loads を駆使して解析を進めます。
レスポンスの解析をこのコードで進めると、実際に必要な情報は splitted[1] に入り、その中から [0][2] に相当する配列要素を取り出すことで、最終的に復元された元のURLが取得できる仕組みです。
def decode_url(self, signature, timestamp, base64_str):
try:
logger.debug(f"decode_url: 処理開始。signature: {signature}, timestamp: {timestamp}, base64_str: {base64_str}")
url = "https://news.google.com/_/DotsSplashUi/data/batchexecute"
payload = [
"Fbv4je",
f'["garturlreq",[["X","X",["X","X"],null,null,1,1,"US:en",null,1,null,null,null,null,null,0,1],"X","X",1,[1,1,1],1,1,null,0,0,null,0],"{base64_str}",{timestamp},"{signature}"]',
]
headers = {
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
}
data = f"f.req={quote(json.dumps([[payload]]))}".encode("utf-8")
logger.debug(f"decode_url: POST するデータ: {data}")
req = urllib.request.Request(url, data=data, headers=headers, method="POST")
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
logger.debug("decode_url: POST リクエスト成功")
response_text = response.read().decode("utf-8")
splitted = response_text.split("\n\n")
logger.debug(f"decode_url: レスポンステキストの先頭部分: {splitted[0][:200]}")
parsed_data = json.loads(splitted[1])[:-2]
decoded_url = json.loads(parsed_data[0][2])[1]
logger.debug(f"decode_url: デコードされた URL: {decoded_url}")
return {"status": True, "decoded_url": decoded_url}
except (urllib.error.HTTPError, urllib.error.URLError) as req_err:
message = f"Request error in decode_url: {str(req_err)}"
logger.error(message)
return {"status": False, "message": message}
except (json.JSONDecodeError, IndexError, TypeError) as parse_err:
message = f"Parsing error in decode_url: {str(parse_err)}"
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("decode_url 内でエラーが発生")
return {"status": False, "message": f"Error in decode_url: {str(e)}"}
こうして返されるURLは、Google Newsで一度中継される前の、正真正銘のオリジナルのニュースサイトのURLとなります。
signature や timestamp が適切でない場合や、Google News側の仕様変更があった場合などはエラーが返されますが、そのような例外も含めてコード側でハンドリングするようになっており、APIの応答次第でステータスやメッセージを返す流れが組み込まれています。
decode_google_news_url
ここまで紹介してきた各メソッドを統合し、ユーザから受け取ったGoogle NewsのURLを一貫して処理するのが decode_google_news_url です。
このメソッドは、get_base64_str でBase64文字列を抽出し、get_decoding_params で署名とタイムスタンプを取得し、さらに decode_url によって最終的な元記事URLをデコードする手順をオーケストレーションしています。
必要に応じて任意の秒数だけ実行を遅延させる interval パラメータは、外部APIへのアクセス頻度を制御してレートリミットやサーバ負荷の問題を緩和するために使用します。
def decode_google_news_url(self, source_url, interval=None):
try:
logger.debug(f"decode_google_news_url: 処理開始。source_url: {source_url}")
base64_response = self.get_base64_str(source_url)
if not base64_response["status"]:
logger.error("decode_google_news_url: get_base64_str でエラー")
return base64_response
decoding_params_response = self.get_decoding_params(base64_response["base64_str"])
if not decoding_params_response["status"]:
logger.error("decode_google_news_url: get_decoding_params でエラー")
return decoding_params_response
decoded_url_response = self.decode_url(
decoding_params_response["signature"],
decoding_params_response["timestamp"],
decoding_params_response["base64_str"],
)
if interval:
logger.debug(f"decode_google_news_url: {interval}秒のディレイを実施")
time.sleep(interval)
logger.debug(f"decode_google_news_url: デコード結果: {decoded_url_response}")
return decoded_url_response
except Exception as e:
logger.exception("decode_google_news_url 内でエラーが発生")
return {"status": False, "message": f"Error in decode_google_news_url: {str(e)}"}
最初の get_base64_str で弾かれた場合は後続ステップに進まず、パラメータが取得できなければ decode_url を呼び出さないようにすることで、例外が連鎖的に発生するのを防いでいます。
こうした段階的なエラー判定は、コードの見通しを良くして、トラブルシューティングを簡素化することに役立ちます。
AWS Lambda ハンドラー
AWS Lambda 上でこの機能を呼び出すために、オリジナルコードに追記して lambda_handler を実装しています。
イベントに含まれる source_url、interval、proxy、debug などのパラメータを使って GoogleDecoder を構築し、最終的に decode_google_news_url を呼び出して結果を返す流れが下記のとおり実装されています。
def lambda_handler(event, context):
"""
AWS Lambda のエントリポイント
イベント例:
{
"source_url": "https://news.google.com/rss/articles/・・・",
"interval": 5, # オプション: レート制限回避のための待機秒数
"proxy": "http://user:password@localhost:8080", # オプション: プロキシ設定
"debug": true # オプション: デバッグモード有効化
}
"""
source_url = event.get("source_url")
interval = event.get("interval")
proxy = event.get("proxy")
debug = event.get("debug", False)
if not source_url:
return {"status": False, "message": "source_url パラメータが提供されていません。"}
decoder = GoogleDecoder(proxy=proxy, debug=debug)
result = decoder.decode_google_news_url(source_url, interval=interval)
return result
外部からはJSONベースでパラメータを渡すようにして、環境変数などを気にすることなく、柔軟に設定を切り替えることができるようにしています。
戻り値も同様にJSON形式であり、他のシステムと組み合わせて使いやすくなっています。
エラーハンドリングとログ出力
このコードでは、想定されるエラー(HTTPエラー、URLエラー、JSONパースエラーなど)にきめ細かく対処するため、オリジナルのコードに追記する形で、複数の except 節を実装しています。
エラーが起きた箇所をログの内容から即座に特定できるよう、メソッド名と要因をセットで記録するように工夫しています。
デバッグモード時には、より詳しい情報を取得できます。
コードの全体
以下は、オリジナルのコードを参考に、AWSのLambda関数で実行できるように改変を加えたコードの全体です。
import json
import time
import logging
import re
from urllib.parse import quote, urlparse
import urllib.request
import urllib.error
# モジュールレベルのロガー設定
logger = logging.getLogger(__name__)
class GoogleDecoder:
def __init__(self, proxy=None, debug=False):
"""
GoogleDecoder クラスの初期化
Parameters:
proxy (str, optional): リクエストで使用するプロキシ。例: "http://user:pass@host:port"
debug (bool, optional): デバッグモードを有効にするかどうか。
"""
self.proxy = proxy
self.proxies = {"http": proxy, "https": proxy} if proxy else None
self.debug = debug
if self.debug:
logger.setLevel(logging.DEBUG)
else:
logger.setLevel(logging.INFO)
logger.debug(f"GoogleDecoder 初期化完了。proxy: {proxy}, debug: {debug}")
def _build_opener(self):
"""
プロキシ設定がある場合は ProxyHandler を用いて opener を構築する。
"""
if self.proxies:
proxy_handler = urllib.request.ProxyHandler(self.proxies)
opener = urllib.request.build_opener(proxy_handler)
else:
opener = urllib.request.build_opener()
return opener
def get_base64_str(self, source_url):
"""
Google News の URL から Base64 文字列を抽出する。
Parameters:
source_url (str): Google News の記事 URL。
Returns:
dict: 成功時は 'status' と 'base64_str' を、失敗時は 'status' と 'message' を含む。
"""
try:
logger.debug(f"get_base64_str: 処理開始。source_url: {source_url}")
parsed_url = urlparse(source_url)
path = parsed_url.path.split("/")
logger.debug(f"get_base64_str: URL パス分割結果: {path}")
if (
parsed_url.hostname == "news.google.com"
and len(path) > 1
and path[-2] in ["articles", "read"]
):
base64_str = path[-1]
logger.debug(f"get_base64_str: 抽出された Base64 文字列: {base64_str}")
return {"status": True, "base64_str": base64_str}
message = "Invalid Google News URL format."
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("get_base64_str 内でエラーが発生")
return {"status": False, "message": f"Error in get_base64_str: {str(e)}"}
def get_decoding_params(self, base64_str):
"""
Google News からデコードに必要な signature と timestamp を取得する。
まず、https://news.google.com/articles/{base64_str} を試み、エラーがあれば
https://news.google.com/rss/articles/{base64_str} を試す。
Parameters:
base64_str (str): 抽出された Base64 文字列。
Returns:
dict: 成功時は 'status', 'signature', 'timestamp', 'base64_str' を含み、
失敗時は 'status' と 'message' を含む。
"""
try:
url = f"https://news.google.com/articles/{base64_str}"
logger.debug(f"get_decoding_params: articles URL を試行: {url}")
req = urllib.request.Request(url)
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
text = response.read().decode("utf-8")
logger.debug("get_decoding_params: articles URL からのレスポンス取得成功")
# 正規表現で data-n-a-sg と data-n-a-ts の値を抽出
signature_match = re.search(r'data-n-a-sg="([^"]+)"', text)
timestamp_match = re.search(r'data-n-a-ts="([^"]+)"', text)
if not signature_match or not timestamp_match:
message = "Failed to extract data attributes from Google News with the articles URL."
logger.error(message)
return {"status": False, "message": message}
signature = signature_match.group(1)
timestamp = timestamp_match.group(1)
logger.debug(f"get_decoding_params: 取得した signature: {signature}, timestamp: {timestamp}")
return {
"status": True,
"signature": signature,
"timestamp": timestamp,
"base64_str": base64_str,
}
except (urllib.error.HTTPError, urllib.error.URLError) as req_err:
logger.warning(f"get_decoding_params: articles URL でエラーが発生: {req_err}")
# fallback: RSS URL を試す
try:
url = f"https://news.google.com/rss/articles/{base64_str}"
logger.debug(f"get_decoding_params: fallback RSS URL を試行: {url}")
req = urllib.request.Request(url)
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
text = response.read().decode("utf-8")
logger.debug("get_decoding_params: RSS URL からのレスポンス取得成功")
signature_match = re.search(r'data-n-a-sg="([^"]+)"', text)
timestamp_match = re.search(r'data-n-a-ts="([^"]+)"', text)
if not signature_match or not timestamp_match:
message = "Failed to extract data attributes from Google News with the RSS URL."
logger.error(message)
return {"status": False, "message": message}
signature = signature_match.group(1)
timestamp = timestamp_match.group(1)
logger.debug(f"get_decoding_params: fallback で取得した signature: {signature}, timestamp: {timestamp}")
return {
"status": True,
"signature": signature,
"timestamp": timestamp,
"base64_str": base64_str,
}
except (urllib.error.HTTPError, urllib.error.URLError) as rss_err:
message = f"Request error in get_decoding_params with RSS URL: {str(rss_err)}"
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("get_decoding_params 内で予期しないエラーが発生")
return {"status": False, "message": f"Unexpected error in get_decoding_params: {str(e)}"}
def decode_url(self, signature, timestamp, base64_str):
"""
signature と timestamp を用いて、Google News の URL をデコードする。
Parameters:
signature (str): デコードに必要な signature。
timestamp (str): デコードに必要な timestamp。
base64_str (str): Google News の URL から抽出された Base64 文字列。
Returns:
dict: 成功時は 'status' と 'decoded_url'、失敗時は 'status' と 'message' を含む。
"""
try:
logger.debug(f"decode_url: 処理開始。signature: {signature}, timestamp: {timestamp}, base64_str: {base64_str}")
url = "https://news.google.com/_/DotsSplashUi/data/batchexecute"
payload = [
"Fbv4je",
f'["garturlreq",[["X","X",["X","X"],null,null,1,1,"US:en",null,1,null,null,null,null,null,0,1],"X","X",1,[1,1,1],1,1,null,0,0,null,0],"{base64_str}",{timestamp},"{signature}"]',
]
headers = {
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
}
data = f"f.req={quote(json.dumps([[payload]]))}".encode("utf-8")
logger.debug(f"decode_url: POST するデータ: {data}")
req = urllib.request.Request(url, data=data, headers=headers, method="POST")
opener = self._build_opener()
response = opener.open(req)
if response.getcode() != 200:
raise Exception("HTTP status code not 200")
logger.debug("decode_url: POST リクエスト成功")
response_text = response.read().decode("utf-8")
splitted = response_text.split("\n\n")
logger.debug(f"decode_url: レスポンステキストの先頭部分: {splitted[0][:200]}")
parsed_data = json.loads(splitted[1])[:-2]
decoded_url = json.loads(parsed_data[0][2])[1]
logger.debug(f"decode_url: デコードされた URL: {decoded_url}")
return {"status": True, "decoded_url": decoded_url}
except (urllib.error.HTTPError, urllib.error.URLError) as req_err:
message = f"Request error in decode_url: {str(req_err)}"
logger.error(message)
return {"status": False, "message": message}
except (json.JSONDecodeError, IndexError, TypeError) as parse_err:
message = f"Parsing error in decode_url: {str(parse_err)}"
logger.error(message)
return {"status": False, "message": message}
except Exception as e:
logger.exception("decode_url 内でエラーが発生")
return {"status": False, "message": f"Error in decode_url: {str(e)}"}
def decode_google_news_url(self, source_url, interval=None):
"""
Google News の記事 URL を元のソース URL にデコードする。
Parameters:
source_url (str): Google News の記事 URL。
interval (int, optional): レート制限回避のためのディレイ(秒)。
Returns:
dict: 成功時は 'status' と 'decoded_url'、失敗時は 'status' と 'message' を含む。
"""
try:
logger.debug(f"decode_google_news_url: 処理開始。source_url: {source_url}")
base64_response = self.get_base64_str(source_url)
if not base64_response["status"]:
logger.error("decode_google_news_url: get_base64_str でエラー")
return base64_response
decoding_params_response = self.get_decoding_params(base64_response["base64_str"])
if not decoding_params_response["status"]:
logger.error("decode_google_news_url: get_decoding_params でエラー")
return decoding_params_response
decoded_url_response = self.decode_url(
decoding_params_response["signature"],
decoding_params_response["timestamp"],
decoding_params_response["base64_str"],
)
if interval:
logger.debug(f"decode_google_news_url: {interval}秒のディレイを実施")
time.sleep(interval)
logger.debug(f"decode_google_news_url: デコード結果: {decoded_url_response}")
return decoded_url_response
except Exception as e:
logger.exception("decode_google_news_url 内でエラーが発生")
return {"status": False, "message": f"Error in decode_google_news_url: {str(e)}"}
def lambda_handler(event, context):
"""
AWS Lambda のエントリポイント
イベント例:
{
"source_url": "https://news.google.com/rss/articles/・・・",
"interval": 5, # オプション: レート制限回避のための待機秒数
"proxy": "http://user:password@localhost:8080", # オプション: プロキシ設定
"debug": true # オプション: デバッグモード有効化
}
"""
source_url = event.get("source_url")
interval = event.get("interval")
proxy = event.get("proxy")
debug = event.get("debug", False)
if not source_url:
return {"status": False, "message": "source_url パラメータが提供されていません。"}
decoder = GoogleDecoder(proxy=proxy, debug=debug)
result = decoder.decode_google_news_url(source_url, interval=interval)
return result
# # ローカルデバッグ用(コメントアウト)
# if __name__ == "__main__":
# test_event = {
# "source_url": "https://news.google.com/rss/articles/CBMiqwFBVV95cUxNMTRqdUZpNl9hQldXbGo2YVVLOGFQdkFLYldlMUxUVlNEaElsYjRRODVUMkF3R1RYdWxvT1NoVzdUYS0xSHg3eVdpTjdVODQ5cVJJLWt4dk9vZFBScVp2ZmpzQXZZRy1ncDM5c2tRbXBVVHVrQnpmMGVrQXNkQVItV3h4dVQ1V1BTbjhnM3k2ZUdPdnhVOFk1NmllNTZkdGJTbW9NX0k5U3E2Tkk?oc=5",
# "interval": 5,
# "proxy": None,
# "debug": True
# }
# print(lambda_handler(test_event, None))
応用例
本記事でご紹介した、AWSのLambda関数でGoogle NewsのURLを解析してオリジナルのURLを得る技術は、それ単体でも十分に有用ですが、様々な応用例が考えられます。
たとえば、AWSの生成AIサービスと組み合わせることで、さらなる価値を生み出すことが可能になります。
オリジナルのURLが得られれば、記事内容を得ることも容易となり、Amazon Bedrockで提供される様々な基盤モデル(Amazon Nova、Anthropicの提供するClaudeシリーズ、Cohereのモデルなど)を活用することで、公開情報を分析したり、ユーザーの関心に応じてパーソナライズしたり、情報を要約して表示したりできます。
リアルタイムで得られたGoogle NewsのURLをLambdaでデコードし、取得可能な公開情報をAmazon Bedrock上の大規模言語モデルに送り込めば、リアルタイムな「情報分析・要約」や「キーポイントの抽出」も行えます。
以下は、応用例を実現するアーキテクチャのサンプルです。
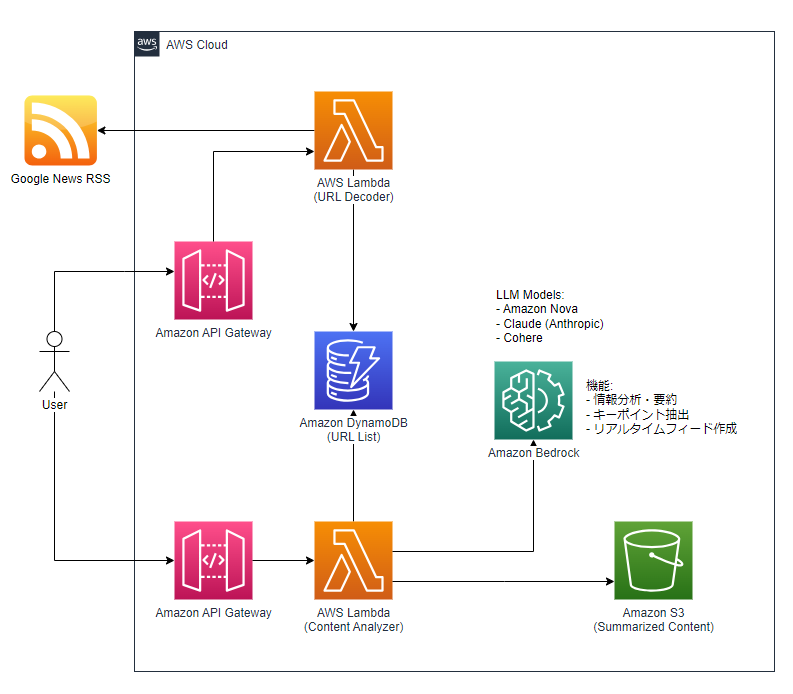
また、AIエージェントの技術と組み合わせることで、最新情報を参考にした資料の作成にも役立つことでしょう。
たとえば、Amazon Bedrock Agentを活用し、AIエージェントから適切に呼べるよう工夫すれば、様々かつ高度な応用が期待できます。
まとめ
AWSのLambda関数でGoogle NewsのRSSに含まれる特殊なURLを実際のニュース記事リンクへと復元するための作法を、コードを通じて解説しました。
Google NewsのRSSは、最新のニュースからトレンドを把握するために使用されるケースが多いと思われます。
今回、オリジナルのコードを読み解きながらLambdaで動くように改変する作業の中で、その仕組みの裏側が分かり、RSSに書かれたURLからBase64文字列を抽出し、署名やタイムスタンプを取得して内部APIにリクエストを送り、最終的に返されたオリジナルのURLに戻してアクセスしている事実を知ることができました。
今回、AWS上での応用例を紹介してイメージを深めましたが、Lambda関数を通じてGoogle NewsのURLからオリジナルのURLを得るこの方法は、トレンド記事をデータベース化したり、生成AIなどを活用して記事を分析したりする際に役立つのではないかと思われます。
参考文献
- Google News Decoder (本記事で掲載したコードのオリジナル)
- Google ニュースのRSSから元記事のURLを手にいれる(実用には耐えない)