機械学習を活用した計算処理の定期バッチを監視し始めて1ヶ月経ったので、アウトプットしてみる。
![]() 前提
前提![]()
- 機械学習・GCP(GCE + Stackdriver Monitoring)・Slackに関わる話がメイン
- Stackdriver Monitoringの細かな設定方法は省略
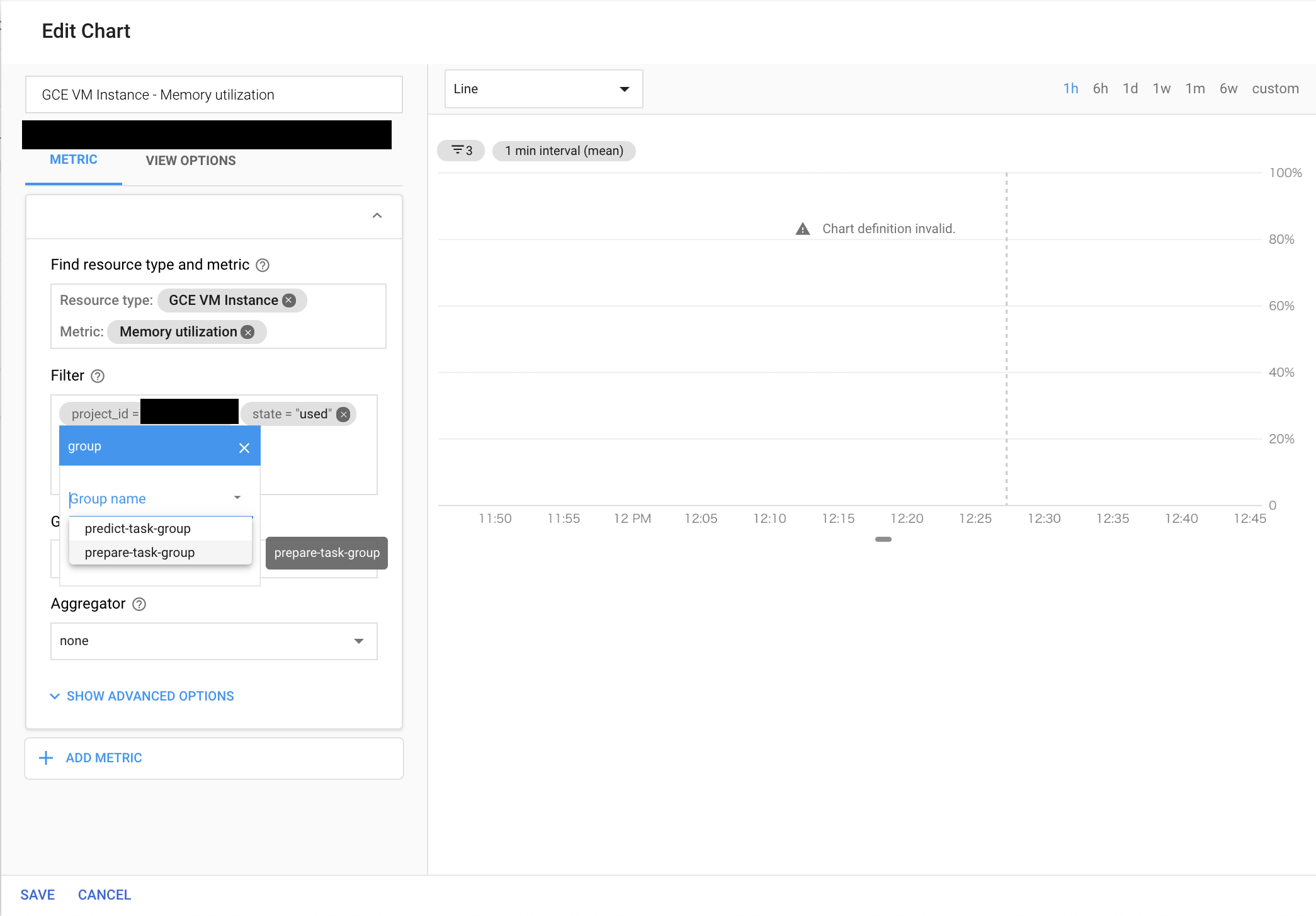
Tips1:タスク別に監視する
1GCEインスタンス:1タスクが前提。
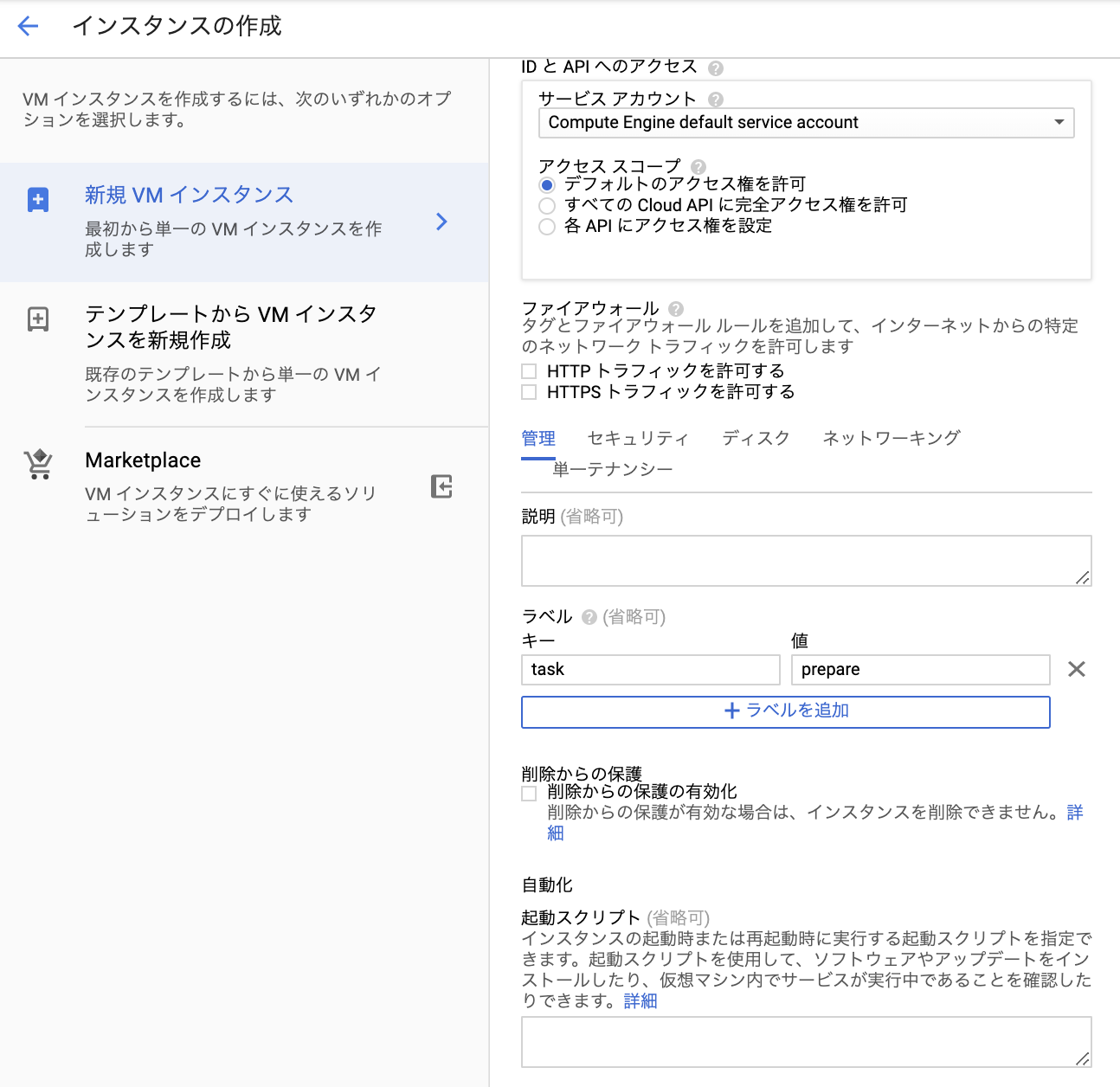
GCEインスタンスにタスク別にタグをつけることによりタスク別に監視設定を作ることができる。
なぜタスク別に監視するのか
- GCEを使っていなくても、内部的にGCEを使っているサービス?のモニタリングデータが混ざってくる
- GAE/FEを同GCPプロジェクト内で使用している際にモニタリングデータが混ざってきた
- タスク毎に理想の処理時間やリソースを使い切りの程度が異なるので、タスク毎に異なるAlertPolicyを作成するべきだから
手順
-
タスク別に監視できていない状態
-
-
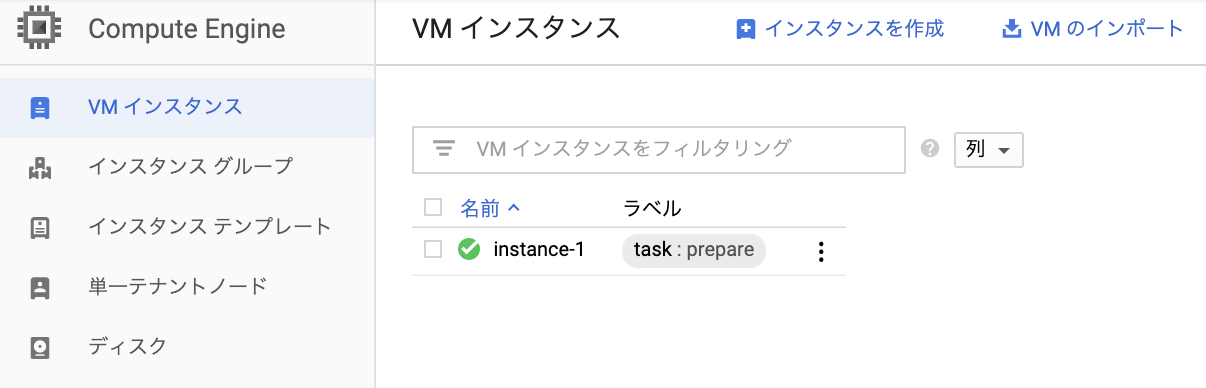
インスタンスにタグをつける(タスク毎に分類したタグを使用)
-
-
インスタンスにタグが着いたことを確認
-
-
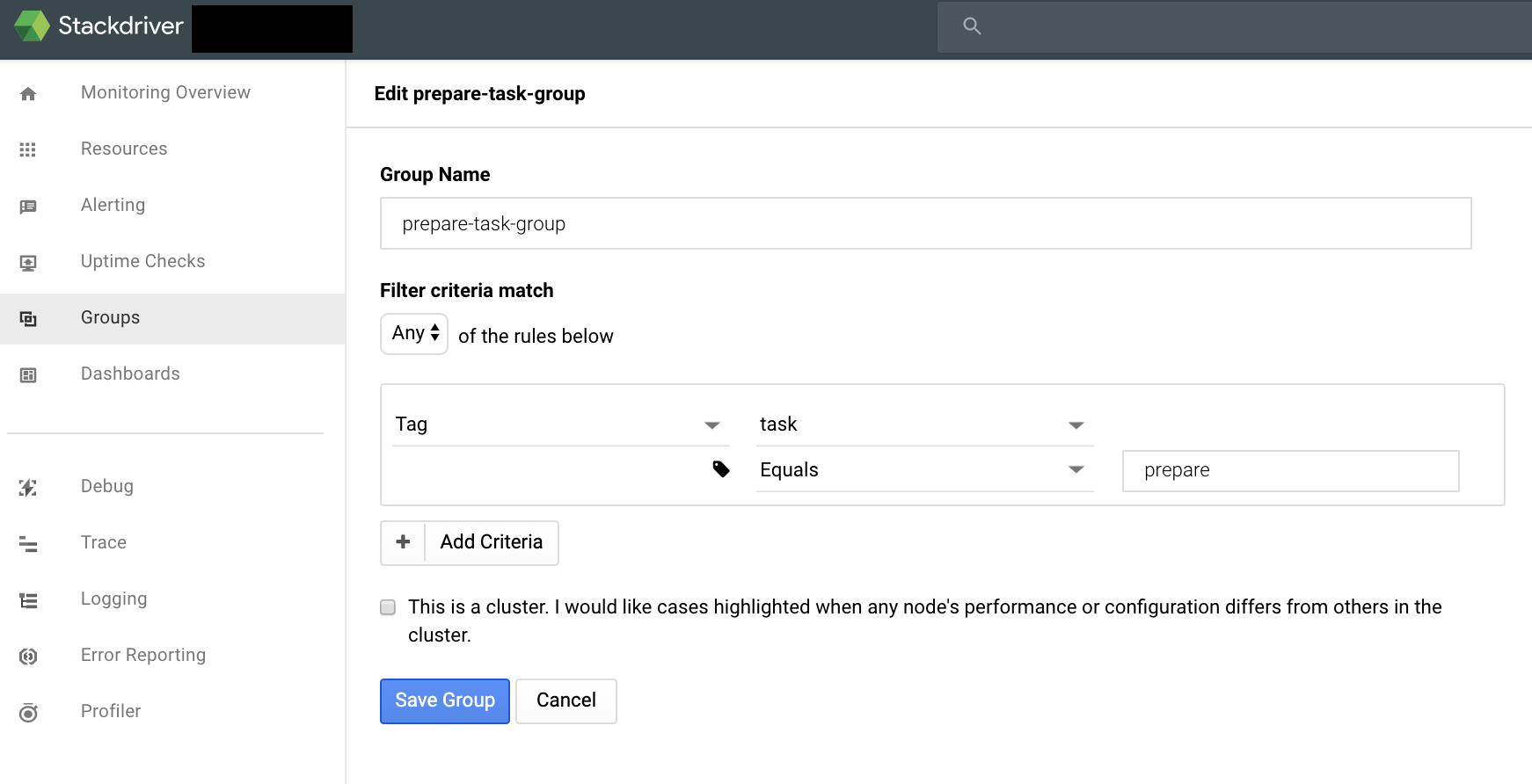
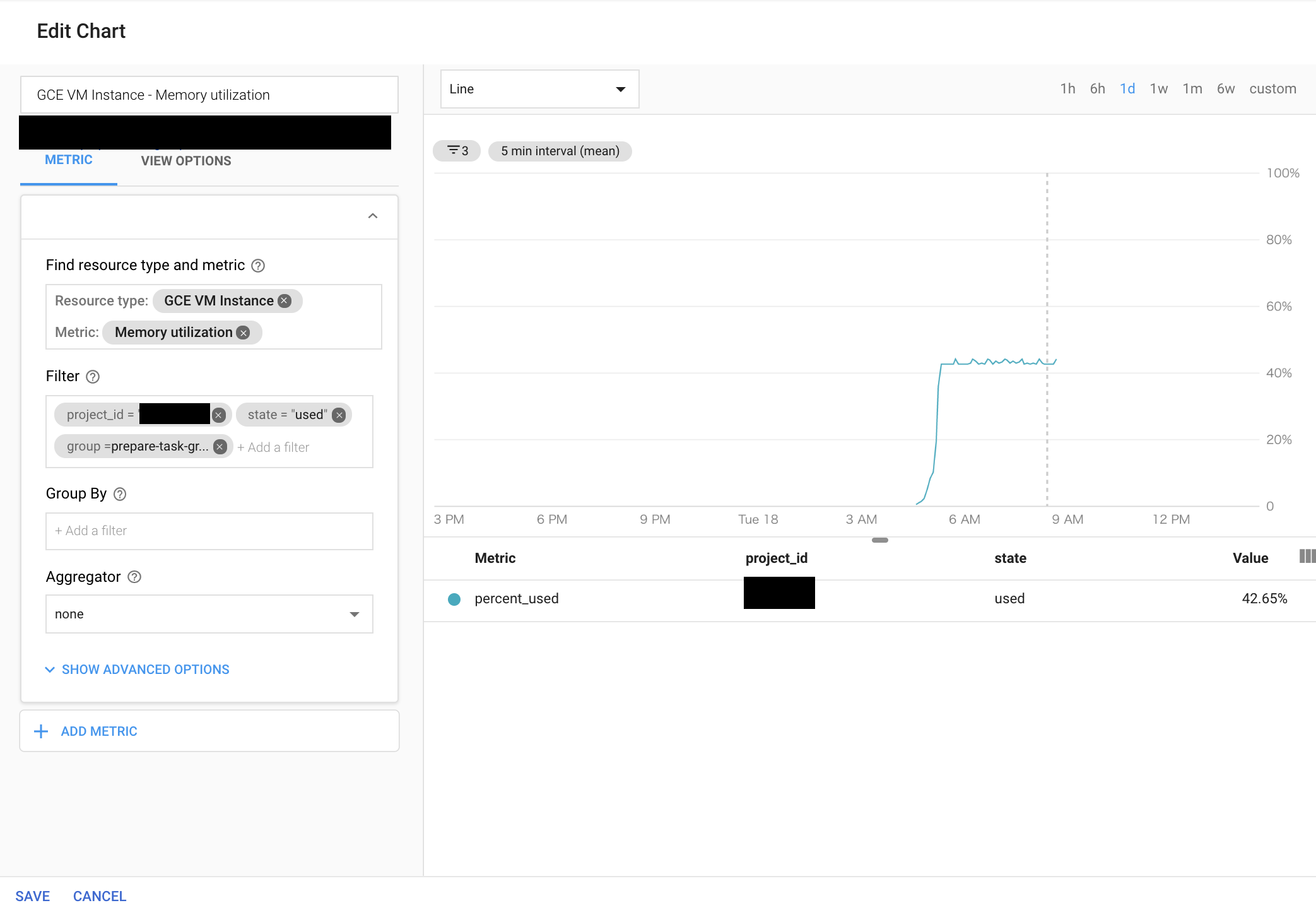
タスク毎にStackdriverMonitoringグループを作成する
- この際、タグが着いたインスタンスが存在していないと、グループを作成する際の条件にTagが表示されない
-
-
DashBoardやAlertを作成する際の条件でStackdriverMonitoringグループを指定する
-
-
タスク別にモニタリングデータを絞りこ込めたことを確認
-
Tips2:StackdriverMonitoringのSlackアプリを使用してお知らせする
なぜアプリを使うのか(webhookではダメなのか)
- Slackに通知した際にincident発生なのか、incident stoppedなのか分かりやすい
-

手順
-
https://www.topgate.co.jp/gcp19-stackdriver-monitoring-notify-mail-slack
- topgateさんの説明が分かりやすいので見てくださいw
Tips3:処理時間の監視設定
タスク毎にGCEインスタンスをcreateしてshutdownするのが前提だが、Uptime(稼働時間)を処理時間と読み替えて設定する。
手順
- Metricの
Uptimeを選択する- threshold(閾値)を1に設定し、任意の時間とConditionを設定する
- 単位がms/sなのでthresholdを1にして運用している
-
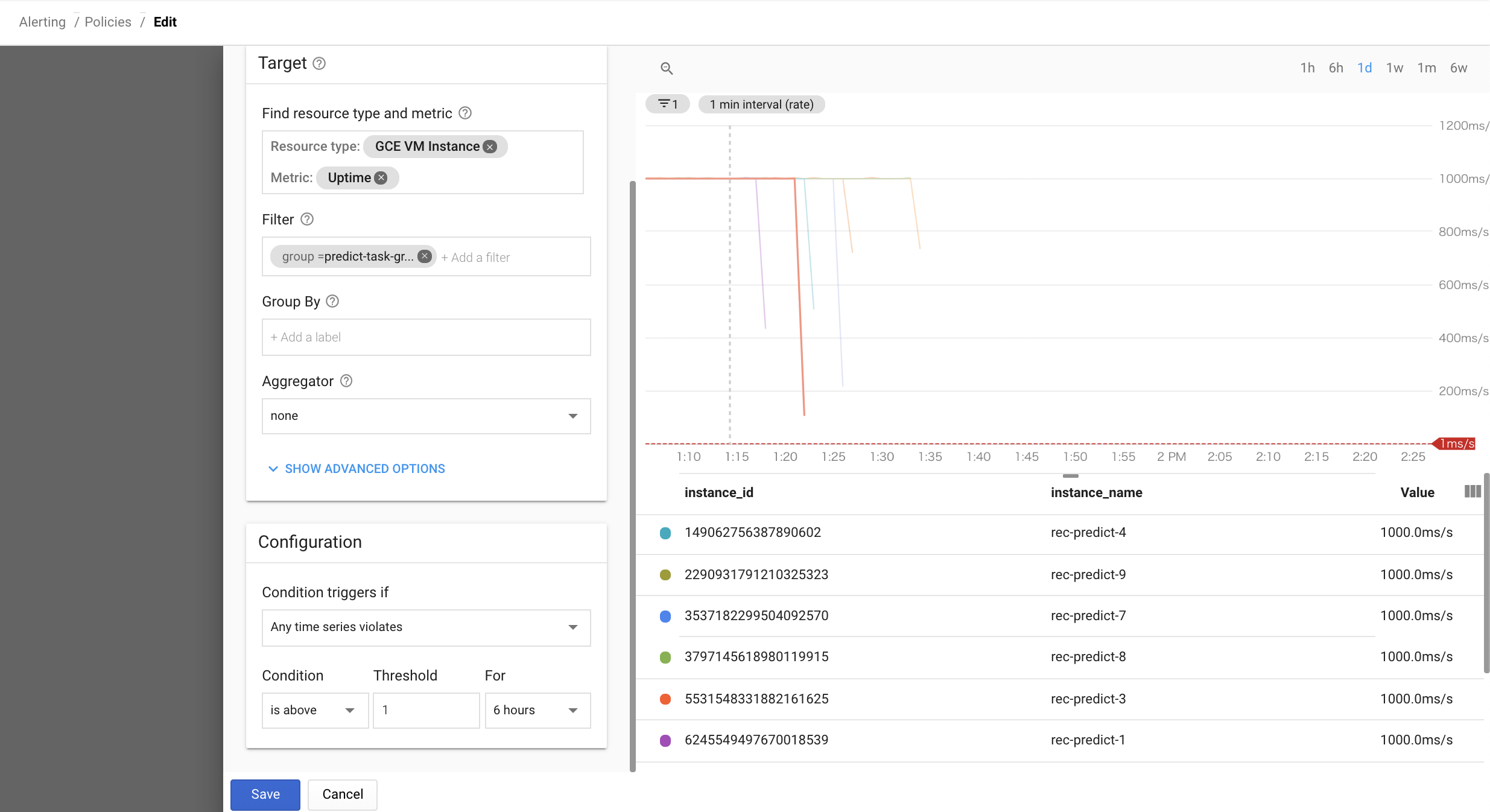
- threshold(閾値)を1に設定し、任意の時間とConditionを設定する
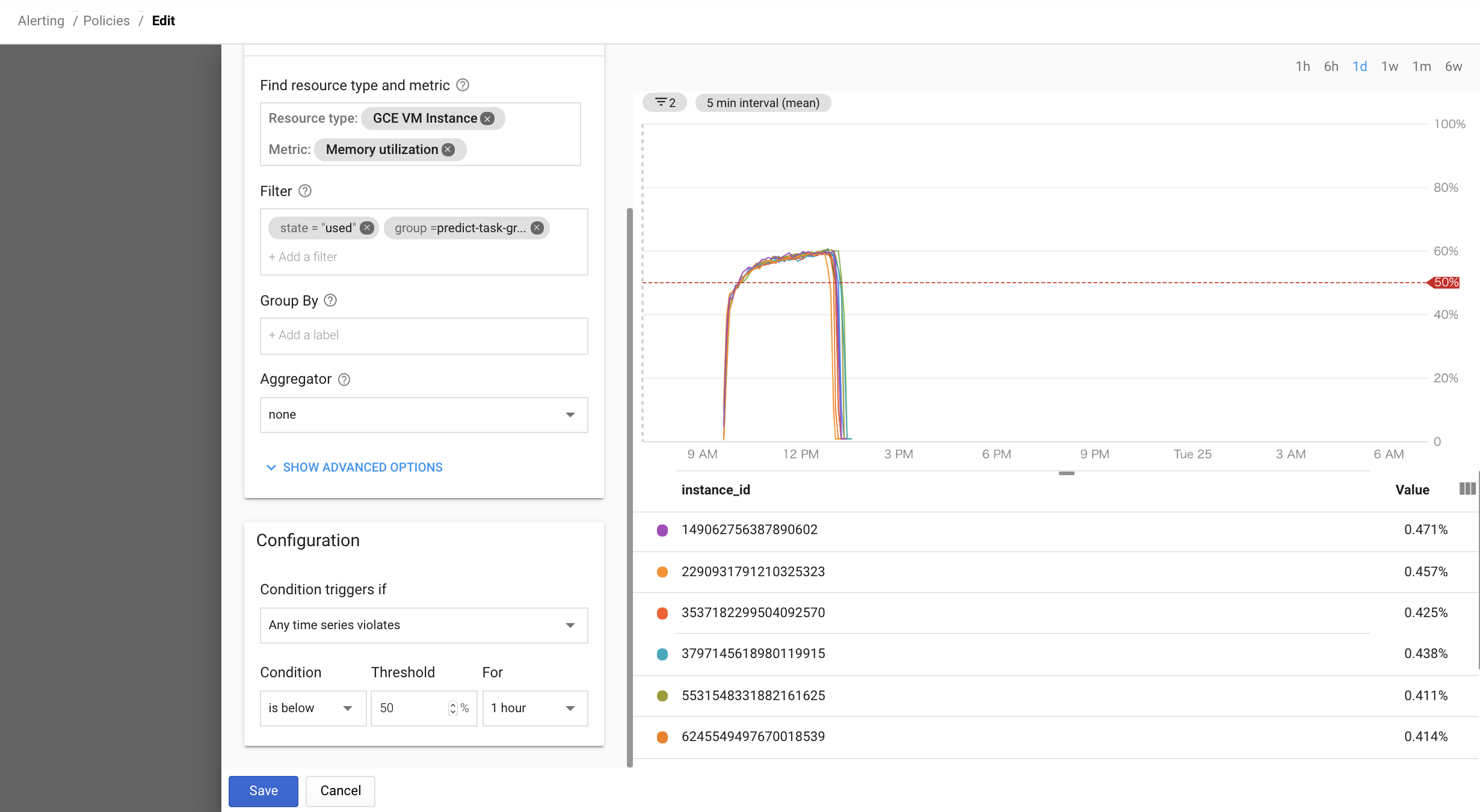
Tips4:定期実行タスクの死活監視設定
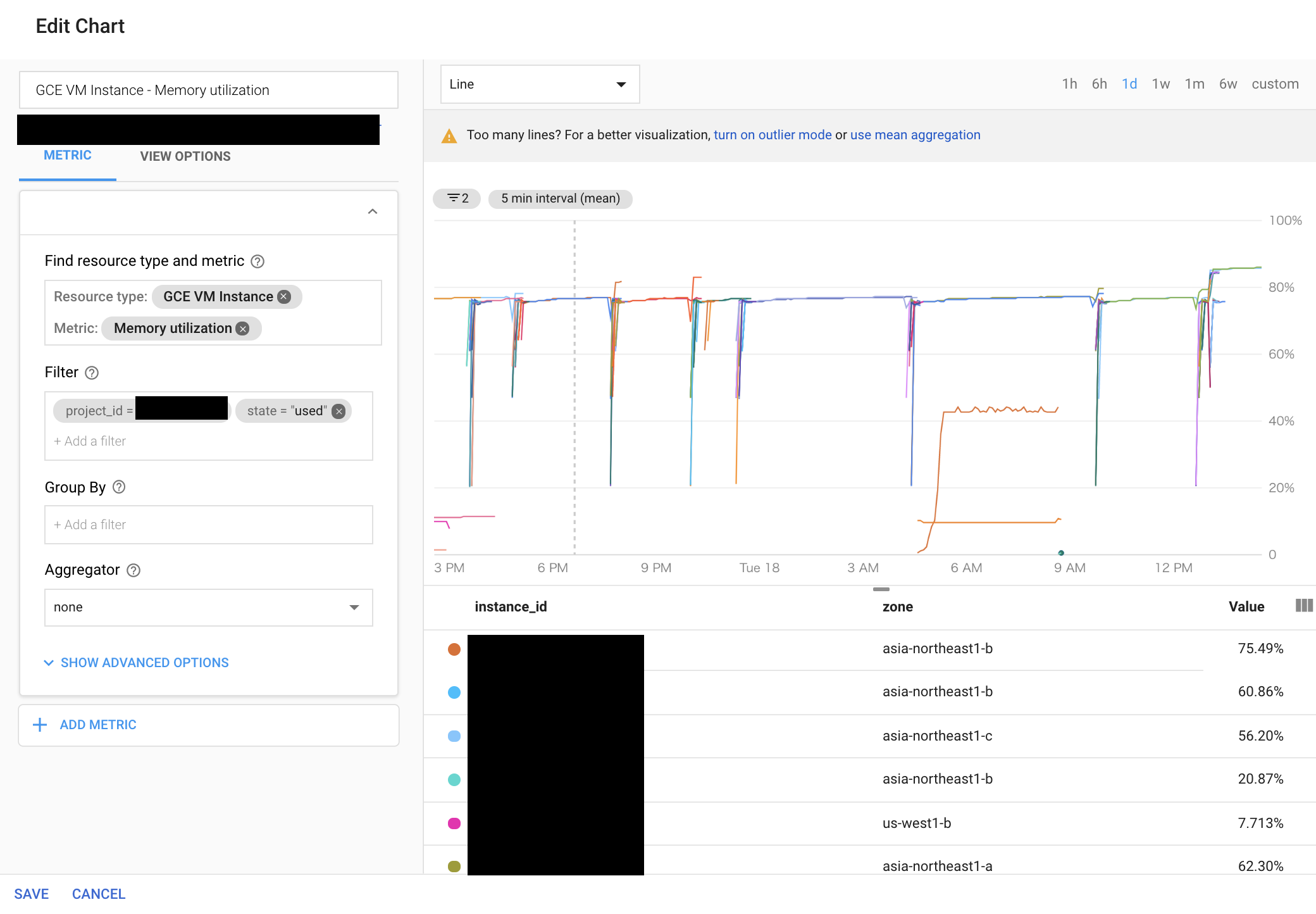
機械学習のタスクが失敗したらマシンリソースの負荷が上がって来ないという考え方で、メモリ使用量の監視を設定する。
(起動シェルの監視だけでも良いかもですが....)
手順
- MetricにMemory utilizationを選択し、Filterにstate="used"を選択し、Conditionにis belowを選択し、任意の閾値と時間を設定する
-
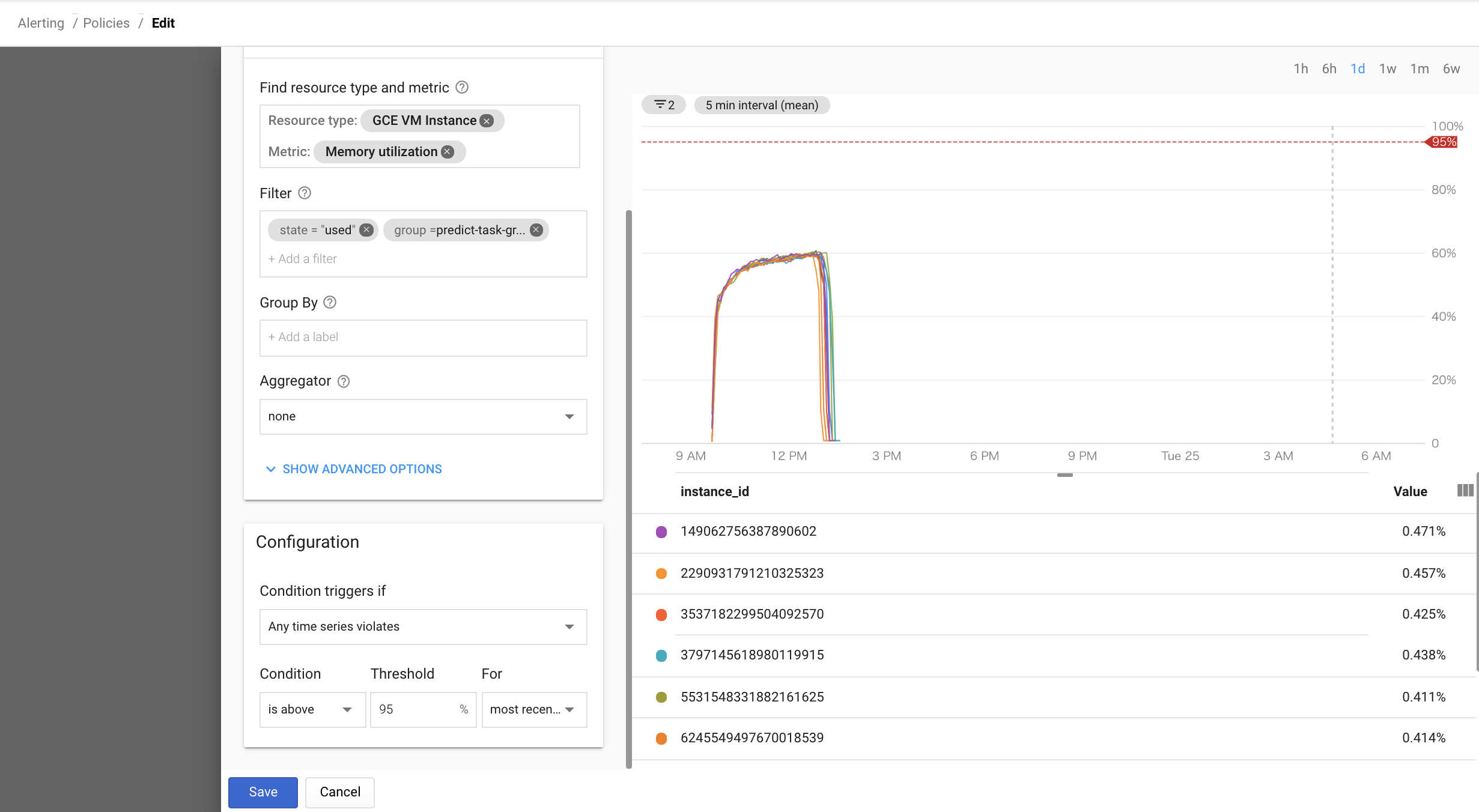
Tips5:サーバーリソース不足の監視設定
機械学習やっていると限界までサーバーリソースを使いこむので、リソースの監視を設定する。
手順
- MetricにMemory utilizationを選択し、Filterにstate="used"を選択し、Conditionにis aboveを選択し、Forにmost recent valueを選択する(メモリが閾値を超えた瞬間にalert)
-
以上、新しい発見があったら追加して行く。