データに携わるなら学んでおきたいデータマネジメントについてまとめました。
誰かの「データマネジメントを学ぶきっかけ」になれば幸いです!
想定読者
-
データ分析をする方(データサイエンティストなど)
-
データ基盤を担当している方(データエンジニアなど)
-
IT部門ではないが仕事でデータ活用を求められている方(事業部の方など)
-
ゼロからデータマネジメントを学びたい方
データマネジメントとは
データマネジメントとは「データを資産として捉え、体系的に価値を引き出すための手法」です。
-
資産なので置き場所を決めます
-
資産なので盗まれたり、なくなったりしないようにします
-
資産がどこからきて、どこへ行くのかを把握します
-
資産の価値が減らないように気を配ります
-
資産を監督する人や、そのルールを決めます
引用:データマネジメントが30分でわかる本 | ゆずたそ, はせりょ, 株式会社風音屋, ゆずたそ | 経営情報システム | Amazon
なぜデータマジメントを学ぶべきなのか
持続可能なデータ活用を促進し、継続的にビジネスの成長を支えるためです。
そのためには 組織横断的に取り組む必要があります。
”データを分析するデータサイエンティスト”や”データを生成している事業部”もデータマネジメントについて一定のリテラシーを持ち、後述する ”データスチュワード”や”データ組織”に協力的な姿勢を示すことで、この組織横断的な取り組みの実現性が高まると考えています。
いまやどの企業もデータ活用をする時代になり、
TJOさんの「データサイエンティストという職業の10年間の変遷を振り返る」のブログでも
これを分析したら何か良いことがあると思う経営者やマネジメント層が増えたということもあるのでしょう。いずれにせよ、様々な就職・転職斡旋サービスに「データサイエンティスト」の職名を冠した求人募集が多く出回るようになったようです。
(中略)
2022年10月現在も、第三次ブームは現在進行中です
とあり、企業のデータ活用意識やデータサイエンティストという職業の認知は一定獲得できているように思います。
しかしIMDが調査した世界デジタル競争力ランキング2022によると「ビッグデータやデータ分析の活用」について、日本は「調査対象63か国中63位」と最下位です。

IMD 世界デジタル競争力ランキング2022 発表に合わせて「日本のデジタル競争力に関する調査」を実施から引用し一部加工
日本もデータの重要性はわかっているはずなのに、他国に比べてデータの活用ができていないという評価をされています。
これは本当に色々な要因があると思いますが、そのうちのひとつとしてPoC死やPoC貧乏という言葉があるように、たとえデータそのものやデータサイエンティストをかき集めて分析の効果を出せたとしても、それに継続性がなく真のデータ活用ができていないことが考えられます。
持続可能なデータ活用を促進するために、まず私のようなデータサイエンティストがデータマネジメントのリテラシーを向上させ、データスチュワードと協力的に働く姿勢を持つことが大切です。
データに関わる人がデータマネジメントに前向きな態度を取ることで、真のデータ活用に向けた組織全体での取り組みに近づくと考えています。
データマネジメントを推進する組織
データ活用を進めるためには、データ基盤を構築しデータを整備するのが不可欠です。
ここではそのデータ基盤を支えたり、企業全体に働きかけてリテラシーを向上させるようなデータマネジメント推進する組織(以降、データ組織)について説明します。
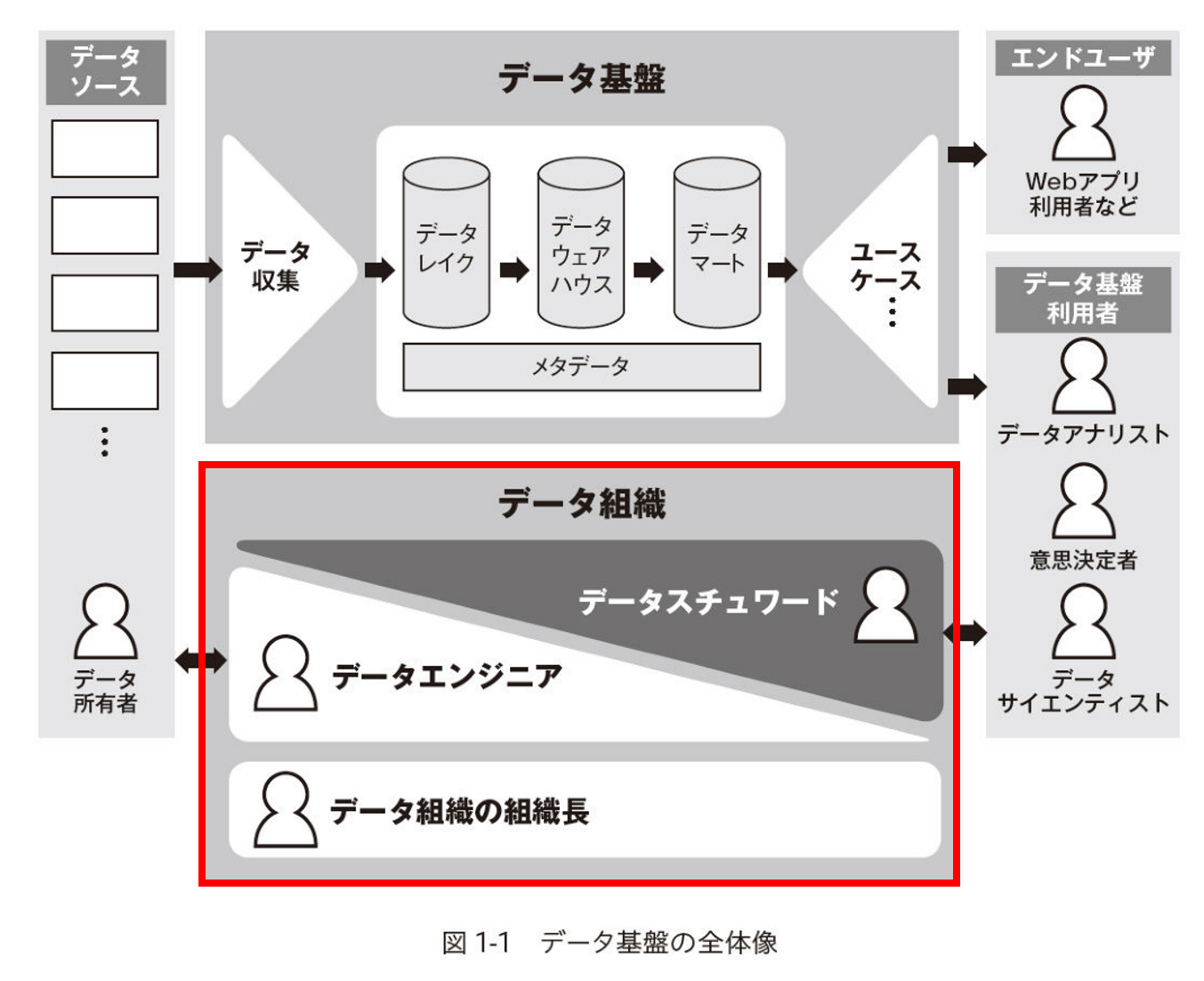
実践的データ基盤への処方箋〜 ビジネス価値創出のためのデータ・システム・ヒトのノウハウから引用し一部加工 (以降、処方箋本と略すことがあります)
データ組織は、組織長・データエンジニア・データスチュワードで構成されます。
| 名称 | 役割 | 詳細 | コメント |
|---|---|---|---|
| 組織長 | プロジェクトマネジメントだけにとどまらず、企業全体のデータリテラシーを向上させ、ガバナンスを強化する | ・データエンジニアやデータスチュワードのマネジメントだけでなく、 企業全体に働きかけて、企業におけるデータ分析文化を醸成したり、 データ活用人材の採用戦略を立案したりする責務がある。 ・データのガバナンス強化やセキュリティ遵守の責務も狙い、 企業全体でインシデントが起きないようにすることや、 インシデント時にリスクを逓減できるような安全管理措置の策定も求められる。 |
組織横断的に進める意味で企業全体というワードが入っていますね。 ここでは処方箋本に沿って組織長と称しましたが、データプロダクトマネージャーのほうが聞き馴染みがある方もいるかもしれません。 |
| データエンジニア | データ基盤の構築と運用をする | ・データ基盤の構築や運用 ・データ収集の担当 ・これらを遂行するためにシステムの知識だけでなく、 データの加工・蓄積スキルなど、通常のITエンジニアよりも広範なスキルが求められる |
3つの中では一番聞き馴染みがあると思います。 |
| データスチュワード | データ基盤を進化させるためのフィードバックサイクルを回す | ・データに責任を持ち、データの整備や利用者のデータ活用をサポートする役割を担う ・また、利用者からのフィードバックをデータ基盤に行き届かせ、 データ基盤を進化させるためのフィードバックサイクルを回す役割 |
“データ生成元”と”データ利用者”の橋渡し役のフロントに立つ方です。 ドキュメントの整理、ファシリテーション、各部署とのコミュニケーションなども担い、エンジニアリング力だけでなくソフトスキルも求められます。 |
参考:処方箋本
データスチュワードには聴き馴染みがないと思いますが、建築×IT|データによってビジネス価値創出するデータスチュワードを募集! - 株式会社アンドパッドのエンジニアリングの採用 - Wantedly など、最近はこのポジションの求人も見かけるため、徐々に認知され始めていると思います。
処方箋本では「データについて最も相談を受けている人がいたら、その人物が事実上のデータスチュワード」とも書かれてり、肩書に関わらず知らないうちにその役割を担っている方もいるのではないでしょうか。
ただし、このデータ組織内の呼び名や担当領域は企業によって異なると思います。
例えば日本経済新聞社、バンダイナムコネクサス社、メルカリ社(メルペイ社)などは”データマネージャー”の名称で”組織長”や”データスチュワード”などの役割を募集しており、その役割も「他部署との折衝」や「企業全体のガバナンス」にフォーカスしている内容もあれば、「分析のための中間データ作成」まで募集要項に入っている場合もあります。
いずれにせよデータ組織は「企業全体に働きかけデータ活用を促進するための基盤構築や企業全体のリテラシー向上を図る」という役割を持ちます。
データソースとデータ基盤
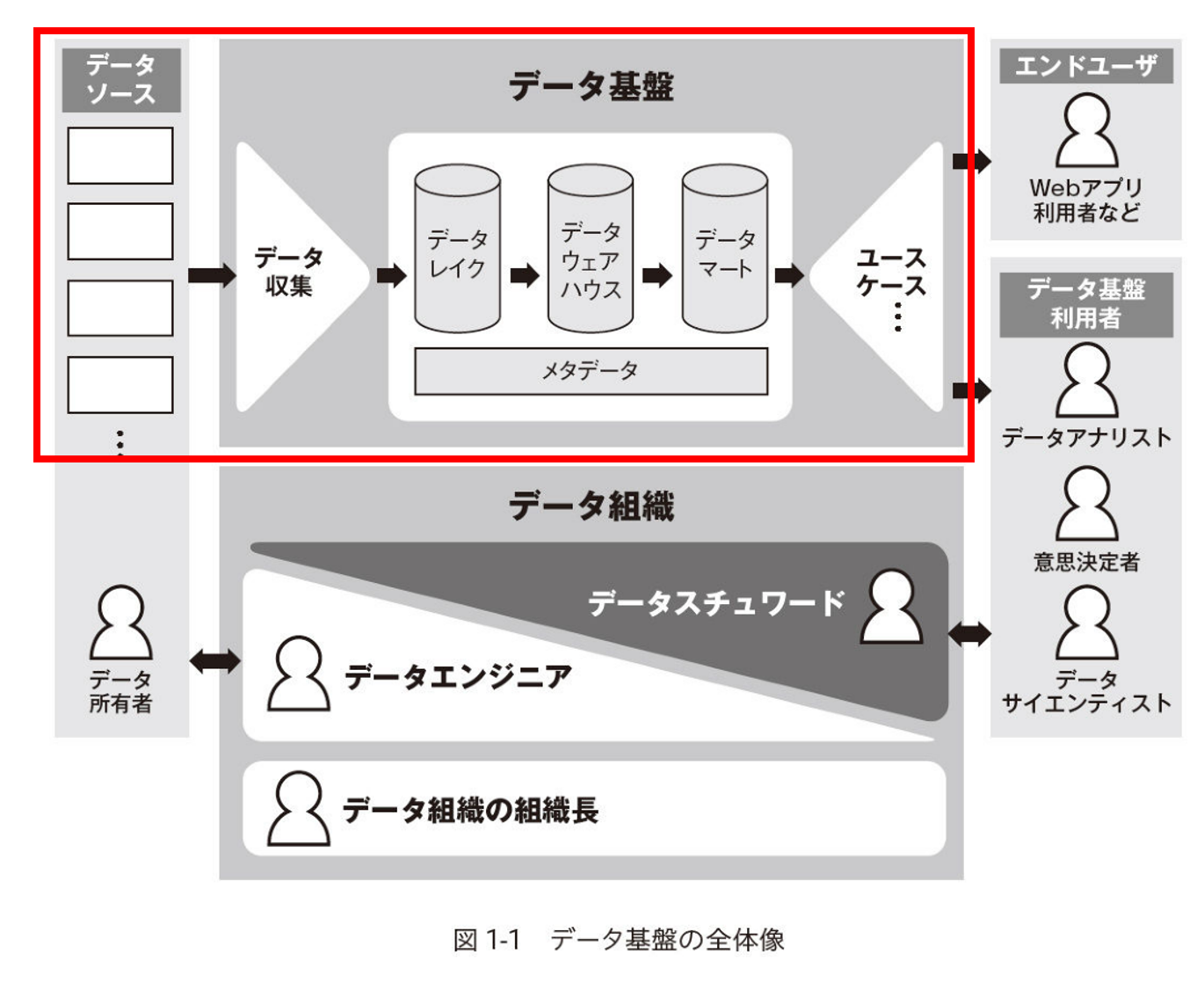
処方箋本から引用し一部加工
ここではデータが生成されてから活用されるまでの流れやデータソースとデータ基盤について解説します。
| 名称 | 説明 | 具体テーブル例 | コメント |
|---|---|---|---|
| データソース |
オリジナルのデータのこと もしくはそのデータの発生源 データは様々なプラットフォームや部署に散らばっている |
・会員マスタ ・店舗購買ログ ・ECサイト購買ログ ・アクセスログ など |
データソースで品質を担保することが重要です。 データを適切に収集できていなかったり、誤ったデータが含まれている場合、正確な分析ができなくなってしまいます。 |
| データレイク |
データソースのデータをそのままコピーしたデータ データソースからこのデータレイク一カ所に集約する 様々なプラットフォームや部署から1カ所にデータが集まることで、組織横断的な分析や意思決定が可能になる。 |
・会員マスタ ・店舗購買ログ ・ECサイト購買ログ ・アクセスログ など |
加工や結合をしていないためデータソースのテーブルとは1対1の関係にあります。 手を加えていないデータソースのコピーであることが重要です。 初期段階で便利な形に加工しても、分析が進むにつれてニーズが変わり、結局データソースからデータをコピーする羽目になります。 例外的に個人情報のみマスキングします。 |
| データウェアハウス(DWH) |
加工・結合したデータを置く場所、共通指標となるデータ 分析者はこのデータをもとにデータマートを作成する。 |
・会員マスタや購買ログ(実装時のテスト用のダミーデータなどは除外済) ・店舗購買ログとECサイト購買ログから計算した売上データ |
・DWHで共通指標を集計することで、部署横断でのデータ活用を促進します。 例えば「売上」といっても、消費税を含むか、割引はどこで差し引くか、などを各部署で独自に判断して集計すると、部署ごとに売上の意味が異なり、横断的な意思決定ができなくなってしまいます。 ・処方箋本には >「データウェアハウス層に置くべきか」「データマート層に置くべきか」を判断できないときは、時期尚早なのでデータマート層に置きましょう とあります。 |
| データマート | 加工・結合したデータを置く場所 特定用途向けのデータであり、ユースケースと1対1になる |
売上ダッシュボード用テーブル アドホックな分析用の中間テーブル |
・ユースケースと1対1であるため影響範囲を制限できます。 ・データマートの肥大化を防ぐために、役目を終えたデータマートは作成者が責任を持って消しましょう (処方箋本では「データスチュワードが旗振り役になるとよいでしょう」と書かれています) |
※ 書籍や開発者によって用語の使い方が異なりますので、意味が伝わるように、ご自身の所属組織で使われている用語に読み替えていただくことをお勧めします。
昨今はデータレイクハウスやデータ仮想化といった概念もあるそうです。
このようにデータレイクを作り、データが一カ所に集まることで組織横断的な分析や意思決定が可能になります。
しかし、それを継続させるためにはデータマネジメントに組織横断で前向きに取り組むべきだと考えています。
例えば
・データの品質について、上流の問題を下流でカバーしても労力が余計にかかるうえに問題の原因は解消されません。
下流(データ利用者)から上流(データ生成者)に対してフィードバックし、データ品質の担保することが重要です。
・役目を終えたデータマートを放置したら、データマートが肥大化し、無秩序になります。
処方箋本ではこの管理を「データマートはデータスチュワードが旗振り役になるとよいでしょう」とあります。
理想的には「ログを見て一定期間使われなかったら削除する」とかシステマティックに解決するのかと思いますが、実際そこまで手が回るのには時間がかかると思います。
なのでデータ利用者も協力的な姿勢を持ち、役目を終えたデータマートは「最も状況を理解しているはずのデータマートの作成者」が責任を持って消すと比較的低コストで肥大化を防止できるのではないでしょうか。
と、大なり小なりありますが、組織横断的に協力していくことでデータマネジメントがうまく回るようになると考えています。
やはりデータスチュワードがガバナンスを効かせるにしても、受け手に一定のリテラシーと当事者意識があって初めてうまく回るように思います。
また、処方箋本にて、実務で迷いそうなときの解が明記されていて参考になったので紹介させてください。
「データウェアハウス層に置くべきか」「データマート層に置くべきか」を判断できないときは、時期尚早なのでデータマート層に置きましょう
データウェアハウス層の設計に着手するのは、データマート層が使われるようになったあとにしましょう。
「データソース→データレイク」「ユースケース→データマート」のように先に両端を充実させてください。最初にデータマート層をつくるときはデータレイク層を直接参照します。データ活用施策を成功させて、「これこそが共通指標だ」と言えるのものが明らかになってから、データウェアハウス層をつくりましょう。
最初から完成形をつくろうとするのではなく、段階的にシステムを進化させましょう。
メタデータ
メタとは「超~」「高次~」といった一段マクロな視点から見た概念です。
つまりメタデータとは「データを説明するためのデータ」です。
例えば
・データ定義書(各カラムの名称、型など)
・データの活用方法、ユースケース
・品質情報やセキュリティ情報
などが挙げられます。
メタデータなしではデータの意味がわからず、正しく分析に活用することができません。

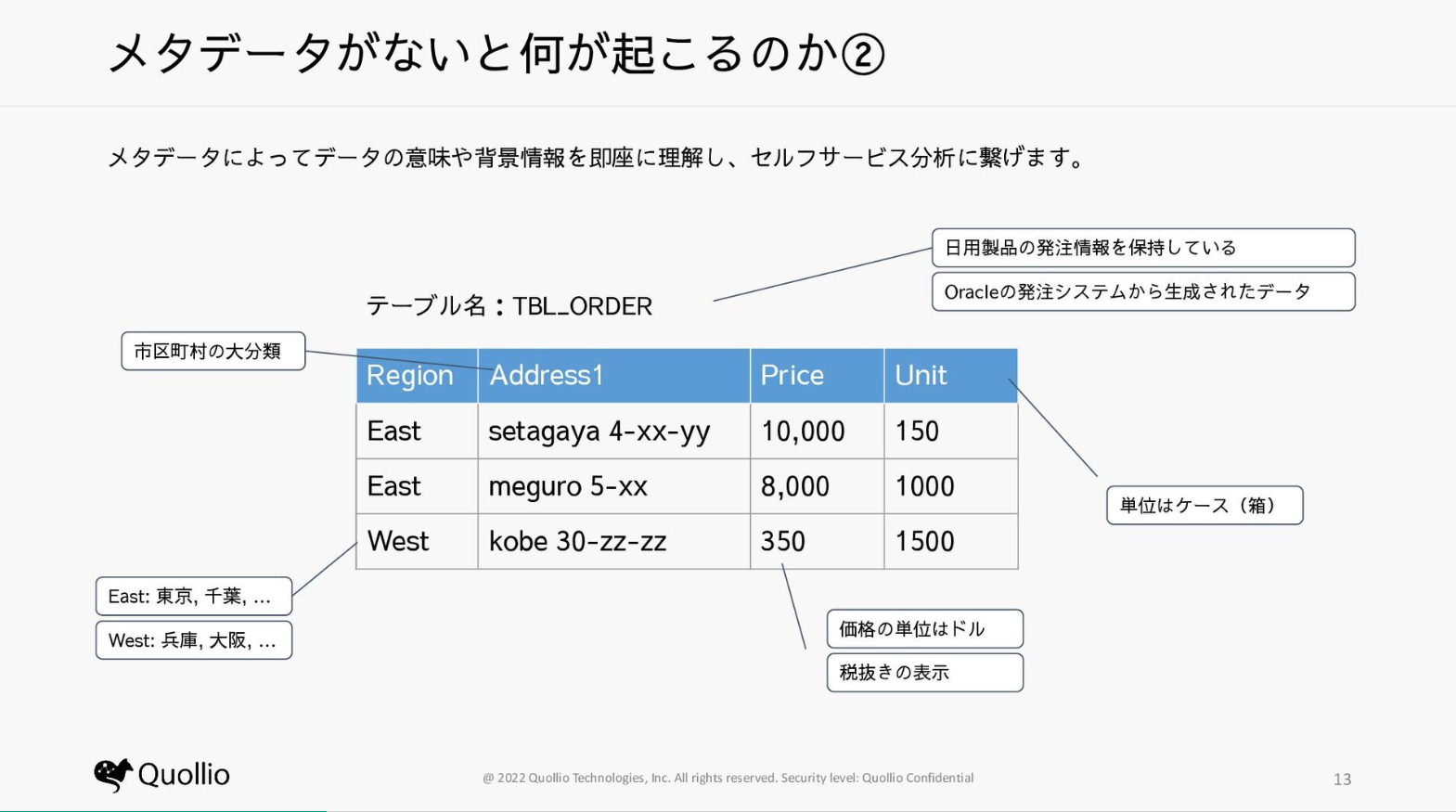
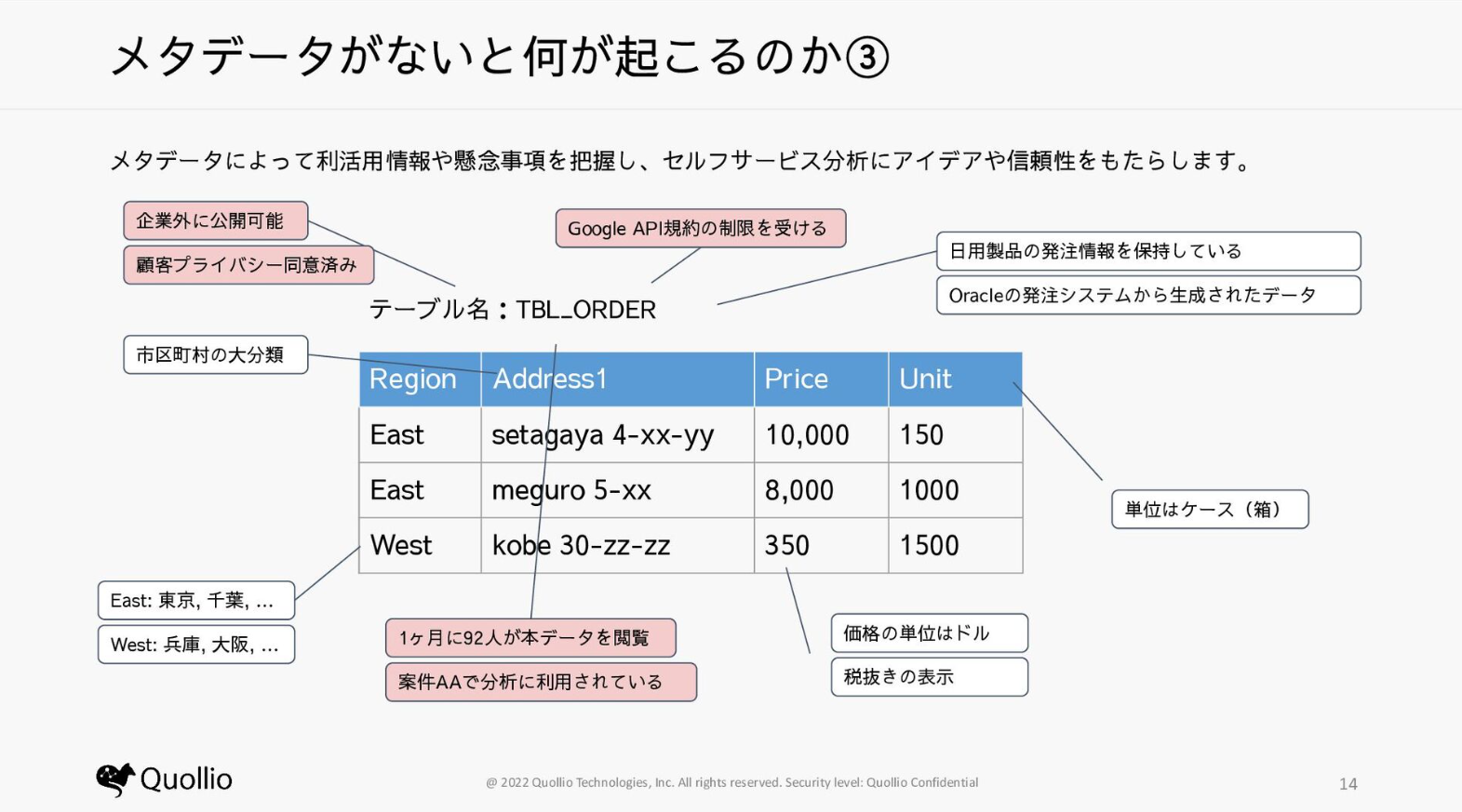
メタデータが管理されていることで、これらを調査するコストが削減されます。
さらに分析するとき以外にもメタデータが活躍します。
例えば、データ基盤でトラブルが発生した際に、「誰にどのデータがどれくらい参照されているか」というメタデータがあれば、対象者にアナウンスし、優先度に応じた対応が可能になります。
また、データカタログと呼ばれるメタデータを管理するシステムもあります。

このメタデータの管理にはデータソースに最も詳しい、データ生成者を巻き込む必要があります。
しかし、データ生成者にはメタデータを管理するインセンティブを感じにくいため、メタデータの運用を自動化する、あるいは業務フローに組み込むといったことが重要です。
しかし業務フローに組み込むにも現場の人からしたら今までのやり方が変わるため、一定の抵抗感を示すのが当然の反応だと思います。
やはりここも「継続的にデータ活用するためのデータマネジメント」を「組織横断的に取り組む必要がある」という壁がひとつあると考えています。
また、このメタデータの整理をデータスチュワード単体で遂行するのは難しいと考えており、データサイエンティストをはじめとしたデータ利用者とのコミュニケーションが必要不可欠だと考えています。
データスチュワード側からはデータ利用者がどの情報をどの粒度で欲しいかはわからないですし、
かといってデータ利用者が過剰品質を求めるのはデータスチュワードの工数を考えると現実的ではありません。
データスチュワードとデータ利用者の双方が納得する落としどころを見つけるにも、当事者にデータマネジメントへの一定のリテラシーが必要だと考えています。
そしてメタデータを充実させるために 単にデータスチュワードだけが奮闘するのではなく、「知りたい内容にアクセスしやすい」という仕組みや「調べてもわからないときにデータスチュワードへ相談できる」という関係性が土台が必要です。そのうえでデータスチュワードが旗振り役となって協力して徐々にメタデータを充実させていくのがよいと考えています。
なぜデータマジメントを学ぶべきなのか(再掲)
持続可能なデータ活用を促進し、継続的にビジネスの成長を支えるためです。
そのためには 組織横断的に取り組む必要があります。
”データを分析するデータサイエンティスト”や”データを生成している事業部”もデータマネジメントについて一定のリテラシーを持ち、 ”データスチュワード”や”データ組織”に協力的な姿勢を示すことで、この組織横断的な取り組みの実現性が高まると考えています。
この記事を書いた思い
データスチュワードがガバナンスを効かせてようしても、特に現場レイヤーには「作業が増えてめんどうだ」「オペレーションが変わってやりづらい」などネガティブな受け取り方をするのが普通だと思います。
だからこそ私のような「データサイエンティストなどのデータ利用側」がデータマネジメントに理解を示し、データスチュワードに寄り添い、組織横断的なデータ活動の推進に貢献するのが重要だと考えています。
また、データマネジメントの価値を発信していくことで読んでくださった方のデータ活用に貢献できたら幸いです
今のプロジェクトにデータスチュワードがいないというケースもあると思いますが、実質データスチュワードを担ってる方がいるはずです。ぜひその方に寄り添いましょう。私もそうします!
最後に
少しでもデータマネジメントに興味が湧いたらぜひ関連書籍を1冊手にとってみてください!
オススメは実践的データ基盤への処方箋〜 ビジネス価値創出のためのデータ・システム・ヒトのノウハウ です。
誰かの「データマネジメントを学ぶきっかけ」になれば幸いです!
参考
・実践的データ基盤への処方箋〜 ビジネス価値創出のためのデータ・システム・ヒトのノウハウ
・データマネジメントが30分でわかる本
・10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く
・【Quollio】メタデータ・マネジメント入門
・DataOpsとは何か #dataops - 下町柚子黄昏記 by @yuzutas0