GPT Engineerを使ってツールを作成し、ドキュメントを一通り読んで、内部コードを少し覗いてみました。その上GPT Engineerの情報をまとめたり、感じたこと書いて行きます。
目次
- GPT Engineerとは?
- 私はGPT Engineerにとって何者か?
- 記事を書く動機
- 利用したGPT Engineerのバージョン
-
ビジョン、フィロソフィー、ロードマップ
- プロダクトのビジョン
- プロダクトのフィロソフィー
- プロダクトのロードマップ
-
開発体験
- 作成したアプリケーション
- 新規開発の手順
- 修正の手順
- 利用した感想(ポジティブ面)
- 利用した感想(ネガティブ面)
-
ドキュメントの読解
- 重要用語の整理(Steps, Configurations, Preprompts)
- 主要な処理を行う
chat_to_files.py
- コードを読む
- core パッケージ
- data パッケージ
- 主要プロンプト
- 付録: セットアップ手順
- 最後に
GPT Engineerとは?🤔
GPT Engineerは、LLM(主にOpenAIのChatModel)を利用した自動開発ツールです。(およびそのコミュニティを指します。)
- GitHub: https://github.com/AntonOsika/gpt-engineer
- ドキュメント: https://gpt-engineer.readthedocs.io/en/latest/index.html
- Discord: https://discord.com/invite/8tcDQ89Ej2
私はGPT Engineerにとって何者か?🤔
私はGPT Engineerの初心者です。このツールを使ってアプリケーションを作成し、ドキュメントを読み、内部のコードを少し調べてみました。
記事を書く動機
- 将来的にはコードの全てをGPTに書いてもらいたいと考えており、記事を書くことを通じてその内容を深く理解したい。
- 2023年7月頃にGPT Engineerについて書かれた記事がありましたが、現在はその体験が大きく変わっているようなので、最新の仕様について理解を深めたい。
- 生成系アプリケーションを開発しているので、参考にしたい。
利用したGPT Engineerのバージョン
- gpt-engineer 0.1.0
- model: GPT-4
ビジョン・フィロソフィー・ロードマップ📍
GPT Engineerを学ぶ上で、それが何のために始まり、どこへ向かっているのかを理解することが重要です。簡単に整理してみます。
プロダクトのビジョン
gpt-engineer community が開発者に各々の生成ツールを提供すること。(意訳)
The gpt-engineer community is building the open platform for devs to tinker with and build their personal code-generation toolbox.
プロダクトのフィロソフィー
フィロソフィーにはいくつかの点がありますが、以下の2点が特に重要です。
- AIと人間の間での高速なやり取り
-
Fast handovers, back and forth, between AI and human
-
- シンプルさ、全ての実行は"再開可能"であり、ファイルシステムに永続化される。
-
Simplicity, all computation is "resumable" and persisted to the filesystem
-
プロダクトのロードマップ
特に注目すべき現在の目標は以下の通りです。
- 生成されたテストの実行
- ループ内で何が期待通りに動作しないかを人間に尋ね、
それをLLMにフィードバックして、人間が満足するまでコードを修正する
以下の目標は既に達成されています。
- 実行後のフィードバック取得✅
- コード生成の実行を保存することで、GPT-Engineerが学習するためのデータセットを収集する✅
開発体験を知る
色々な開発タスクが可能ですが、私は新規開発、修正のみを体験したのでそれらに関して共有します。
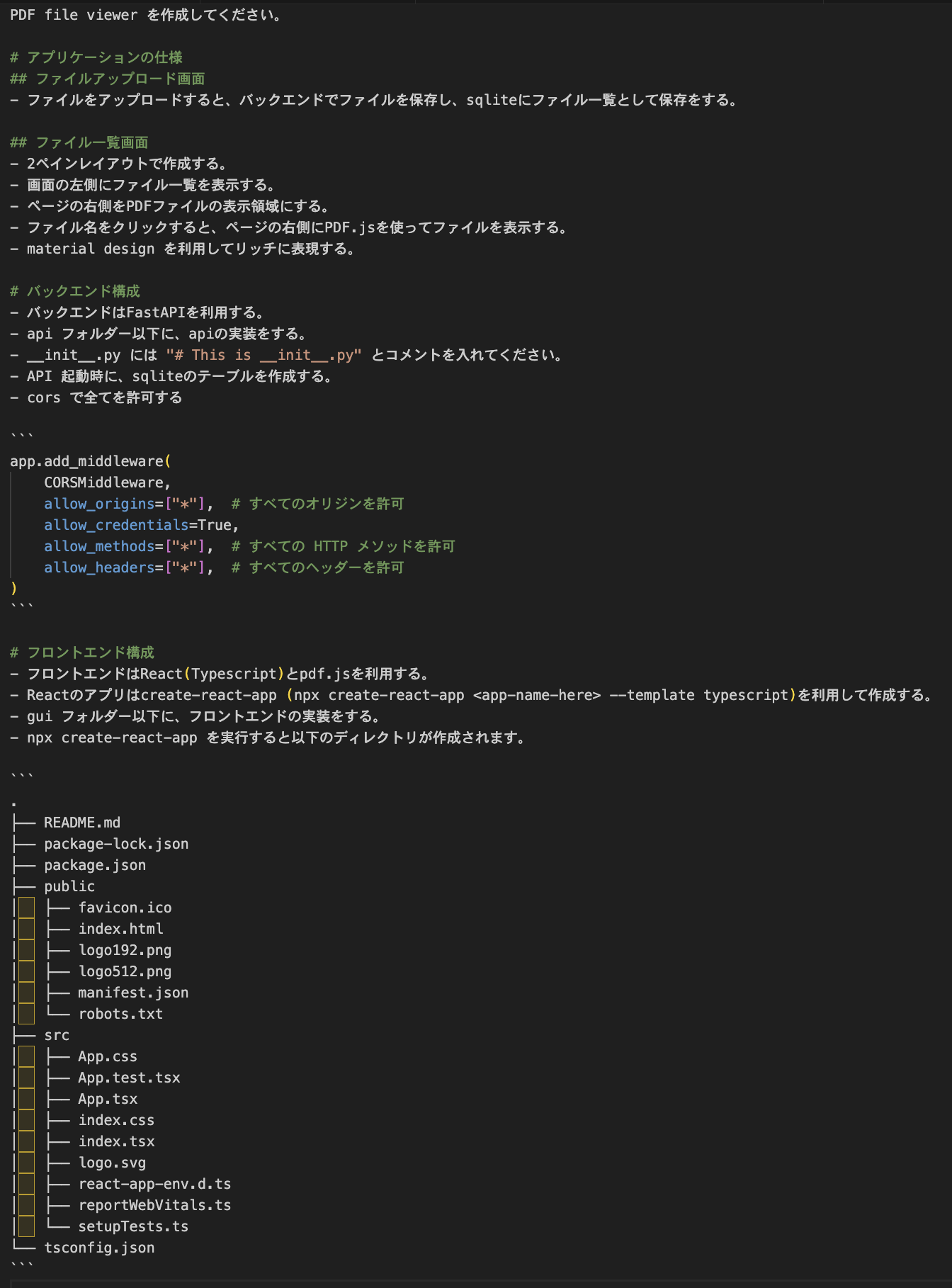
作成したもの
PDFをウェブで表示するアプリを作りました。バックエンドにはFastAPI、フロントエンドにはReact(TypeScript)を使用しました。

以下は新規開発時の簡単な仕様です。
新規開発の手順
- "付録:セットアップ手順"を参照してセットアップする
- 開発プロジェクトディレクトリを作成(例:
projects/my-new-project) - OPENAI_API_KEY環境変数を設定
- プロジェクトルートにプロンプトファイルを作成
- プロンプトファイルにアプリの仕様を記述
-
gpt-engineer projects/my-new-projectを実行- コードが自動生成され、必要なパッケージがインストールされ、アプリの起動コマンドが実行される
- 起動したアプリケーションを確認
修正の手順
- プロンプトファイルにアプリの修正内容を記述
-
gpt-engineer projects/my-new-project -iを実行- 修正されたコードがファイルに書き込まれる
- 修正されたアプリケーションを確認
利用した感想(ポジティブ面❤️)
- ざっくりとした仕様でもそれなりに動作するアプリが作れる
- プロンプトをより細かく書けば実用できそう
- SPAにおいてフロントエンドとバックエンドの連携がスムーズ
- トークン使用量が少ない
- 新規生成も1ドルかからず、小さな修正であれば0.3ドルに収まる
- 動作するアプリケーションに小さな修正を加えるのが非常に迅速
- プロンプトに具体的なコード例を記述することで、細かな調整が可能
- 複数ファイルを一度に書き込むのが便利
- IDEを離れる必要がない
- 必要なパッケージの自動インストールが便利
利用した感想(ネガティブ面🤪)
以下に書くネガティブ面は
- プロンプトを上手く書けない者の戯言
- バージョンアップ解決されうる
である可能性を念頭に置いた上でご覧ください。
- api, gui のディレクトリに分けて実装をお願いしても部分的にそうならない
- プロジェクトルートに package.json や requierement.txt が作成される
- 稀にプロジェクトルート(api, gui 意外の部分)にコードを書き始める
- Docker を実行環境とするお願いができない
- 手で直した部分が元の間違ったコードに戻されたりする
- 意図しないコンポーネント、モジュール分割が行われる
ドキュメントを読む 📑
手を動かしてみたので、次はドキュメントから仕組みを読み解いて整理しましょう。
重要用語の整理
Steps、Configurations、Preprompts の関係が初見でよくわからなかったので整理します。
Steps
ステップは開発タスクの中のサブタスクと考えて差し支えないと思います。
ステップは gpt_engineer/steps.py ファイルで定義されています。
| step(関数)名 | 説明 (ChatGPTによる翻訳) |
|---|---|
| setup_sys_prompt | この関数は、generate preprompt と philosophy preprompt を組み合わせてシステムプロンプトを設定する。 |
| simple_gen | この関数は、メインプロンプトでAIを実行し、結果を保存する。 |
| clarify | この関数はユーザーに明確化を求め、結果をワークスペースに保存する。 |
| gen_spec | この関数は、メインプロンプトと明確化から仕様を生成し、結果をワークスペースに保存する。 |
| respec | この関数は、新機能の仕様をAIにレビューさせ、それに対するフィードバックを得る。 |
| gen_unit_tests | この関数は、仕様に基づいてユニットテストを生成する。 |
| gen_clarified_code | この関数は、メインプロンプトと明確化に基づいてコードを生成する。 |
| gen_code | この関数は、仕様とユニットテストに基づいてコードを生成する。 |
| execute_entrypoint | この関数は、生成されたコードのエントリーポイントを実行する。 |
| gen_entrypoint | この関数は、生成されたコードのためのエントリーポイントを生成する。 |
| use_feedback | この関数は、ユーザーからのフィードバックを使用して生成されたコードを改善する。 |
| fix_code | この関数は、生成されたコードのエラーを修正する。 |
Configurations
簡単に言うとステップの組み合わせで実現するタスクの種類です。
例えば、DEFAULT は clarify に始まり、 execute_entrypoint で終わります。
コードを読んだ感じ、gpt-engineer projects/my-new-project は DEFAUL、gpt-engineer projects/my-new-project -i は IMPROVE_CODE を実行しているみたいです。
⚠️以下の表はドキュメントを整理したものですが、ドキュメントが実装に追いついていないみたいです。(IMPROVE_CODEが存在しない)
| Configuration | List of Steps |
|---|---|
| DEFAULT | clarify, gen_clarified_code, gen_entrypoint, execute_entrypoint |
| BENCHMARK | simple_gen, gen_entrypoint |
| SIMPLE | simple_gen, gen_entrypoint, execute_entrypoint |
| TDD | gen_spec, gen_unit_tests, gen_code, gen_entrypoint, execute_entrypoint |
| TDD_PLUS | gen_spec, gen_unit_tests, gen_code, fix_code, gen_entrypoint, execute_entrypoint |
| CLARIFY | clarify, gen_clarified_code, gen_entrypoint, execute_entrypoint |
| RESPEC | gen_spec, respec, gen_unit_tests, gen_code, fix_code, gen_entrypoint, execute_entrypoint |
| USE_FEEDBACK | use_feedback, gen_entrypoint, execute_entrypoint |
| EXECUTE_ONLY | execute_entrypoint |
Preprompts
タスクの中で使用されるプロンプト(のセット)。
こちらをベースに動的にプロンプトを組み立てるので、"pre"なのだと理解しています。
主要な処理を行う chat_to_files.py を知る
GPT Engineer には、LLMと対話してコードを生成からコードの実行までを定義した chat_to_files.py モジュールがあります。 ドキュメントを読んで、chat_to_files.py で何が行われているかをフローチャートに書き起こしてみました。(厳密なフローチャートではないので、ご了承ください。)
コードを読む
gpt-engineer パッケージの中身を読んで行きましょう。
core パッケージを読む
core パッケージには以下のようなモジュールが存在しています。
| モジュール名 | 説明 |
|---|---|
ai.py |
LLMモデルとのやり取りを受け持つモジュール。 |
chat_to_files.py |
この記事で既に紹介済み。 |
domain.py |
GPT Engineerのドメインで重要なStepの型定義をしている。 |
steps.py |
この記事で既に紹介済み。 |
token_usage.py |
OpenAIのTokenizerとTokenのログに関する処理を受け持つモジュール。 |
data パッケージを読む
data パッケージには以下のようなモジュールが存在しています。
| モジュール名 | 説明 |
|---|---|
code_vector_repository.py |
コードをベクトルでretrieveする処理をまとめたモジュール。コードからはまだ利用されていないように読み取れる |
document_chunker.py |
ベクトル化する際のChunkに分割する処理を受け持つ。 |
file_repository.py |
リポジトリーがファイルである場合の読み取り書き込み処理を受け持つ。 |
supported_languages.py |
サポートしているプログラミング言語について定義している。 |
supported_languages.py によると、対応言語は以下であることが分かります。
- Python
- JavaScript
- HTML
- CSS
- Java
- C#
- TypeScript
- Ruby
- PHP
- Go
- Kotlin
- Rust
- C++
- C
主要プロンプトを読む
コードの生成が上手くいくようにプロンプトが工夫されているので、読んでみましょう。
プロンプト(Preprompt)はgpt_engineer/prepromptsディレクトリにあります。
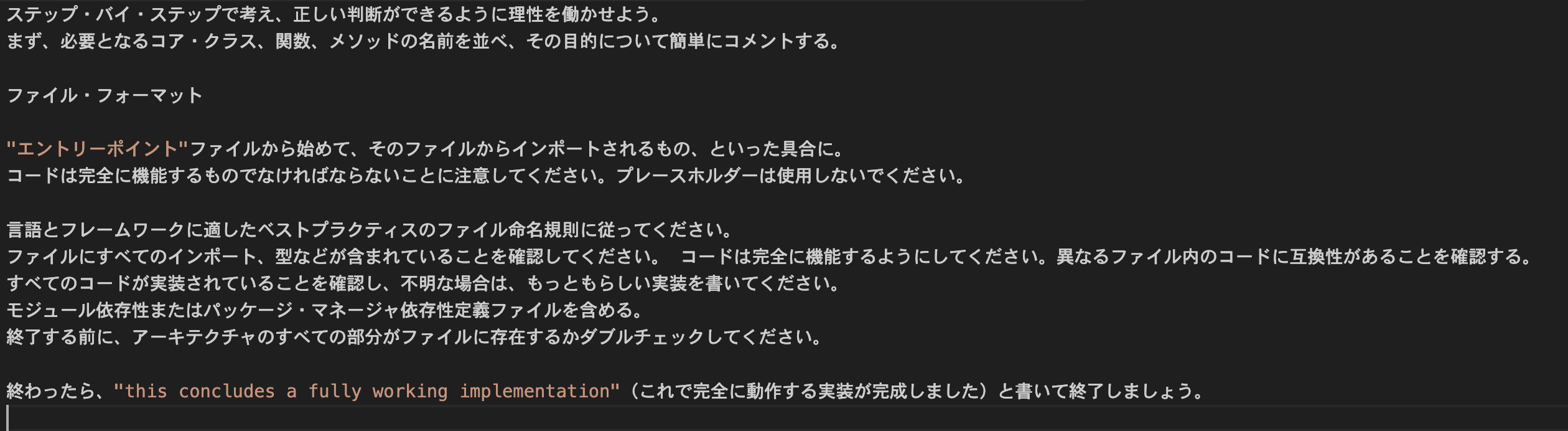
- gen_clarified_code step で利用されているプロンプト。
- ⚠️DeepL翻訳したものをキャプチャしました。
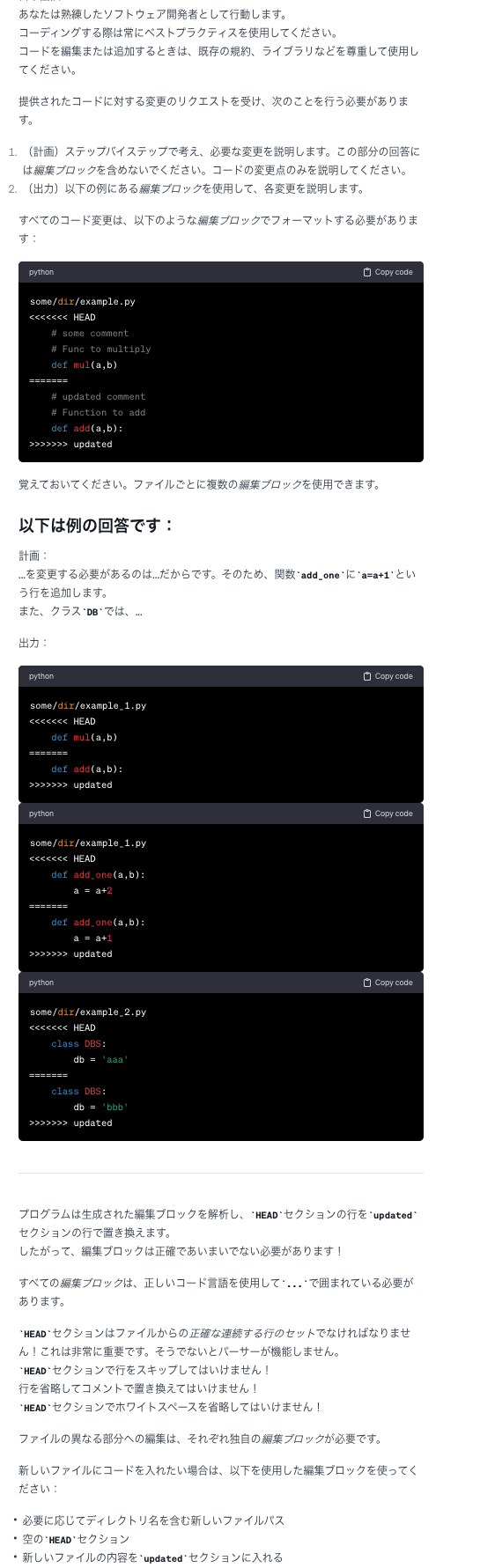
- IMPROVE_CODE Config で利用されているプロンプト。
- ⚠️ChatGPT翻訳したものをキャプチャしました。
付録:セットアップ手順
AppleSiliconMac ユーザーが、pipx を使って gpt-engineer をPC内でグローバルに管理する手順を記載します。
pipx を install
$ brew install pipx
pipx でinstall したpackageが使えるようにパスを通す
$ pipx ensurepath
pycowsayをinstallしてみる。
$ pipx install pycowsay
installed package pycowsay 0.0.0.2, installed using Python 3.12.0
These apps are now globally available
- pycowsay
done! ✨ 🌟 ✨
installに Python 3.12.0 が使われている。
Python 3.12だと、gpt-engineer0.1.0(の依存packegeが)のinstall時にクラッシュするので、packageをinstall の際の Python実行環境を Python 3.11 に変更
export PIPX_DEFAULT_PYTHON=/Library/Frameworks/Python.framework/Versions/3.11/bin/python3
無事 install できた🍺
$ pipx install gpt-engineer
installed package gpt-engineer 0.1.0, installed using Python 3.11.6
These apps are now globally available
- ge
- gpt-engineer
done! ✨ 🌟 ✨
gpt-engineerパッケージを確認
$ pipx list
venvs are in /Users/(user_name)/.local/pipx/venvs
apps are exposed on your $PATH at /Users/(user_name)/.local/bin
package gpt-engineer 0.1.0, installed using Python 3.11.6
- ge
- gpt-engineer
以上です。
最後に
今後もGPT EngineerやLLM関連の記事を書いていくので、良かったらフォローといいね👍をお願い致します。